

Listas, arrays, matrizes, vetores. Independente do nome que você prefira usar, cedo ou tarde vai ter que lidar com estes tipos de estrutura de dados.
Estas não são estruturas comuns no mundo relacional, porém temos que ter em mente que hoje a diversidade de formatos e estruturas é uma regra no mundo corporativo. Mais que nunca, a integração de dados é uma exigência de negócio.
Nesse primeiro artigo, analiso o tratamento que recebem os que são dados estruturados como listas dentro de arquivos JSON. As técnicas empregadas aqui são aplicáveis a qualquer plataforma SQL, seja on-premises (SQL 2016 ou superior) ou na nuvem (todas as modalidades).
JSON e Listas
Faz algum tempo que publiquei aqui no IMASTERS um artigo sobre manipulação de arquivos JSON (veja o link). Aquela abordagem permitia ler uma série de estruturas de dados, mas não mencionava a questão de dados como organizados em listas de valores.
As listas em JSON podem ser de valores ou mesmo outros JSONs e são caracterizadas por serem definidas por colchetes (“[…]”). As linhas 04 e 18 da Tabela 1 mostram estes casos.
| 01
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 |
{
“OrderNumber”: “574895677”, “Customer”: “John Doe”, “Adress”: [ { “Name: “Casa”, “Street”: “Rua 5, no 42”, “City”: “São Paulo”, “State”: “SP” }, { “Name: “Escritorio”, “Street”: “Rua D Pedro, no 500”, “City”: “Rio de Janeiro”, “State”: “RJ” } ], “ProductID”: [ “AAF”,”AAR”,”AAS”,”AAT”,”AAV”,”AAW” ] } |
Tabela 1: exemplo de estruturas suportados em arquivos JSON
Preparativos no Banco de Dados
Quando lemos arquivos JSON locais em um servidor on-premises, basta informar o caminho completo até o arquivo e iniciar o trabalho. Na nuvem, as preocupações com segurança são muito maiores e por isso requer uma preparação para ler estes dados.
Neste artigo, vou usar o AZURE SQL DB para acessar dados armazenados como BLOBs em uma conta de armazenamento (ou “Storage Account GEN2”) do AZURE. Para tanto, é preciso criar os seguintes objetos no seu banco de dados:
- Uma chave mestra, que protegerá a credencial que vamos criar
- Uma credencial com escopo no banco de dados a que pertence
- Um segredo para acesso aos blobs
- Uma fonte de dados externa
Para criação da chave mestra, basta executar o seguinte comando:
| 01
02 03 |
CREATE MASTER KEY
ENCRYPTION BY PASSWORD = ‘<SenhaSegura>‘ GO |
Antes de criar a credencial, é preciso gerar o segredo para acesso aos blobs. A maneira mais fácil de fazer isso é via POWERSHELL (veja este link). O segredo gerado deve ser incorporado no seguinte comando:
| 01
02 03 04 |
CREATE DATABASE SCOPED CREDENTIAL <NomeDaCredencial>
WITH IDENTITY = ‘SHARED ACCESS SIGNATURE’, SECRET = ‘<segredo>‘ GO |
Finalmente criamos a fonte de dados externa, como se vê no quadro a seguir.
| 01
02 03 04 05 06 07 |
CREATE EXTERNAL DATA SOURCE <NomeDataSource>
WITH ( LOCATION = ‘https://<NomeStoAcc>.blob.core.windows.net/<NomeContainer>‘, CREDENTIAL = <NomeDaCredencial>, TYPE = BLOB_STORAGE ) GO |
Tratando as Listas em Arquivos JSON
Já estamos prontos para ler os arquivos da conta de armazenamento. A seguir veremos como usar o operador OPENJSON.
Este é o script completo para ler o arquivo JSON.
| 01
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
DECLARE @PATH NVARCHAR(200)
DECLARE @FILE NVARCHAR(200) DECLARE @DSOURCE NVARCHAR(200) DECLARE @json NVARCHAR(MAX) DECLARE @SQL NVARCHAR(MAX) DECLARE @Parameter NVARCHAR(500) SET @PATH = ‘<CaminhoDentroContainer>‘ SET @FILE = ‘<NomeArquivo>‘ SET @DSOURCE = ‘<NomeDataSource>‘ SET @ENCODING = ‘<Codigo>‘ — p/ UTF-8 => SINGLE_CLOB e p/ UTF-16 => SINGLE_NCLOB SET @SQL = N’SELECT @jsonOUT = BulkColumn ‘ + ‘FROM OPENROWSET (‘ + ‘BULK ”’+ @PATH + @FILE +”’, ‘ + ‘DATA_SOURCE = ”’ + @DSOURCE + ”’, ‘ + @ENCODING + ‘) as j’ SET @Parameter = N’@jsonOUT NVARCHAR(MAX) OUTPUT’; EXEC SP_EXECUTESQL @SQL,@params = @Parameter, @jsonOUT = @json OUTPUT SELECT * FROM OPENJSON ( @json, ‘#8217; ) |
O output que vai gerar para a leitura do arquivo JSON apresentado na Tabela 1 é:
| key | value | type |
| OrderNumber | 574895677 | 1 |
| Customer | John Doe | 1 |
| Adress | [ { “Name”: “Casa”, “Street”: “Rua 5, no 42”, … } ] | 4 |
| ProductID | [ “AAF”,”AAR”,”AAS”,”AAT”,”AAV”,”AAW” ] | 4 |
Caso se deseje lidar com o esquema interno do JSON, substituímos o SELECT da linha 24 por uma declaração que reflita este esquema, como vemos a seguir.
