



Fragmentação e desfragmentação de índices para DEVs
Fragmentação é quase um fato inevitável no mundo dos bancos de dados. Ela ocorre nas páginas de dados em que a informação é gravada e, sendo assim, afeta


Fragmentação é quase um fato inevitável no mundo dos bancos de dados. Ela ocorre nas páginas de dados em que a informação é gravada e, sendo assim, afeta igualmente tabelas e índices.
O principal problema da fragmentação é a degradação da performance do seu banco de dados ao longo do tempo. Tabelas e índices que funcionavam muito bem, começam a mostrar lentidão.
Por conta disso, entender o problema não é uma obrigação exclusiva dos DBAs, mas de todos que trabalham com o banco de dados, inclusive os desenvolvedores.
Neste artigo eu procuro dar resposta sobre o que é fragmentação, por que acontece e como resolver o problema.
O Que é Fragmentação
Para entender o problema, é preciso pensar na forma como os bancos de dados armazenam informação nos discos.
No SQL Server, os dados são normalmente gravados em blocos de 8 páginas de dados, cada uma com capacidade de 8Kb.
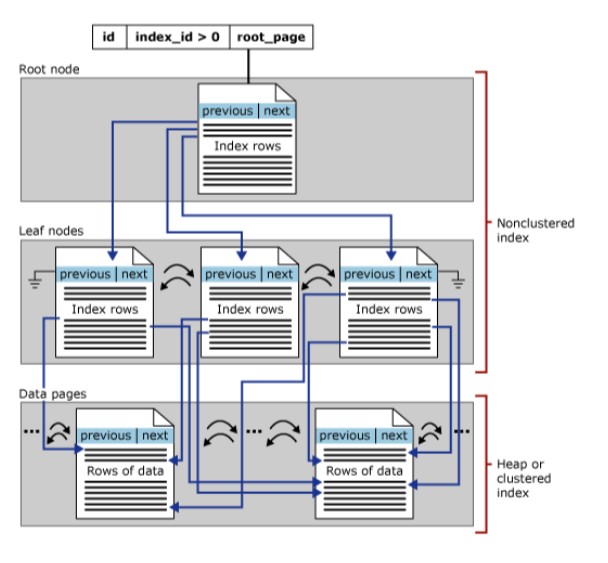
Imagine o caso de uma tabela que tem um índice clusterizado. As páginas de dados desse índice são de fato as páginas da própria tabela, com os registros ordenados conforme a chave desse índice. Cada vez que um novo registro é inserido na tabela, o SQL Server vai identificar o valor do(s) campo(s) clusterizado(s) e em qual página de dados ele deviria ser gravado. Se existir espaço suficiente para gravar tal registro nesta página de dados, isso vai acontecer e o processo se encerra. Do contrário, a gravação será designada para uma nova página de dados (em branco) do bloco que já está em uso. Isso é o que vai acontecer se seu índice clusterizado é criado, por exemplo, sobre um campo do tipo IDENTITY.
Porém pode acontecer que a sequência de valores a serem inseridos no catálogo do índice não siga a sequência de registros que são inseridos na tabela envolvida. Obviamente, aqui estamos falando de dois conjuntos de páginas de dados: as páginas da tabela e as páginas do índice que é construído. Veja este exemplo: num índice sobre o campo CIDADE numa tabela de PEDIDOS, a sequência de valores de cidades que são inseridos é completamente aleatória. Os valores do campo CIDADE não afetam as páginas de dados da tabela, que aceitam qualquer valor. Mas podem afetar o modo como as páginas de dados do índice são gravadas!
Pode acontecer de que seja necessário escrever o novo valor indexado numa página de dados que não tem espaço suficiente, mas que seja necessário escrever nesta página para manter a ordenação dos valores. O que acontece aqui é que todos os nomes de cidade “maiores” que o novo valor a ser inserido serão transferidos para uma nova página, apagados na página original e então será inserido o novo valor.
Este é um problema sério, que é conhecido como “page split” (ou seja, quebra de página). Isso é muito mais lento do que a execução de um simples “INSERT”, vários quilobytes de informação podem ser transferidos nesse processo. Além disso, a página que foi quebrada permanece com espaço livre para a possível inclusão de novos registros que não sigam a ordem esperada.
Este espaço que basicamente fica à espera de novas exceções é a origem da fragmentação.
Do mesmo modo, quando se exclui registros de uma tabela e/ou seus índices, também se libera espaço que pode não ser reutilizado em condições normais. Essa é outra fonte de fragmentação.
Por Que Acontece Fragmentação?
Mais especificamente, o que chamamos de fragmentação, ao final das contas, é o percentual de espaço não utilizado nas páginas de dados “ativas”.
Pela descrição acima, você deve ter captado a mensagem: é natural que haja “algum nível” de fragmentação na página de dados. Ela pode acontecer em alguns cenários, mesmo usando operações simples como INSERT, UPDATE e DELETE. O problema acontece quando esta fragmentação atinge níveis mais altos.
