



Scripts SQL e Tabelas de Sistema – Parte 4: Atuando em Toda Instância
Fechando esta série sobre Banco de dados e Scripts SQL, apresento um caso mais trabalhoso, onde as consultas envolvem dados de toda instância. Isso quer…


Fechando esta série sobre Banco de dados e Scripts SQL, apresento um caso mais trabalhoso, onde as consultas envolvem dados de toda instância. Isso quer dizer que são usadas tabelas de sistema de múltiplas bases de dados.
Neste exemplo, o objetivo é identificar em toda instância as tabelas que são de tipos especiais, como por exemplo tabelas em memória, tabelas temporais, tabelas de grafos, tabelas replicadas, tabelas de ledger (disponíveis no SQL Server 2022).
Scripts SQL – Origem da Informação
Nos exemplos anteriores, usei muitas vezes a tabela de sistema sys.objects, que contém dados de todos os objetos do banco de dados. Porém esta tabela não traz todas as informações sobre as tabelas de usuário que serão necessárias no presente estudo.
Por isso uso aqui a visão de sistema sys.tables, que traz informações mais detalhadas, mas lida apenas com tabelas de usuário. (Veja mais detalhes).
Com este catálogo, consigo classificar os tipos de tabela de usuário de um determinado banco de dados, como se vê na consulta do Quadro 1.
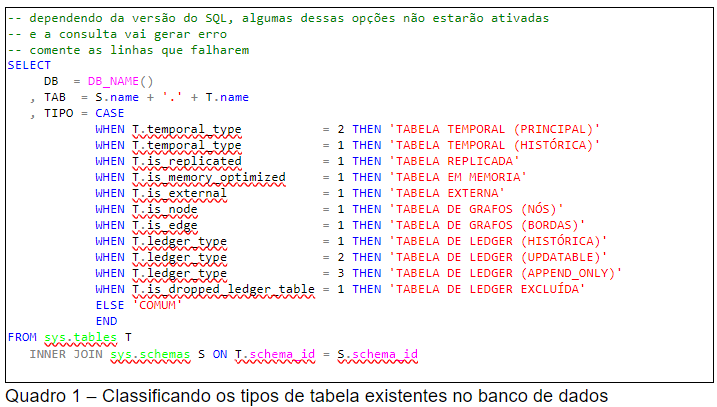
O leitor mais atento vai notar que eu usei um “join” com a tabela sys.schemas ao invés usar simplesmente a função SCHEMA_NAME() para identificar o nome do esquema associado a tabela (coluna TAB).
Essa diferença é fundamental no exemplo que vou mostrar, porque a função mencionada tem escopo sobre o banco de dados ativo. Como vou escrever uma consulta para ser executada sobre todos os bancos de dados, a função iria falhar.
Do mesmo modo, a função DB_NAME() usada na coluna DB também irá falhar. Por isso ela necessariamente terá que ser substituída por uma cadeia de caracteres na montagem do script final.
Atuando sobre Toda Instância
É hora de adaptar a consulta do Quadro 1 para que seja feita uma varredura sobre toda instância.
As alterações necessárias são óbvias, mas é um pouco complicado escrever isso no script. Basicamente vamos repetir aquela consulta para todos os bancos e juntar os resultados com o operador UNION.
Além dos detalhes que comentei anteriormente, temos que informar na definição da cláusula FROM o nome do banco de dados que está sendo pesquisado. É fácil fazer isso fazendo uma consulta sobre a tabela de sys.databases disponível na base MASTER e gerando uma cadeia de caracteres que não é nada mais a declaração SQL que desejo. O Quadro 2 mostra esta declaração.