| 01
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 |
SELECT J.OrderNumber, J.Customer, P.value AS ProductID, A.Name, A.Street, A.City, A.State
FROM OPENJSON ( @json, ‘#8217; ) WITH ( OrderNumber VARCHAR(200) ‘$.OrderNumber’ , Customer VARCHAR(200) ‘$.Customer’ , Adress NVARCHAR(MAX)‘$.Adress’ AS JSON , ProductID NVARCHAR(MAX)‘$.ProductID’ AS JSON ) AS J CROSS APPLY OPENJSON (J.ProductID,‘#8217;) P CROSS APPLY OPENJSON (J.Adress) WITH ( Name VARCHAR(200) ‘$.Name’ , Street VARCHAR(200) ‘$.Street’ , City VARCHAR(200) ‘$.City’ , State VARCHAR(200) ‘$.State’ ) AS A |
Observe que a primeira chamada OPENJSON define a estrutura principal do arquivo, estabelece as colunas OrderNumber, Customer, Adress e ProductID. Nessa definição, as duas últimas colunas foram classificadas como novos JSONs, de modo que se pudesse expandir seu conteúdo.
Acontece que o tratamento dessas duas colunas “JSON” ocorre de forma distinta. Apesar de ambas invocarem o operador OPENJSON, a primeira delas, Adress, é uma lista de JSONs e por isso foi expandida em novas colunas, do mesmo modo que se tratou a estrutura principal.
No caso da coluna ProductID, trata-se de uma lista de valores associada à marcação “ProductID”. Isto requer um tratamento diferenciado, embora tenha solução simples e elegante. Aqui basta usar o operador OPENJSON e na cláusula SELECT apontar para a lista de valores usando a sintaxe “MeuAlias.value”. No exemplo acima, usei o alias “P”.
O output dessa nova consulta é uma tabela de valores.
| OrderNumber | Customer | ProductID | Name | Street | City | State |
| 574895677 | John Doe | AAF | Casa | Rua 5, no 42 | São Paulo | SP |
| 574895677 | John Doe | AAF | Escritorio | Rua D Pedro, no 500 | Rio de Janeiro | RJ |
| 574895677 | John Doe | AAR | Casa | Rua 5, no 42 | São Paulo | SP |
| 574895677 | John Doe | AAR | Escritorio | Rua D Pedro, no 500 | Rio de Janeiro | RJ |
| 574895677 | John Doe | AAS | Casa | Rua 5, no 42 | São Paulo | SP |
| 574895677 | John Doe | AAS | Escritorio | Rua D Pedro, no 500 | Rio de Janeiro | RJ |
| 574895677 | John Doe | AAT | Casa | Rua 5, no 42 | São Paulo | SP |
| 574895677 | John Doe | AAT | Escritorio | Rua D Pedro, no 500 | Rio de Janeiro | RJ |
| 574895677 | John Doe | AAV | Casa | Rua 5, no 42 | São Paulo | SP |
| 574895677 | John Doe | AAV | Escritorio | Rua D Pedro, no 500 | Rio de Janeiro | RJ |
| 574895677 | John Doe | AAW | Casa | Rua 5, no 42 | São Paulo | SP |
| 574895677 | John Doe | AAW | Escritorio | Rua D Pedro, no 500 | Rio de Janeiro | RJ |
Avaliando a Performance
De modo geral, a performance das operações envolvendo operador OPENJSON não é boa. Para entender melhor este impacto, vamos avaliar três situações diferentes.
Caso 1
Aqui consideramos o plano de execução da consulta que gerou a listagem apresentada acima. O procedimento envolve duas consultas, sendo que a segunda, que trata da formatação do JSON, responde por 96% de todo custo do processo: 0,6605. O tempo de execução foi de 01 segundo.
