

Existem momentos do dia a dia de quem usa um banco de dados que é necessário executar operações simples que acabam consumindo muitos recursos do servidor. Em casos mais críticos, pode acontecer que tais operações nem possam ser executadas.
Recentemente passei por situações assim num projeto que participei. Dependendo da operação (CRUD) e do servidor envolvido, meus scripts SQL geravam erros relacionados a um determinado limite que tinha sido excedido, como por exemplo tempo de execução. E a solução sempre era “particionar” a declaração para gerar lotes menores.
Neste artigo, apresento um modo simples de usar a própria linguagem SQL para gerar múltiplos scripts SQL que tratam lotes menores.
O Problema
No exemplo que comentei acima, me pediram para verificar os registros referentes a cerca de 30 mil transações que precisavam ser validadas em dois ambientes diferentes.
Para isso, eu havia recebido um arquivo CSV com a lista de chaves que deveria buscar. Portanto eu precisava criar uma consulta SQL bem simples, como mostra o quadro abaixo.

Executei a consulta no primeiro ambiente com sucesso. Mas, para minha surpresa, a coisa foi bem diferente no segundo ambiente, que apresentou um erro de “timeout”.
Avaliando a documentação, entendi que eu só poderia gerar consultas que considerassem uma lista muito pequena de chaves. Para este exemplo, vamos considerar o limite 100 chaves por lista.
Em poucas palavras: meu script precisaria ser quebrado em pelo menos 300 consultas distintas.
Particionando a Lista de Chaves
Evidente que é muito arriscado gerar manualmente centenas de scripts, pois a chance de erro é muito alta. Além disso, um processo manual tomaria um tempo enorme para construir centenas scripts.
Por isso decidi automatizar o processo. É verdade que eu tinha vários modos de abordar o problema. Na minha opinião, a vantagem de se usar consultas separadas é que isso me dá mais controle sobre a execução do processo. No caso de um erro execução, por exemplo, eu poderia identificar facilmente o lote que causou o problema.
Bastava então criar um procedimento para geração automática desses scripts. Isso não é tão difícil considerando que os scripts serão exatamente iguais, com exceção da lista de chaves pesquisadas (veja este quadro).

A seguir, apresento os detalhes desse processo.
1º Passo – Carregando a lista de chaves
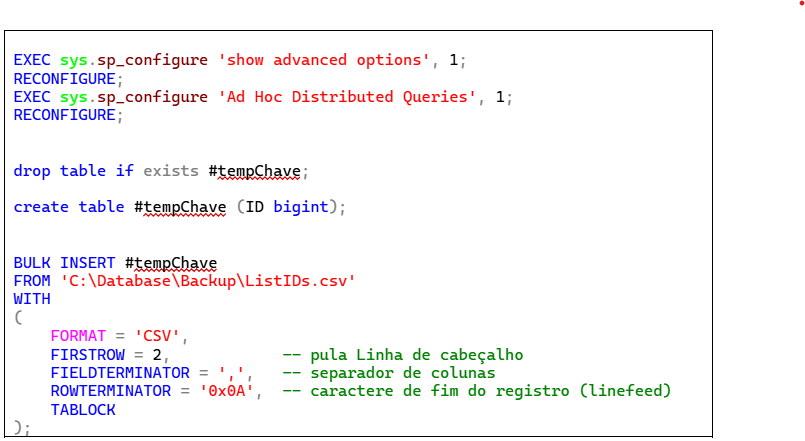
Entre tantas outras opções, eu usei o comando BULK INSERT para carregar o arquivo CSV que continha as chaves.
Esta operação tem como pré-requisito a configuração de dois parâmetros globais de operação do servidor SQL, que são executados no início da operação. Em seguida criei uma tabela temporária, já que este procedimento será executado apenas uma vez. Finalmente, carreguei os dados do arquivo CSV para a tabela temporária, como se vê a seguir.
