

Vira e mexe o assunto dos índices columnstore volta à tona. Alguém ouve dizer que estes índices oferecem uma performance excelente, ao mesmo tempo que compacta os dados e tem a brilhante ideia de usar em qualquer tipo de aplicação.
Esta estratégia da “bala de prata”, aquela bala que resolve qualquer problema, costuma ser um verdadeiro tiro no pé.
Neste artigo apresento conceitos básicos sobre estes índices e os prós e contras do seu uso.
O Que é tão diferente no Índice ColumnStore?
Quando nos referimos a um índice sem especificar seu tipo, na verdade estamos falando dos tradicionais índices “rowstore”.
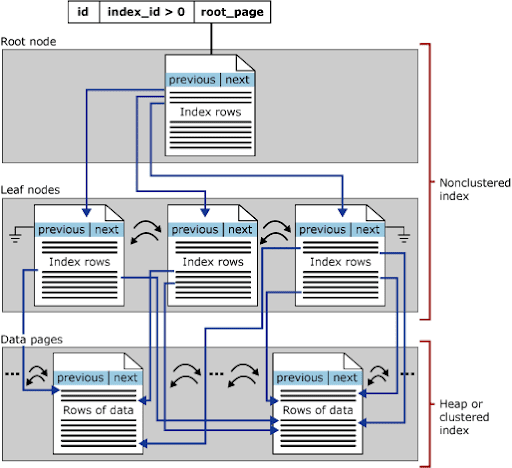
Estes índices gravam os dados em disco como registros ordenados com base em um ou mais campos indexados. A partir disso, são criadas páginas de consolidação das informações para facilitar a busca desses dados. A estrutura criada por eles é conhecida como “B-tree”, que pode ter diversos níveis de consolidação. A Figura 1 é um exemplo apresentado na documentação oficial do SQL Server.
Um índice columnstore trabalha de forma bem diferente. Ao invés de gravar os dados como registros que seguem uma determinada ordem, este índice é orientado pelas colunas da tabela. O índice cria uma lista de valores de cada campo, isto é, as colunas, e estas listas fazem apontamentos para uma estrutura chamada de rowgroup, compondo assim algo semelhante a um grupo de registros. O quadro a seguir explica como fica esta arquitetura (mais informações na documentação oficial):
Um índice columnstore trabalha de forma bem diferente. Ao invés de gravar os dados como registros que seguem uma determinada ordem, este índice é orientado pelas colunas da tabela. O índice cria uma lista de valores de cada campo, isto é, as colunas, e estas listas fazem apontamentos para uma estrutura chamada de rowgroup, compondo assim algo semelhante a um grupo de registros. O quadro a seguir explica como fica esta arquitetura (mais informações na documentação oficial):
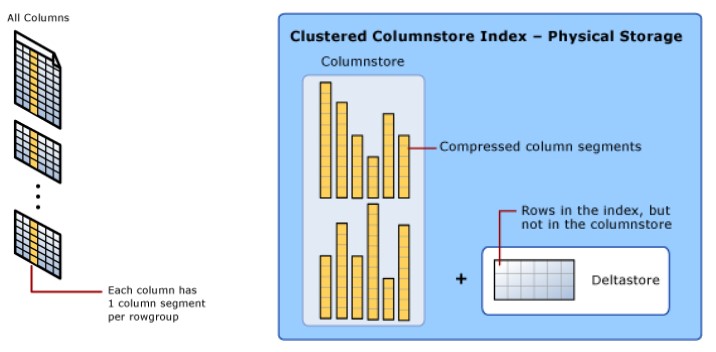
O conjunto de todos os rowgroups referentes a um índice columnstore clusterizado costuma ser chamado de Deltastore, como se vê na figura acima.
Cada rowgroup pode ter no máximo 1.048.576 linhas. Portanto, uma tabela com 10 milhões de registros, se convertida para um índice columnstore clusterizado, será gravada em 10 rowgroups.
Essa característica dos rowgroups resulta numa recomendação importante: só devem usar índices columnstore as tabelas que tenham mais de 1 milhão de registros. Se a tabela for particionada, essa regra se aplica a cada partição (veja detalhes aqui). Para tabelas ou partições menores que este limite, a compactação obtida dificilmente será adequada para que o índice columnstore apresente performance melhor do que um índice comum (ou rowstore, para ser específico).
Deste modo, o índice columnstore, se bem utilizado, consegue reduzir o espaço consumido pelos dados e ao mesmo tempo melhorar a performance das consultas.
OBSERVAÇÃO: este número máximo de registros de cada rowgroup, 1.048.576, não é um número ao acaso. Ele equivale a 220.
Principais preocupações com Índices Columnstore
Os Índices columnstore costumam ser usados em aplicações relacionadas a Data Analytics, como por exemplo em bases de dados que são usadas para Data Warehouses e/ou de Business Intelligence.
Como eu comentei acima, uma das preocupações é o tamanho da tabela que vai receber um índice deste tipo. Em tabelas pequenas (menos de 1 milhão de registros por partição), é melhor usar o índice comum (rowstore).
Outro ponto fundamental é usá-lo em tabelas que não sofrem atualizações e/ou exclusões. Se estas operações são frequentes, não use índice columnstore, porque a performance deste índice em operações de UPDATE e DELETE é muito ruim.
Um exemplo: você está criando um Data Warehouse e a tabela fato do seu modelo é muito grande e não sofre atualizações. Este é o cenário ideal para uso do índice columnstore.
Porém seu modelo inclui tabelas de dimensão que também são muito grandes. Elas usar este tipo de índice?
A resposta é não. Dimensões geralmente sofrem atualizações frequentes e neste caso provavelmente a melhor opção seria uso de índices comuns (rowstore) associados ao particionamento da tabela (se houver).
Tipos de Índices Columnstore
Nos exemplos anteriores, eu me referia especificamente aos índices columnstore clusterizados, aqueles em que a tabela inteira é escrita no formato columnstore.
Mas existem também os índices columnstore não-clusterizados. Entenda que este índice é um catálogo colunar separado das páginas de dados da tabela (que são gravadas no formato normal B-tree).
A proposta destes índices é permitir consultas mais rápidas em tabelas transacionais. Ou nas dimensões grandes, que citei no segundo caso.
O problema aqui é que o ganho nas operações SELECT graças aos índices columnstore não-clusterizados raramente compensam a perda de performance que eles provocam nas operações UPDATE e DELETE.
Especialmente no caso das tabelas transacionais grandes, não é raro ocorrer alteração de registros. E muitas vezes essas operações fazem parte das transações. Obviamente, aumentar a duração entre um BEGIN e um COMMIT em tabelas assim não parece uma boa ideia.
Por conta disso, os índices columnstore não-clusterizados são usados raramente, apesar de eles realmente oferecerem uma boa performance.
Comentários Finais
Índices columnstore, seja clusterizados ou não, realmente oferecem uma performance muito boa quando aplicados em tabelas com mais de 1 milhão de registros.
Mas é preciso ter em mente que índices, sejam quais forem, só ajudam na seleção de dados. E os índices do tipo columnstore tem um problema sério de performance nas operações de atualização e exclusão de registros.
Eles são uma ferramenta importante no seu arsenal. Mas nunca poderão ser vistos como a bala de prata.
Espero que tenha gostado deste artigo.
Até a próxima!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?