

No meu artigo anterior (link), falei sobre conceitos básicos relativos aos índices e descrevi um caso em que o índice clusterizado (aka IC) de uma tabela comprometia a performance de todos os índices associados a ela. Neste artigo, mostro estratégias para identificar estes casos em que os Índices Clusterizados – ICs são suspeitos de serem os vilões.
Quando ICs (Índices Clusterizados) podem ser problemas
No SQL Server, ICs (Índices Clusterizados) são tão importantes que eles são criados automaticamente quando se cria uma chave primária (aka PK) na tabela.
As PKs especificam uma chave que garante que cada registro é único. Obviamente, isso facilita enormemente a localização de um registro. É possível criar a PK com base em um campo ou vários, mas fica evidente que quanto menor o tamanho dessa chave, mais rápida será a identificação do registro.
Se o IC é criado sobre a PK da tabela ou sobre uma chave alternativa (aquela que não é PK, mas também identifica um único registro), na grande maioria dos casos, seu modelo está num bom caminho.
Uma forma de buscar possíveis problemas com o IC é identificar tabelas que definem o índice sobre outro campo que não seja aquele usado como PK ou como chave alternativa.
Também pode ser um problema quando a chave do seu IC é muito longa. Isso pode causar, por exemplo, queda de performance nas operações de CRUD.
Como o SGBD precisa verificar em que página de dados ele deve inserir, alterar ou excluir um registro como uma determinada chave, vai ser muito mais demorado pesquisar chaves muito longas, como por exemplo um campo chave sendo CHAR(50).
Neste artigo apresento scripts para identificação desses dois cenários:
- Quando o IC é diferente da chave primária e da chave alternativa
- Quando o IC é definido sobre um conjunto de campos (numéricos e alfanuméricos) que formam uma chave muito grande.
Caso 1 – IC Diferente da PK ou Não Tem Valores Únicos
Por sorte, as informações que precisamos para resolver este caso estão disponíveis em apenas duas tabelas de catálogo: sys.objects e sys.indexes.
Como não me interessa analisar as tabelas de catálogo, especifico na minha consulta que só quero ver as tabelas de usuários, que são designadas pelo TIPO “U” (exemplo: select name as tabname from sys.objects where type = ‘U’).
Para esta análise, só me interessam ICs, que são reconhecidos na tabela de índices como TIPO 1 (exemplo: select name as ixname from sys.indexes where type = 1).
Agora é preciso identificar mais filtros que precisam ser aplicados a esse conjunto de dados. O primeiro deles é reconhecer quem é IC, mas não é PK. Para isso, o catálogo sys.indexes traz o campo booleano IS_PRIMARY_KEY. Obviamente, o filtro desejado aqui é que o valor desses campos seja 0. Obviamente, isto significa que o valor do campo IS_PRIMARY_KEY é FALSO (exemplo: select name as ixname from sys.indexes where type = 1 and (is_primary_key = 0).
Finalmente, chegamos no ponto em que tratamos dos ICs que não são chaves alternativas. O jeito mais fácil de definir chaves alternativas é criando um índice (não clusterizado) com valores únicos, incluindo a cláusula UNIQUE na definição deste objeto. Mais uma vez, esta informação está disponível na tabela sys.indexes: no campo IS_UNIQUE. No nosso caso, buscamos ICs que tenham valor 0 para este
campo.
Essas condições são importantes, porque não precisamos necessariamente que o IC coincida com a PK, desde que seja definido sobre um campo que tenha valores únicos. Para saber mais sobre o assunto, veja documentação oficial sobre ICs. Combinando tudo o que eu apresentei numa única declaração SQL, temos o seguinte resultado.

Para mais informação, veja este artigo de Brent Ozar que trata de uma situação semelhante a que descrevo aqui.
Caso 2 – IC Sobre Chave Muito Grande
Qualquer chave que, na soma dos tamanhos de todos os seus campos, tenha um número grande de bytes não é uma boa candidata a ser a chave do IC, como eu expliquei anteriormente.