2º Passo – Criando Listas com “N” Chaves
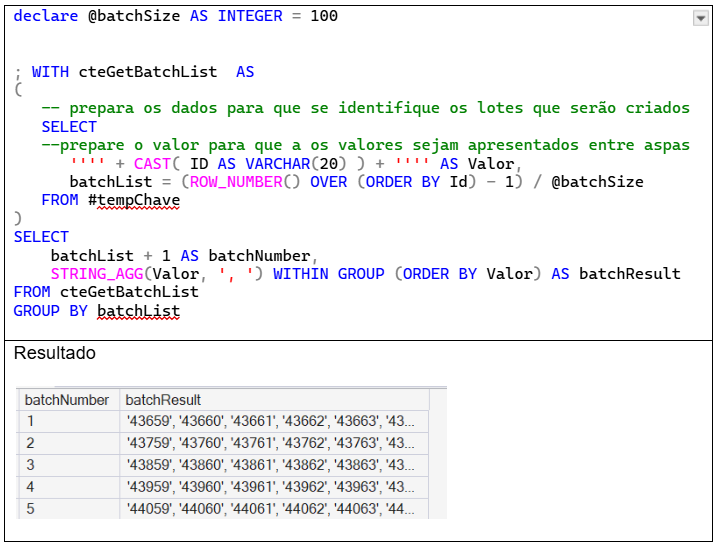
Para gerar a lista de chaves consideradas em cada uma das consultas, a primeira preocupação é identificar a qual “lote” pertence a chave que está sendo tratada. Eu usei a cláusula OVER() e função ROW_NUMBER() para tratar este caso.
Conhecendo a que lote pertence a chave, usei a função STRING_AGG para concatenar as 100 chaves numa única cadeia de caracteres.
O quadro a seguir mostra o script para gerar a lista de chaves que será usada como filtro em cada um dos lotes e uma amostra do resultado obtido.
3º Passo – Criando as Declarações SQL
Por uma questão de didática, incluo aqui um passo intermediário para explicar a construção das declarações SQL que serão usadas.
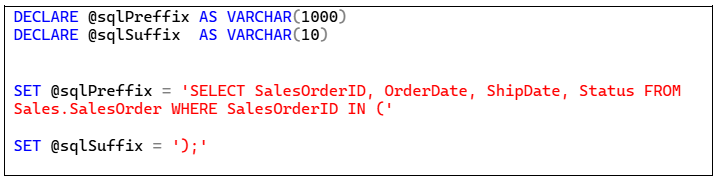
Para isso, eu adaptei o script apresentado no quadro anterior, criando duas variáveis que informam os caracteres que devem vir antes e depois da lista de chaves de maneira a criar uma declaração SQL válida. O próximo mostra estas variáveis.
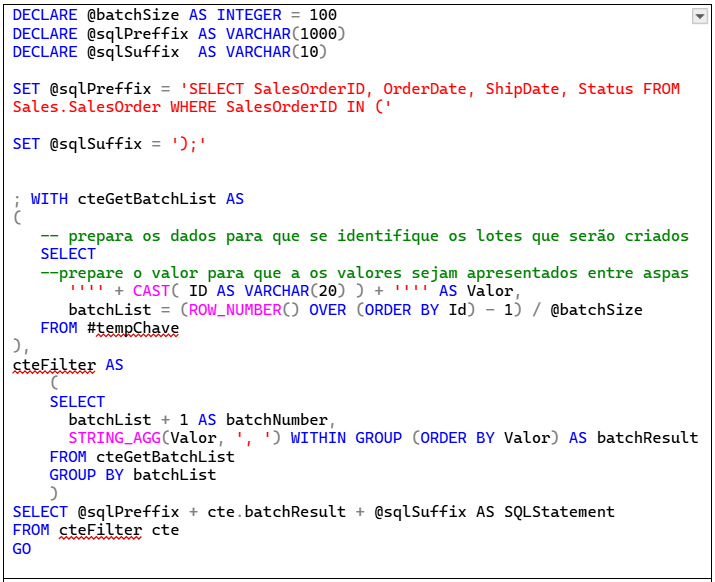
Na sequência do script, transformei o segundo SELECT numa segunda CTE e, finalmente, adicionei outro SELECT para construir a declaração que será executada em cada lote.
Assim chegamos na primeira versão das declarações SQL particionadas. O quadro a seguir mostra o script completo do gerador de declarações SQL particionadas e o resultado obtido.
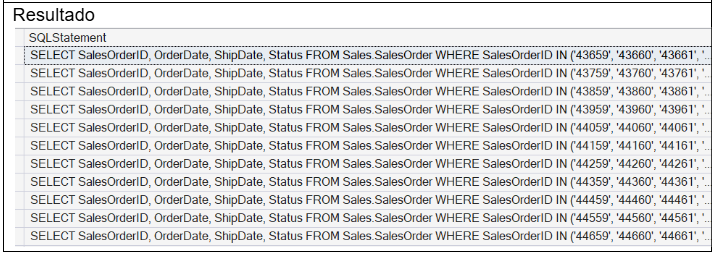
4º Passo – Coletando os Resultados das Consultas
Já temos os scripts particionados prontos para uso, mas a verdade é que eles ainda não são bons o suficiente, porque eu teria que coletar os resultados de 300 consultas. Esse é um novo e enorme gargalo para concluir a operação.
