

Pouca gente na indústria de computação não deve ter se deparado com o termo “Big Data” e “Hadoop”. Essas são algumas das palavras da moda que surgem com frequência nos dias de hoje. Apesar de às vezes superestimado, trata-se de algo muito importante para todas as empresas de análises e os responsáveis por políticas. Vejamos então sobre o que é esse buzz todo.
Desde o princípio da Internet, quantidades massivas de dados de usuários têm sido geradas. Particularmente nos últimos anos, mídias sociais como Facebook, Twitter e blogs criaram quantidades obscenas de dados de usuários. De acordo com o Gartner, Big Data são grandes quantidades de dados, em alta velocidade, gerados por uma multiplicidade de fontes. Por serem criados de forma quase aleatória, esses dados não possuem estrutura. Essas informações podem ser analisadas para ajudar em tomadas de decisões mais eficientes e inteligentes. Por causa dessas características, a manipulação e o processamento de Big Data necessita de ferramentas e técnicas especiais. É aqui que entra o Hadoop.
O Hadoop é uma implementação de código aberto do paradigma de programação Map-Reduce. Map-Reduce é um paradigma de programação introduzido pelo Google para processar e analisar grandes conjuntos de dados. Todos esses programas que são desenvolvidos nesse paradigma realizam o processamento paralelo de conjuntos de dados e podem, portanto, ser executados em servidores sem muito esforço. A razão para a escalabilidade desse paradigma é a natureza intrinsecamente distribuída do funcionamento da solução. Uma grande tarefa é dividida em várias tarefas pequenas que são então executadas em paralelo em máquinas diferentes e então combinadas para chegar à solução da tarefa maior que deu início a tudo. Os exemplos de uso do Hadoop são analisar padrões de usuários em sites de e-commerce e sugerir novos produtos que eles possam comprar.
Isso é tradicionalmente chamado de sistema de recomendações e pode ser encontrado em todos os principais sites de e-commerce. Ele pode ser utilizado também para processar grandes grafos como o Facebook etc. A razão pela qual o Hadoop simplificou o processamento paralelo se dá pelo fato de o desenvolvedor não precisar se preocupar com problemas relativos ao processamento em paralelo. Ele pode escrever apenas as funções de como quer que os dados sejam processados.
Componentes do Apache Hadoop
O framework do Hadoop é formado por dois componentes principais: armazenamento e processamento. O primeiro é o HDFS (Hadoop Distributed File System), que manipula o armazenamento de dados entre todas as máquinas na qual o cluster do Hadoop está sendo executado. O segundo, o Map-Reduce, manipula a parte do processamento do framework. Vamos olhar as duas individualmente.
HDFS (Hadoop Distributed File System)
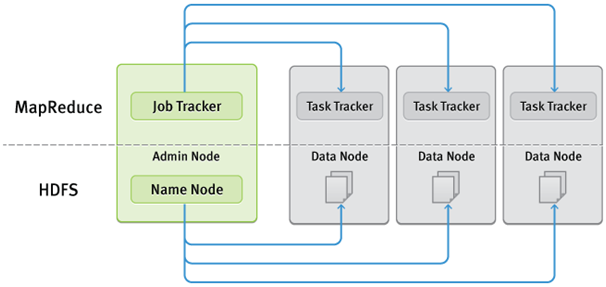
O HDFS é um sistema de arquivos escalonável e distribuído, cujo desenho é baseado fortemente no GFS (Google File System), que também é um sistema de arquivo distribuído. Sistemas de arquivo distribuídos são necessários, uma vez que os dados se tornem grandes demais para serem armazenados em apenas uma máquina. Por conta disso, toda a complexidade e as incertezas provenientes do ambiente de rede entram em cena, o que faz com que sistemas de arquivos de rede sejam mais complexos do que sistemas de arquivos comuns. O HDFS armazena todos os arquivos em blocos. O tamanho do bloco padrão é 64Mb. Todos os arquivos no HDFS possuem múltiplas réplicas, o que auxilia o processamento em paralelo. Os clusters HDFS possuem dois tipos de nós – primeiro um namenode, que é um master, e múltiplos datanodes, que são nós slave. Fora esses dois, também é possível ter namenodes secundários.
Namenode: administra o namespace do sistema de arquivos. Ele gerencia todos os arquivos e diretórios. Namenodes possuem o mapeamento entre arquivos e os blocos nos quais estes estão armazenados. Todos os arquivos são acessados usando esses namenodes e datanodes.
Datanode: armazena os dados em forma de blocos. Datanodes se reportam a namenodes sobre os arquivos que possuem armazenados para que o namenode esteja ciente e os dados possam ser processados. Namenode é talvez o principal ponto crucial de falha do sistema, sem o qual os dados não podem ser acessados.
Namenodes secundários: esse node é responsável por checar a informação do namenode. No caso de falha, podemos usar esse nó para reiniciar o sistema.
Map-Reduce
Map-Reduce é um paradigma de programação em que cada tarefa é especificada em termos de funções de mapeamento e redução. Ambas as tarefas rodam paralelamente no cluster. O armazenamento necessário para essa funcionalidade é fornecido pelo HDFS. A seguir estão os principais componentes do Map-Reduce.
Job Tracker: tarefas de Map-Reduce são submetidas ao Job Tracker. Ele precisa falar com o Namenode para conseguir os dados. O Job Tracker submete a tarefa para os nós task trackers. Esses task tracker precisam se reportar ao Job Tracker em intervalos regulares, especificando que estão “vivos” e efetuando suas tarefas. Se o task tracker não se reportar a eles, então o nó é considerado “morto” e seu trabalho é redesignado para outro task tracker. O Job tracker é novamente um ponto crucial de falha. Se o Job Tracker falhar, não poderemos rastrear as tarefas.
Task Tracker: o Task Tracker aceita as tarefas to Job Tracker. Essas tarefas são tanto de map, reduce ou ambas (shuffle). O Task Tracker cria um processo JVM separado para cada tarefa a fim de se certificar de que uma falha no processo não resulte em uma falha de Task Tracker. Task trackers também se reportam ao Job Tracker continuamente para que este possa manter o registro de tarefas bem ou mal sucedidas.
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Texto original da equipe Monitis, liderada por Hovhannes Avoyan, disponível em http://blog.monitis.com/index.php/2013/12/19/big-data-and-hadoop-whats-it-all-about/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?