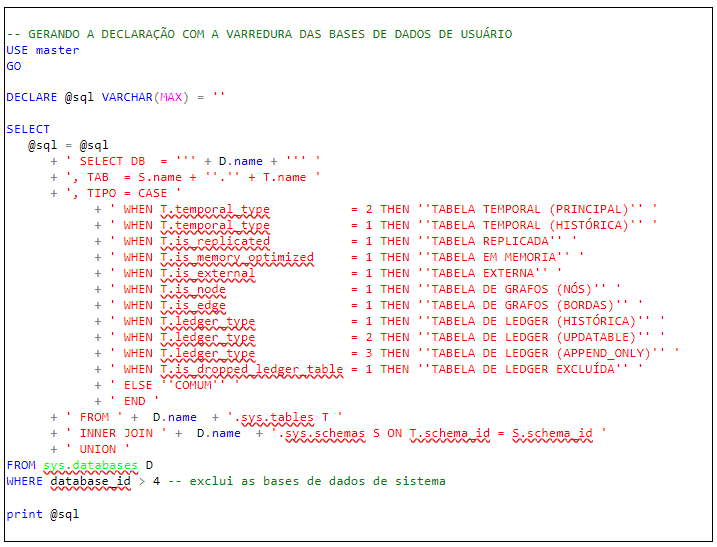
Basicamente, todo texto em vermelho da cláusula SELECT no Quadro 2 é de fato a consulta original mostrada no Quadro 1, ao que eu adicionei alguns ajustes.
Examinando mais atentamente a cláusula SELECT, pode-se observar que a cadeia de caracteres gerada terá ao seu final uma cláusula UNION extra. Portanto, ela ainda não é uma declaração SQL válida. Esse problema é contornado eliminando os últimos seis caracteres da variável @sql.
Além disso, para que eu possa analisar os dados que serão coletados, é interessante gravar as informações coletadas. O Quadro 3 mostra estes passos.
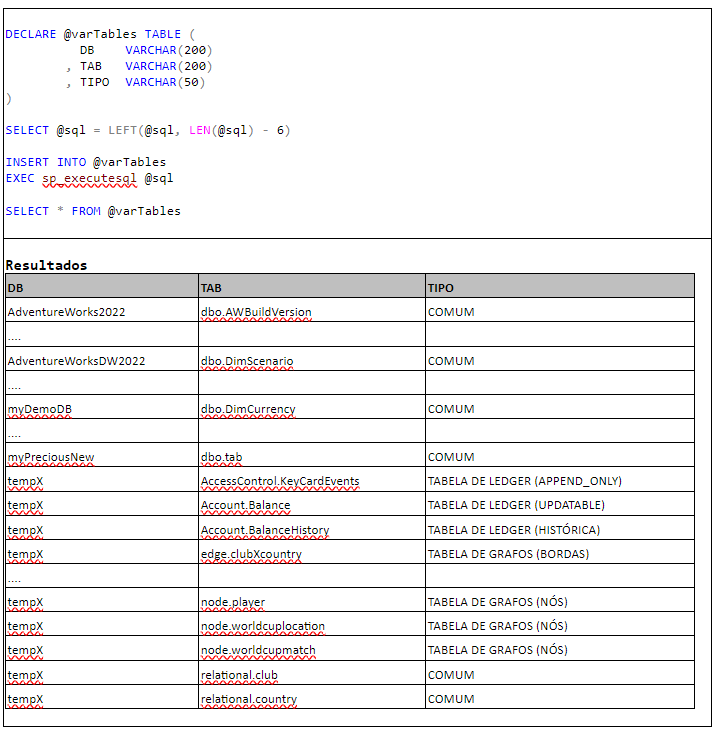
Na minha instância de demo, foram identificadas mais de 150 tabelas. Para ter uma visão geral das minhas tabelas, farei uma nova consulta que mostra a quantidade de tabelas de cada tipo que fazem parte de cada base de dados.
Incluo também o operador ROLLUP e a função GROUPING para mostrar também o total geral por base. O Quadro 4 mostra esta consulta e seus resultados.