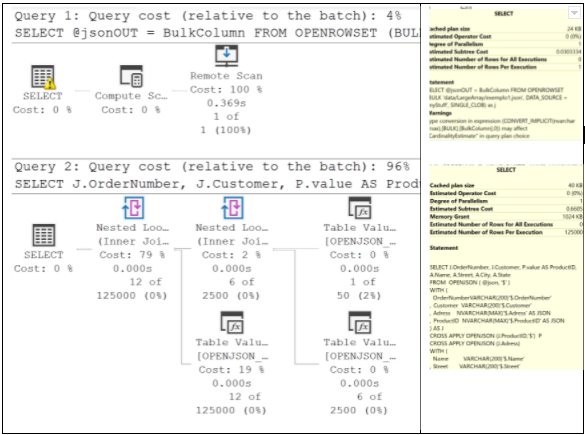
Caso 2
Desta vez vamos consultar o mesmo arquivo JSON, mas vamos desconsiderar a lista de JSONs da marcação “Adress”. A primeira parte do procedimento continua idêntica, mas segunda vai usar a seguinte declaração:
| 01
02 03 04 05 06 07 08 09 |
SELECT J.OrderNumber, J.Customer, P.value AS ProductID
FROM OPENJSON ( @json, ‘#8217; ) WITH ( OrderNumber VARCHAR(200) ‘$.OrderNumber’ , Customer VARCHAR(200) ‘$.Customer’ , Adress NVARCHAR(MAX)‘$.Adress’ AS JSON , ProductID NVARCHAR(MAX)‘$.ProductID’ AS JSON ) AS J CROSS APPLY OPENJSON (J.ProductID,‘#8217;) P |
Neste caso, vamos converter em tabela a lista de valores da coluna ProductID. O custo da primeira consulta é exatamente o mesmo do caso anterior, porém a segunda consulta roda 50 vezes mais rápido, tendo seu custo reduzido para 0.0130 (contra 0,6605 no Caso1)!!! O tempo de execução praticamente não mudou (01 seg).
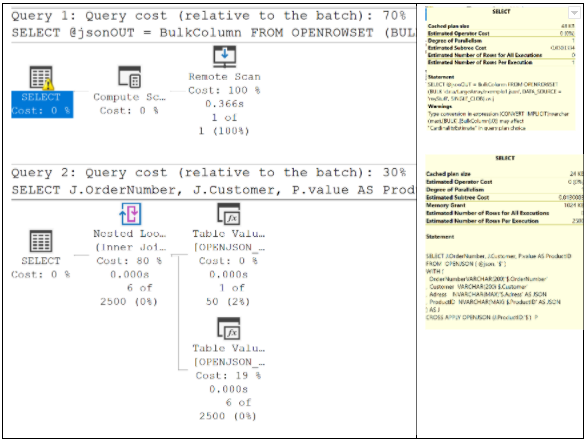
Caso 3
Agora vamos avaliar uma expansão do Caso 2. Usaremos outro arquivo JSON com mesmo esquema, porém dessa vez o campo ProductID tratará uma lista com 100 mil valores ao invés de apenas 6.
A única alteração no procedimento é reapontar o script para ler o arquivo “exemplo2.json”, cujo tamanho é de 811 Kb, ao invés do arquivo “exemplo1.json”, de 445 bytes.
Observe no plano de execução abaixo que, apesar de estar lendo um arquivo quase 2 mil vezes maior, os custos da primeira e segunda consultas são exatamente os mesmos que observamos no Caso 2! O tempo de execução subiu, mas muito pouco: apenas 06 segundos.
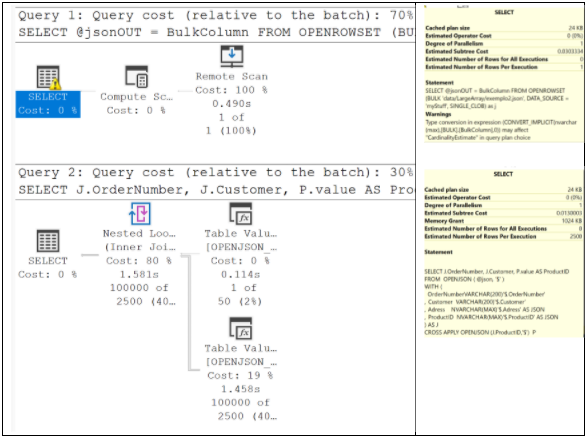
Comentários Finais
Como vimos neste estudo, a preparação para acesso a arquivos JSON armazenados em contas de armazenamento requer alguns cuidados especiais. Porém, uma vez configurados, a leitura desses arquivos no Azure SQL DB funciona muito bem.
Sobre a leitura de listas de valores em formato JSON, os dois pontos que se destacam são:
- A sintaxe usada para leitura dessas estruturas é bastante simples. Basta definir a coluna como JSON, abri-la com o operador OPENJSON e apontar para seus valores com a expressão “MeuAlias.value”.
- O custo de execução de consultas envolvendo listas de valores é praticamente invariável. O impacto do tamanho da lista na performance da operação é muito menor do que se poderia esperar.
No próximo artigo, a conversa é sobre o uso de listas em arquivos CSV.
Até lá!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?