A questão aqui é o que exatamente significa uma “chave de tamanho grande”. A título de comparação, considere o caso em que a chave do IC é definida sobre um campo do tipo BIGINT. Este campo permite a construção de tabelas com bilhões de registros.
Ainda assim, o tamanho de um campo do tipo BIGINT é de apenas 8 bytes. Portanto, qualquer chave que tenha o dobro desse tamanho é com certeza uma chave grande.
Aqui não importa se o IC foi definido sobre uma PK ou um índice do tipo UNIQUE. O tamanho total da chave é que causa problema.
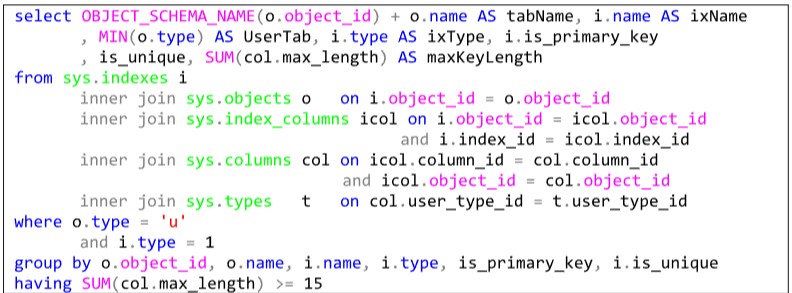
Então, para identificar os Índices Clusterizados – ICs – que tenham uma chave com tamanho total considerado grande, é preciso saber quem são os campos que formam a chave do IC e qual o tamanho máximo de cada campo.
Também tenho que somar os tamanhos dos campos da chave e verificar se o total é maior ou igual a 15, por exemplo.
Este é um caso mais complexo, porque é necessário buscar informações em várias tabelas de sistema para encontrar informações sobre índices, as chaves correspondentes, as tabelas envolvidas e o tamanho dos campos usados na chave.
Juntando tudo isso, temos a declaração do quadro a seguir.
O SQL Server até suporta a definição de ICs sobre campos muito grandes, mas isso não quer dizer que você deva fazer isso. Por exemplo: não é possível criar um IC sobre um campo com tipo de dados BINARY(1000). Mas é sim possível criá-lo sobre um campo BINARY(100).
De qualquer modo, a checagem de um campo desse tamanho para que se execute qualquer operação CRUD será sempre um problema,
com evidente impacto na performance de todas as consultas que usem a tabela envolvida.
Corrigindo o Problema dos Índices Clusterizados
Identificar ICs problemáticos é só uma parte da questão.
Corrigir esse problema é muito mais trabalhoso. Lembre-se que o IC não é um catálogo adicional criado sobre a tabela, que eu possa criar ou excluir com certa rapidez. Recriar o IC de uma tabela grande pode levar horas.
Um procedimento para alterar o IC de uma tabela poderia ser o seguinte:
- 1. Pôr o banco de dados em modo “single user”: nenhuma transação pode acessar a tabela que estiver sendo alterada durante a condução do procedimento.
- 2. Fazer uma cópia de backup da tabela inteira
- 3. Apagar a definição do IC (drop index x on nome-da-tabela)
- 4. Criar a nova definição do IC
- 5. Esperar, esperar, esperar…. todas as páginas de dados da tabela serão reconstruídas usando a ordenação definida pelo novo IC.
De modo geral, quando falamos de alteração de ICs, estamos falando de um longo período de inatividade da base de dados inteira.
Comentários Finais
Conhecer procedimentos para identificação de índices clusterizados (ICs) com desempenho ruim e a correção do problema são, na verdade, um lembrete para a eterna máxima: “faça direito da primeira vez”.
Quando o modelo de dados e/ou sua implementação são mal planejados, fatalmente o custo disso será cobrado de uma das seguintes formas:
- 1. performance ruim para sempre
- 2. indisponibilidade do banco de dados por longo período (para fazer as correções necessárias).
Até a próxima!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?