Qual nível é de fato preocupante? Esse é um critério subjetivo. Alguns DBAs consideram que fragmentação acima de 10% (moderada) já é um problema, enquanto outros adotam 30% (alta fragmentação) ou mais. A partir disso é recomendável fazer uma reorganização das páginas de dados desse índice ou tabela.
Como Identificar Objetos Fragmentados
Precisamos adotar alguns critérios para avaliação dessas tabelas e índices que mereçam atenção.
O primeiro deles é que tabelas com menos de 10.000 registros costumam ocupar tão pouco espaço que nem merecem atenção. Esse então será nosso primeiro critério (variável @minRows= 10000).
Outra questão é que vamos considerar dois níveis de fragmentação que merecem tratamentos diferentes (como veremos a seguir). O nível baixo de fragmentação considerado é de 10% (@minFrag=10) e o nível alto começa nos 30% (@maxFrag=30).
Finalmente, vamos considerar o caso de tabelas sem índice principal, as chamadas “heaps”. Neste caso, é de se esperar que as páginas de dados tenham o maior nível possível de utilização, portanto vamos pesquisar os casos de heaps que tenham menos que 75% de ocupação (@maxPgHeap = 75).
Com estes critérios em vista, usamos a função de sistema sys.dm_db_index_physical_stats, que é um verdadeiro coringa em matéria de fragmentação.
Quadro 01: identificação de objetos fragmentados
DECLARE @minRows VARCHAR(10) = '10000'
DECLARE @minFrag VARCHAR(10) = '10'
DECLARE @maxFrag VARCHAR(10) = '30'
DECLARE @maxPgHeap VARCHAR(10) = '75'
SELECT DISTINCT q.object_id,
DB_NAME() AS DB,
cast(SUB.ESQUEMA as VARCHAR(15)) AS ESQUEMA,
cast(SUB.TABELA as VARCHAR(50)) as TABELA,
cast(SUB.INDICE as VARCHAR(50)) as INDICE,
Q.index_id,
CAST(index_type_desc AS VARCHAR(20)) AS TIPO_INDICE,
index_level,
SUB.num_registros ,
avg_fragmentation_in_percent,
avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(0, NULL, NULL, NULL , 'SAMPLED') Q
LEFT JOIN (
select
I.object_id,
isnull(I.index_id, 0) as index_id,
MIN(S.name) as esquema,
MIN(O.name) as tabela,
MIN(isnull(I.name, '')) as indice ,
MIN(I.type) as tipo,
SUM(P.Rows) *10 AS num_registros
from sys.indexes I
inner join sys.all_objects O on I.object_id = O.object_id
inner join sys.schemas S on O.schema_id = S.schema_id
inner join sys.partitions AS P on O.object_id = P.object_id
WHERE
O.type = 'U'
AND P.index_id < 2 -- 0:Heap, 1:Clustered
GROUP BY
I.object_id,
isnull(I.index_id, 0)
) SUB ON SUB.object_id = Q.object_id AND SUB.index_id = Q.index_id
WHERE (
SUB.num_registros >= @minRows
AND
(avg_fragmentation_in_percent > @minFrag
OR
avg_page_space_used_in_percent < @maxPgHeap
)
)
OR
(
SUB.num_registros >=@minRows
AND index_type_desc IN ('HEAP')
AND avg_page_space_used_in_percent < @maxFrag
)
ORDER BY avg_fragmentation_in_percent DESC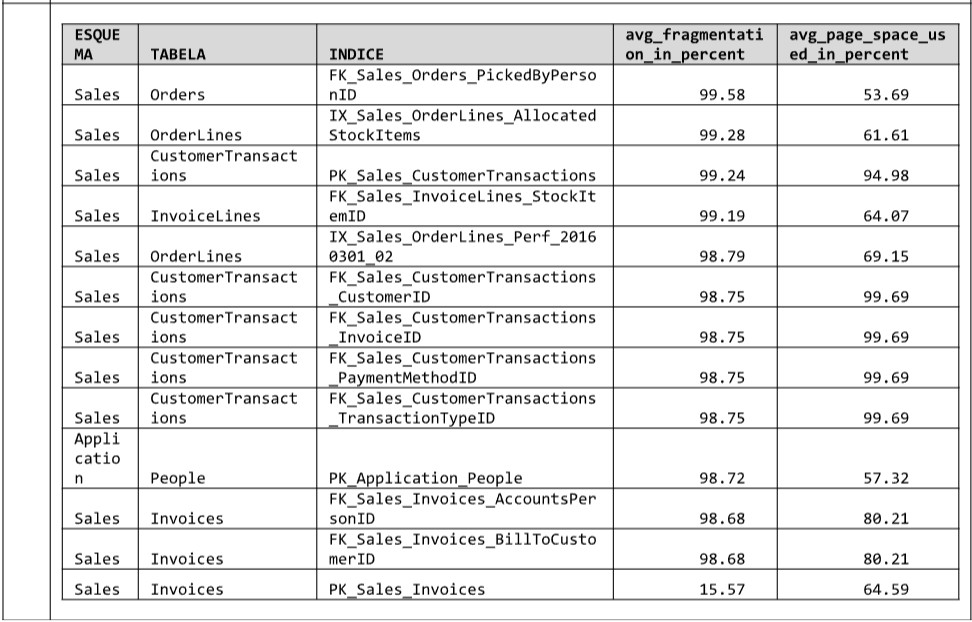
Como Resolver o Problema
Nosso próximo passo é tratar os objetos identificados na seção anterior.