O que fazer?
Uma maneira simples de agrupar estes dados é gravando o resultado de cada lote em uma tabela temporária. Ou seja, o gerador passa a construir declarações SQL do tipo INSERT.
Ao final da operação, leio e copio todas as declarações e executo numa outra sessão.
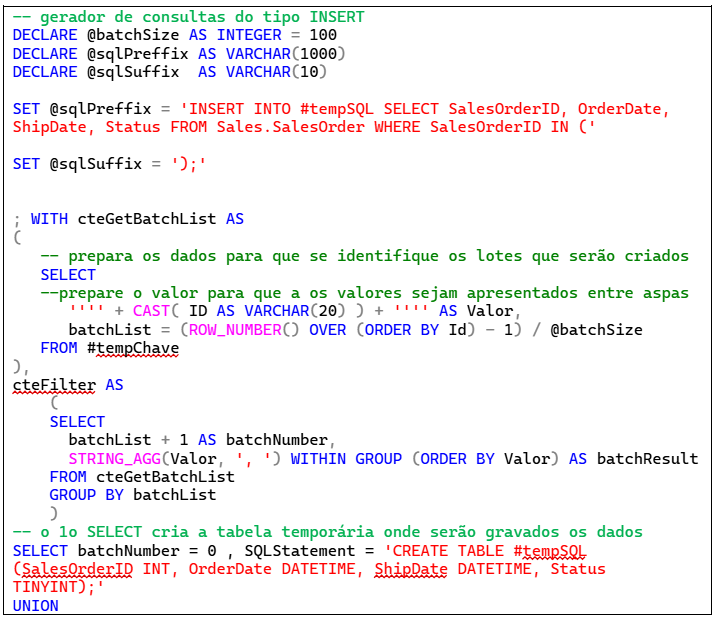
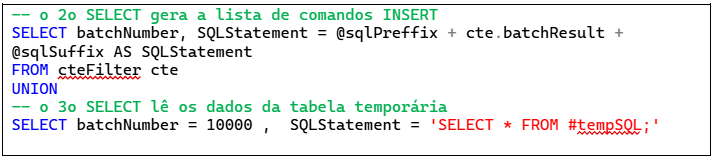
Definida a estratégia, começo alterando a variável @sqlPreffix, que se converte em uma operação de inserção na tabela #tempSQL.
Para facilitar a vida do usuário que vai gerar o script, eu inseri duas novas declarações SQL no gerador de scripts: uma antes da lista de INSERTs, criando a tabela temporária, e a segunda ao final do script, lendo os resultados da tabela temporária.
Para garantir a ordem das declarações dentro do script que foi gerado, incluí o campo que especifica a ordem de apresentação das declarações (batchNumber).
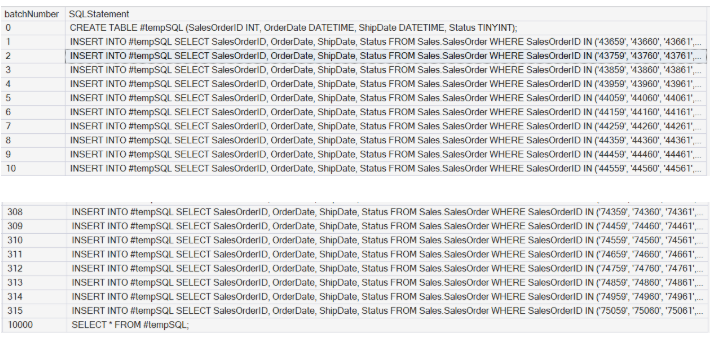
Chegamos à versão final do script, apresentada neste quadro :
O resultado é um script completo com 315 lotes. As imagens a seguir apresentam partes deste script.
Comentários Finais
Faz muitos anos que eu tenho estes “geradores de script” como parte das ferramentas que uso no dia a dia.
É evidente que a grande maioria das situações por que passamos não requer um particionamento de scripts. Mas quando isso acontece, a dor de cabeça vai ser grande, dependendo da quantidade de partições necessárias.
Essa abordagem tem vários pontos positivos, entre eles:
- ter controle individual dos resultados da operação de cada lote
- ser extremamente flexível e aplicável a qualquer tipo de declarações SQL
- requerer apenas a sua IDE para SQL.
Espero que tenha gostado!
Até a próxima

De 0 a 10, o quanto você recomendaria este artigo para um amigo?