

A explosão do Big Data nos últimos anos tem criado uma série de novas tecnologias de armazenamento e processamento de dados à sua volta. Plataformas como NoSQL, Yarn, e Hadoop agora são termos familiares dentro desse ecossistema crescente. No entanto, é provável que muitos de vocês não tenham ouvido falar de “triplestores”. Esse é um novo tipo de banco de dados que tem sido utilizado desde o início dos anos 2000, mas que tem crescido em popularidade somente nos últimos anos, devido ao Big Data. Em sua forma mais simples de definição, um triplestore é “um banco de dados construído propositadamente para o armazenamento e recuperação de triplos”. Vamos descrever o que é um triplo a seguir.
Um triplo é simplesmente uma entidade única de dados composta por três elementos serializados: <sujeito, predicado e objeto> que fazem parte de um registro.

Imagine uma sequência de dados dentro de uma rede social, como Jack é amigo de Jill”. Essa informação pode ser descrita da seguinte forma:
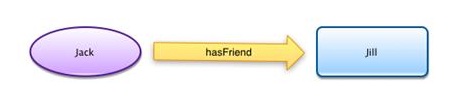
Ao longo do tempo, reunindo essas várias declarações, construímos uma teia de fatos, que é a tecnologia que está por trás do que tem sido chamado de web semântica.
A web semântica é, basicamente, um esforço de colaboração para tornar a Internet “mais inteligente” e mais apta para consumo humano; em outras palavras, a web semântica traz informações personalizadas para o usuário ao invés de fazer com que o usuário “saia” e procure por uma agulha no palheiro Internet afora. É a diferença entre a web de 1999 e a web de hoje.
A vantagem dos triplos é que eles fornecem uma maneira simples e flexível de modelagem de dados que é muito parecida com a forma como o cérebro humano funciona. Em vez de modelos relacionais estruturados, ou mesmo pares de chave/valor no modelo NoSQL, os triplos têm uma estrutura semântica que pode facilmente representar conexões entre os dados estruturados e o texto de fluxo livre. Como uma fonte bem afirma: “uma vez que esse modelo é tão simples, ele permite dados estruturados, semiestruturados e dados não estruturados para serem misturados, expostos e compartilhados entre diferentes aplicativos”. Por causa da estrutura semântica do sujeito, predicado e objeto incorporado nos triplos, os bancos de dados triplestore são exclusivos frente a outros bancos de dados em sua capacidade de interpretar os dados por meio de raciocínio lógico e pela descoberta de novos fatos e relações entre os dados.
O gráfico seguinte descreve os conceitos básicos aqui. Por exemplo, aqui está um triplo da pessoa chamada Margaret Attwood:
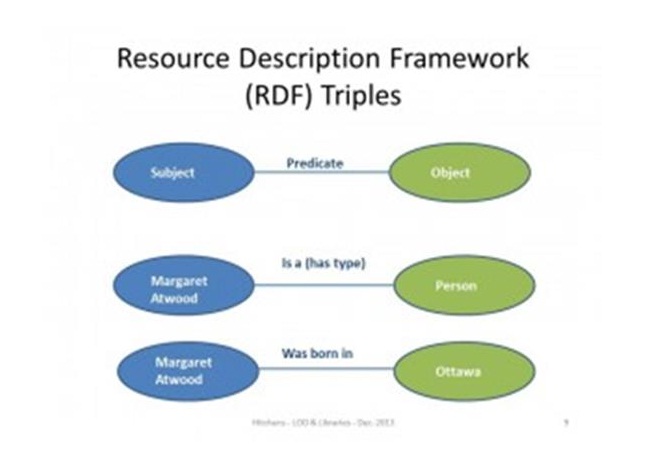
E aqui está a mesma informação em um formato gráfico (em oposição a um modelo relacional):

Agora, a coisa mais agradável sobre os triplos é que, na enorme “teia de informações”, novas relações, conexões e descobertas podem ser feitas facilmente, o que de outra forma seria impossível com modelos relacionais. Em outras palavras, você pode descobrir que um objeto na página de Margaret Attwood pode ser um assunto na página de Bruce Cockburn. Por meio desses dados triplestore, descobrimos que Margaret e Bruce têm uma conexão também com Ottawa.
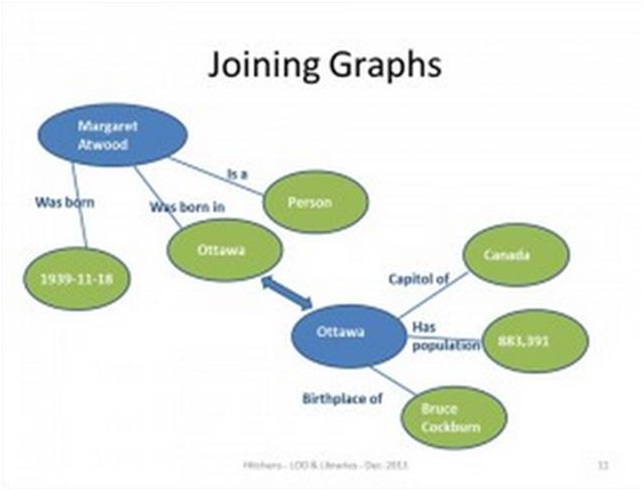
Muito mais poderia ser dito aqui, mas espero que você comece a ter uma ideia básica de como triplos e triplestores fornecem um vislumbre do futuro do armazenamento de dados na web semântica. Essa tecnologia tem o potencial de revolucionar a forma como nos conectamos e interagimos com a informação.
Olhando para o futuro da Internet, vemos um novo paradigma na gestão de informações e banco de dados. Por exemplo, se você não tiver feito isso, vale a pena dar uma olhada no projeto Web Física do Google, que representa uma nova forma fundamental de interagir com informações e objetos pela Internet. De acordo com esse projeto, o futuro da Internet provavelmente será baseado em URL, e não em aplicativos. E se esse for realmente o caso, haverá a necessidade de novas maneiras de gerenciar e armazenar grandes quantidades de dados de forma mais rápida e eficiente. Triplestores representam uma mudança de conceito nessa direção, no sentido de uma forma de modelagem de dados mais sintonizada com a estrutura semântica da linguagem e com a forma como o cérebro humano funciona.
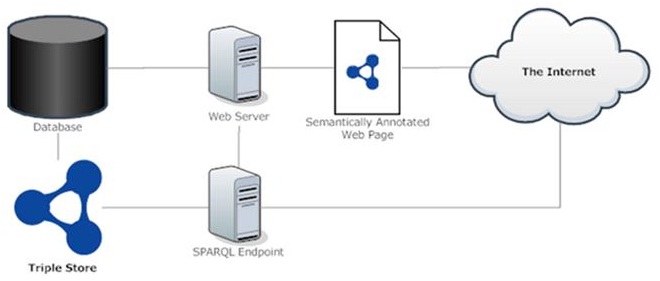
Com os mais recentes avanços em Big Data, Internet das Coisas, web semântica e Web Física, há sinais de um futuro que já está batendo à nossa porta. Agora é a hora de começar a se familiarizar com a nova geração de tecnologias Web 3.0. Coloque “triplestores” na sua agenda de pesquisa hoje, portanto, encontre maneiras de começar a alavancar essa tecnologia emergente e potencialmente perturbadora.
***
Hovhannes Avoyan faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://blog.monitis.com/2015/02/03/why-triplestores-are-the-next-big-thing-for-big-data/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?