Mas é importante ter em mente que resolver problema de fragmentação é um processo que leva tempo. E se você decidir fazer esta manutenção enquanto o banco de dados estiver em uso, tenha certeza de que vai ouvir muitas reclamações.
Durante o procedimento de redução/eliminação de fragmentação de um índice ou tabela, o banco de dados vai fazer um bloqueio (“lock”) de cada página de dados, vai reconstrui-la e repetir o processo nas páginas seguintes até tratar a última delas.
Dependendo do tamanho da sua tabela, isso pode levar horas.
Dito isto, voltemos ao tratamento da fragmentação. É comum que se considere tratamentos para 03 condições especiais:
- Tratamento de Heaps: aqui se aplica o mesmo tratamento para todas as tabelas identificadas, que é aplicar o comando ALTER TABLE xxx REBUILD;
- Tratamento de índices “pouco” fragmentados: isso se aplica índices clusterizados e não-clusterizados. Considera-se aqui tabelas que tenha fragmentação percentual na faixa de 10% a 30%. Nesses casos, pode-se usar o comando ALTER INDEX ixnome ON tabnome REORGANIZE;
- Tratamento de índices com fragmentação igual ou maior que 30%: nesses casos, não é suficiente executar o “reorganize” e passamos então para o comando ALTER INDEX ixnome ON tabnome REBUILD;
Considerando estes critérios, temos no Quadro 02 a lista de declarações a ser executada.
Quadro 02: Declarações SQL para eliminar fragmentação
ALTER INDEX FK_Sales_Orders_PickedByPersonID ON Sales.Orders REBUILD ; -- frag = 99.58%
ALTER INDEX IX_Sales_OrderLines_AllocatedStockItems ON Sales.OrderLines REBUILD ; -- frag = 99.28%
ALTER INDEX PK_Sales_CustomerTransactions ON Sales.CustomerTransactions REBUILD ; -- frag = 99.24%
ALTER INDEX FK_Sales_InvoiceLines_StockItemID ON Sales.InvoiceLines REBUILD ; -- frag = 99.19%
ALTER INDEX IX_Sales_OrderLines_Perf_20160301_02 ON Sales.OrderLines REBUILD ; -- frag = 98.79%
ALTER INDEX FK_Sales_CustomerTransactions_CustomerID ON Sales.CustomerTransactions REBUILD ; -- frag = 98.75%
ALTER INDEX FK_Sales_CustomerTransactions_InvoiceID ON Sales.CustomerTransactions REBUILD ; -- frag = 98.75%
ALTER INDEX FK_Sales_CustomerTransactions_PaymentMethodID ON Sales.CustomerTransactions REBUILD ; -- frag = 98.75%
ALTER INDEX FK_Sales_CustomerTransactions_TransactionTypeID ON Sales.CustomerTransactions REBUILD ; -- frag = 98.75%
ALTER INDEX PK_Application_People ON Application.People REBUILD ; -- frag = 98.72%
ALTER INDEX FK_Sales_Invoices_AccountsPersonID ON Sales.Invoices REBUILD ; -- frag = 98.68%
ALTER INDEX FK_Sales_Invoices_BillToCustomerID ON Sales.Invoices REBUILD ; -- frag = 98.68%
ALTER INDEX PK_Sales_Invoices ON Sales.Invoices REORGANIZE ; -- frag = 15.57%
GOComentários Finais
O assunto da fragmentação é mais extenso do que seria possível tratar num artigo de poucas páginas. Mas eu espero que este material ajude a você a ter ideia do problema e de como solucioná-lo.
Eu omiti uma série de detalhes que não me pareceram relevantes para quem vai ter um primeiro contato com este tema.
Foi o caso, por exemplo, da opção de fazer “rebuild” com o objeto ativo (rebuild online). Este é um recurso que alguns amam e outros odeiam. De fato, ele tem suas vantagens, mas é importante entender que a operação vai causar uma enorme lentidão dependendo do nível de uso do objeto que você está reconstruindo.
Outro ponto importante que não deve causar estranheza é que a execução de um “rebuild” ou “reorganize” não implica necessariamente que a fragmentação do objeto vá ser eliminada. É de se esperar que ela seja reduzida, mas não é incomum que isso não aconteça, especialmente quando se usa o “reorganize”. Nesse caso, o que se faz é repetir a ação usando um “rebuild”.
Para aqueles que queiram se aprofundar no tema, recomendo checarem a documentação do SQL Server, começando por este link.
Espero que tenha gostado do artigo. Até o próximo!
Consultor Sênior na Microsoft, na área de Data Insights para América Latina. Especialista em bancos de dados, é colunista em diversos portais de TI do Brasil e do exterior, com mais de 100 artigos técnicos publicados. É também co-produtor do DatabaseCast, primeiro podcast brasileiro sobre bancos de dados.



