

O formato JSON (Java Script Object Notation) há muito está consolidado no mercado, com muitas ferramentas exportando e consumindo arquivos neste formato.
Por conta disso, muitas vezes precisamos cruzar dados de um arquivo JSON com dados relacionais, por exemplo.
Para esses casos, o SQL Server oferece a função OPENJSON. Neste artigo, apresento alguns exemplos de uso da função em declarações SQL.
Como ler dados JSON
Esta função foi incorporada no SQL Server a partir da versão 2016. Ela permite ler um arquivo JSON e retornar um resultado em formato de tabela. Dessa forma, é possível cruzar dados semiestruturados com dados relacionais.
Porém, é importante observar que ela não lida com coleções de documentos JSON, mas sim com um único arquivo por chamada.
Além disso, deve-se observar também que a base de dados que usa OPENJSON precisa ter nível de compatibilidade 130 ou superior. Caso chame a função numa base de dados mais antiga, receberá uma mensagem de erro como essa:
Msg 208, Level 16, State 1, Line XX
Invalid object name 'OPENJSON'Exemplos de uso
A seguir mostro alguns exemplos de uso da função OPENJSON. Preparei exemplos usando o mesmo arquivo JSON (disponível neste link). Este documento trata de informações de associados de um clube de colecionadores de automóveis.
Os dados tratam do nome do colecionador, idade, cidade onde reside e a descrição dos carros que possui, como marca, cor, ano de fabricação, valor estimado e, por fim, nome e cidade de residência dos proprietários anteriores.
- Um script contendo as declarações SQL de todos os exemplos apresentados neste artigo está disponível neste link.
Exemplo 1 – Consulta simples
A primeira coisa a se entender sobre essa função é que ela não se presta a ler o conteúdo de um arquivo externo. Ela apenas interpreta a estrutura de um documento JSON, com suas marcações (ou tags), valores e vetores (ou arrays).
Por essa razão, na maioria das vezes usaremos OPENJSON precedida da função OPENROWSET: esta lê o arquivo desejado e joga seu conteúdo numa variável, que em seguida será tratada pela função OPENSON.
Veja o exemplo a seguir.
Declaração
--Exemplo 1 : consulta genérica
DECLARE @json AS NVARCHAR(MAX)
SELECT @json = BulkColumn
FROM OPENROWSET (BULK 'C:\TEMP\exemplo.json', SINGLE_CLOB) as Arquivo
SELECT F.* FROM OPENJSON(@json) AS FResultado

Observe que as marcações foram convertidas em campos e que o vetor foi mantido na sua forma original. Além disso, tem-se uma nova coluna “type”, que informa a posição da marcação dentro do documento JSON.
Já temos aqui um avanço, mas este output ainda não é muito útil para manipulação. Seria muito difícil gerar métricas sobre dados neste formato ou cruzá-los com dados relacionais.
Exemplo 2 – Nomeando as marcações como nomes de campos
Neste novo exemplo o problema anterior é facilmente corrigido com o uso da opção WITH (), que permite definir campos, seus tipos de dados e a origem dos dados exibidos. O resultado aqui é uma tabela relacional como outra qualquer.
No exemplo a seguir, resolvi manter os nomes de colunas idênticos aos nomes das marcações. O ponto importante é o mapeamento das colunas usando o identificador ‘$.[NomeDaMarcação]’ de forma apropriada.
Declaração
--Exemplo 2 : nomeando as marcações como nomes de campos
DECLARE @json AS NVARCHAR(MAX)
SELECT @json = BulkColumn
FROM OPENROWSET (BULK 'C:\TEMP\exemplo.json', SINGLE_CLOB) as Arquivo
SELECT F.*
FROM OPENJSON(@json)
WITH (
Colecionador VARCHAR(200) '$.Colecionador',
Idade INTEGER '$.Idade',
Cidade VARCHAR(200) '$.Cidade',
Carros NVARCHAR(MAX) AS JSON
) AS FResultado
![]()
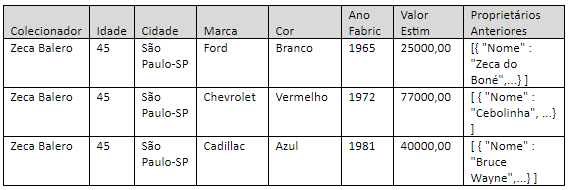
Exemplo 3 – consultando dados dentro de vetores
No exemplo anterior ainda temos um problema. É difícil consultar os dados do vetor “carros”. Isso é resolvido usando o operador CROSS APPLY, que trata este vetor como se fosse independente da estrutura do documento JSON.
Para isso, no exemplo anterior eu já defini de propósito a coluna “Carros”, como “NVARCHAR(MAX) AS JSON”. Veja como fica a declaração SQL.