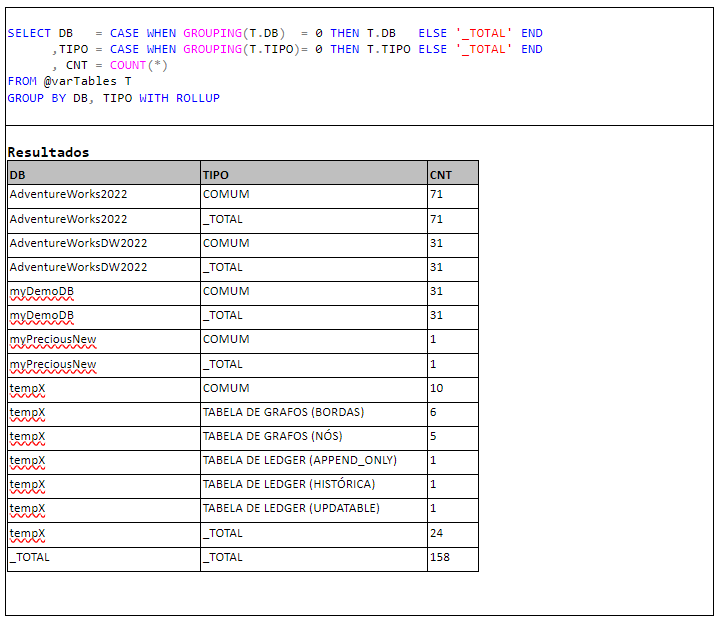
Vale lembrar que, como eu usei uma variável de tabela para gravar os resultados, estes só estarão disponíveis durante a execução do lote de declarações SQL (ou “batch”, se preferir). Portanto as declarações que apresentei nos quadros 2, 3 e 4 precisam ser executadas como um único lote.
Nesse aspecto, a declaração de uma tabela temporária seria mais versátil, porque ela irá existir enquanto a sessão permanecer aberta. Só não usei esta alternativa, porque seria necessário alterar a declaração do Quadro 2, adicionando um “CREATE TABLE” antes da declaração das varáveis.
Para fazer o download do script completo, click neste link.
Comentários Finais
Como se pode ver, a construção de scripts que atuem em toda instância não é nenhum bicho de sete cabeças. Mas é fato que é preciso muita atenção na construção das declarações e o aprendizado de alguns truques que procurei mostrar aqui.
Naturalmente a estratégia de criação de scripts apresentada aqui é apenas uma de várias maneiras que tratam da execução de ações sobre toda instância SQL. Muitos desenvolvedores usam, por exemplo, o procedimento sp_MSforeachdb. Porém, este recurso não é documentado e nem suportado pela MICROSOFT. Ele até que funciona bem, mas você escolhe usá-lo por sua própria conta e risco.
No meu entendimento, quando o desenvolvedor cria seu próprio script, ao menos ele compreende detalhes das ações que está executando.
Volto a reforçar que o lema do Tio Ben (Homem-Aranha) é mais do que válido em casos como o apresentado aqui: “Com grandes poderes vêm grandes responsabilidades”.
Com scripts que atuam sobre toda instância, você pode reduzir dramaticamente o tempo de execução de tarefas do dia a dia. Mas também corre o risco de destruir sua instância inteira se não testar extensivamente o seu script em ambiente controlado.
Eu uso estes recursos com frequência, mas sempre tenho cuidado de fazer testes para todos os cenários em que meu script pode atuar.
Espero que esta série de artigos sobre Banco de dados e Scripts SQL tenha sido útil para você também!
Até a próxima.
Leia todas as partes aqui:
Scripts SQL e Tabelas de Sistema – Parte 1: Alterando Colunas
Scripts SQL e Tabelas de Sistema – Parte 2: Criando Índices
Scripts SQL e Tabelas de Sistema – Parte 3: Arquivos de Log
Scripts SQL e Tabelas de Sistema – Parte 4: Atuando em Toda Instância
Consultor Sênior na Microsoft, na área de Data Insights para América Latina. Especialista em bancos de dados, é colunista em diversos portais de TI do Brasil e do exterior, com mais de 100 artigos técnicos publicados. É também co-produtor do DatabaseCast, primeiro podcast brasileiro sobre bancos de dados.