Declaração
--Exemplo 3 : consultando dados dentro de vetores
DECLARE @json AS NVARCHAR(MAX)
SELECT @json = BulkColumn
FROM OPENROWSET (BULK 'C:\TEMP\exemplo.json', SINGLE_CLOB) as Arquivo
SELECT Raiz.Colecionador, Raiz.Idade, Raiz.Cidade, Carros.*
FROM OPENJSON(@json)
WITH (
Colecionador VARCHAR(200) '$.Colecionador',
Idade INTEGER '$.Idade',
Cidade VARCHAR(200) '$.Cidade',
Carros NVARCHAR(MAX) AS JSON
)AS Raiz
CROSS APPLY OPENJSON ( Raiz.Carros )
WITH (
Marca VARCHAR(50) '$.Marca',
Cor VARCHAR(200) '$.Cor',
AnoFabricacao INTEGER '$.AnoFabricacao',
ValorEstimado MONEY '$.ValorEstimado',
ProprietariosAnteriores NVARCHAR(MAX) AS JSON
) AS CarrosResultado
Exemplo 4 – gerando métricas
Desta vez, o objetivo é gerar métricas sobre os dados do arquivo JSON. As métricas desejadas para o colecionador Zeca Balero são as seguintes:
- Qual é o carro mais antigo da coleção (modelo e ano de fabricação)
- Qual é a quantidade total e o valor médio dos carros
- Idade média dos proprietários anteriores
Para isso, ainda falta converter em colunas as marcações do vetor “ProprietariosAnteriores”. Existem mais detalhes a se considerar, mas primeiro vamos ver os resultados.
Declaração
--Exemplo 4 : gerando métricas
DECLARE @json AS NVARCHAR(MAX)
SELECT @json = BulkColumn
FROM OPENROWSET (BULK 'C:\TEMP\exemplo.json', SINGLE_CLOB) as Arquivo
;WITH cteMetrica (Colecionador, Idade, Cidade, Marca, AnoFabricacao, ValorEstimado,IdadePropAnt)
AS
(
SELECT Raiz.Colecionador, Raiz.Idade, Raiz.Cidade, Carros.Marca,
Carros.AnoFabricacao, Carros.ValorEstimado, PropAnt.Idade
FROM OPENJSON(@json)
WITH (
Colecionador VARCHAR(200) '$.Colecionador',
Idade INTEGER '$.Idade',
Cidade VARCHAR(200) '$.Cidade',
Carros NVARCHAR(MAX) AS JSON
) AS Raiz
CROSS APPLY OPENJSON ( Raiz.Carros )
WITH (
Marca VARCHAR(50) '$.Marca',
Cor VARCHAR(200) '$.Cor',
AnoFabricacao INTEGER '$.AnoFabricacao',
ValorEstimado MONEY '$.ValorEstimado',
ProprietariosAnteriores NVARCHAR(MAX) AS JSON
) AS Carros
CROSS APPLY OPENJSON ( Carros.ProprietariosAnteriores)
WITH (
Nome VARCHAR(200) '$.Nome',
Idade INTEGER '$.Idade',
Cidade VARCHAR(200) '$.Cidade'
) AS PropAnt
WHERE Raiz.Colecionador = 'Zeca Balero'
),
cteMetPropAnt (Colecionador,CarroMaisAntigo, MediaIdadePropAnt)
AS (
SELECT
c.Colecionador
, MIN(c.AnoFabricacao) AS CarroMaisAntigo
, AVG(c.IdadePropAnt) AS MediaIdadePropAnt
FROM cteMetrica c
GROUP BY c.Colecionador
),
cteMetGeral (Colecionador, Idade, Cidade, Contagem, ValorMedio)
AS (
SELECT
T.Colecionador
, T.Idade
, T.Cidade
, COUNT(T.Marca) AS Contagem
, AVG(T.ValorEstimado) AS ValorMedio
FROM (
SELECT DISTINCT
c.Colecionador
, c.Idade
, c.Cidade
, c.Marca
, c.ValorEstimado
FROM cteMetrica c
) T
GROUP BY T.Colecionador, T.Idade, T.Cidade
)
SELECT M1.*, M2.*
FROM cteMetGeral M1
INNER JOIN cteMetPropAnt M2 ON M1.Colecionador = M2.ColecionadorResultado
![]()
O leitor mais atento notará que o arquivo JSON lista vários antigos proprietários para cada automóvel listado. Assim, quando fizemos o CROSS APPLY com o vetor “ProprietariosAnteriores”, nós desnormalizamos os dados, gerando duplicidades que causariam cálculos incorretos.
Por esta razão, essa consulta precisou eliminar essas duplicidades antes de calcular o número total de veículos da coleção e valor médio dos carros.
Este é um ponto importante quando se trabalha com arquivos JSON, visto que, em essência, a existência de vetores dentro da estrutura quase sempre levará a duplicação de informações.
Comentários finais
O objetivo deste trabalho foi apresentar informações introdutórias para manipulação de arquivos JSON dentro do SQL Server. Os recursos aqui mostrados ajudarão o leitor a cobrir grande número de casos de uso de arquivos JSON.
Outros casos mais específicos, como a manipulação de diversos arquivos JSON, podem ser encontrados nas leituras recomendas apresentadas a seguir.
Leituras sugeridas
- Importar documentos JSON para o SQL Server, por MICROSOFT.
- Dados JSON no SQL Server, por MICROSOFT.
- OPENJSON (Transact-SQL), por MICROSOFT.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?