Análise de Grafos no Azure SQL DB

O uso de bancos de dados de grafos continua crescendo rapidamente, mas ainda assim a grande maioria dos profissionais de TI desconhece os conceitos envolvidos. Hoje existem vários produtos desta categoria, tais como Azure Cosmos Gremlin API e NEO4J (clique aqui para informações sobre o mercado de bancos de dados de grafos). E existem também soluções híbridas, como é o caso do SQL Server e Azure SQL DB, que oferecem uma extensão para uso de grafos dentro de uma base originalmente relacional.
Em 2020, publiquei aqui no iMasters uma série de artigos abordando os conceitos básicos sobre este tema (veja link). Recentemente, voltei ao tema dos grafos apresentando uma palestra no DBA BRASIL Data & Cloud. O presente artigo é uma extensão dessa palestra. Dessa vez apresento a comparação de dois modelos da mesma base de dados, o primeiro construído como modelo relacional e o outro criado como um modelo de grafos.
Conceito de Grafos
Basicamente, modelos de grafos se destinam a analisar relações complexas entre entidades. A expressão “relações complexas” faz toda a diferença quando se compara modelos relacionais com modelos de grafos. Bases relacionais também lidam com relações, como o próprio nome diz. Mas as entidades (i.e., suas tabelas) se relacionam com um número limitado de outras entidades: 05, 10, raramente mais que 20 relacionamentos.
No modelo de grafos, a diferença é a escala. O objetivo é analisar milhões de relações. Pense, por exemplo, em redes sociais: você se relaciona com centenas de outras pessoas, que por sua vez se relacionam com outras centenas de pessoas e assim por diante. E o tipo de relacionamento pode mudar: algumas pessoas são seus familiares, outros amigos e outros colegas de trabalho. (Veja Figura 01).
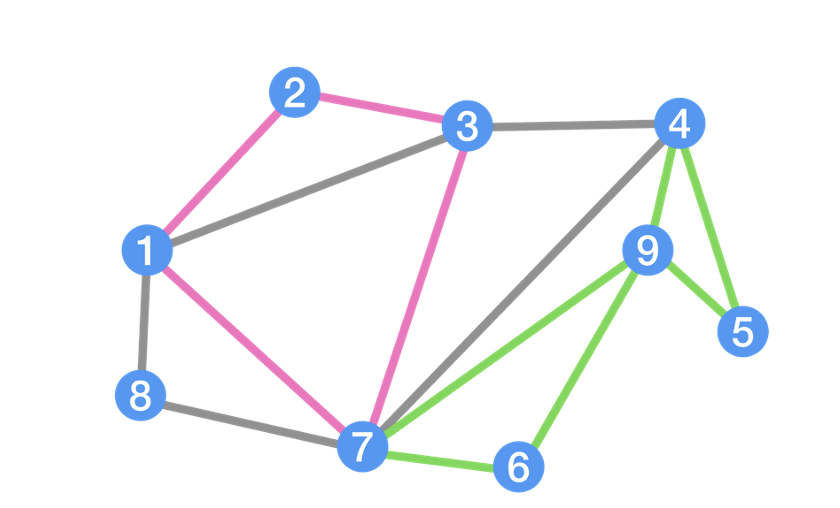
Figura 01: grafo de 01 entidade com 09 elementos e 03 tipos de relacionamento
Um fato interessante é que, à medida que cresce o número de elementos em cada entidade, a quantidade de relacionamentos cresce exponencialmente. E aí as coisas se complicam para uma análise usando modelos relacionais.
Grafos e Azure SQL
A extensão do T-SQL para trabalhar com grafos já existe tanto para instalações on-premises como para a nuvem desde o SQL Server 2017.
Como as sintaxes usadas para construir e consultar dados são muito parecidas com qualquer consulta SQL, eu entendo que este recurso é uma porta de entrada interessante para o mundo dos grafos.
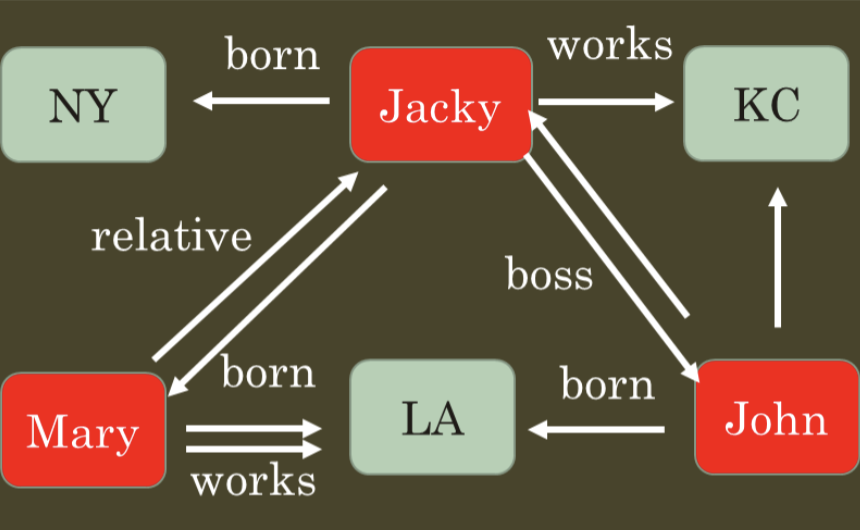
Um exemplo simples: considere o modelo da Figura 02.
Figura 02: modelo de grafos entre pessoas e cidades
Este modelo tem 02 entidades, Pessoa e Cidade, cada um deles com 03 elementos. Chamamos as tabelas de entidades de NÓS (ou NODE, em inglês).
Estes dois nós se relacionam de diferentes formas, que são descritas nas tabelas de BORDA (ou EDGE, em inglês).
Assim, nosso modelo de grafos seria criado com a seguinte estrutura:
| NODES (entidades) | EDGES (relacionamentos) |
| · Pessoa (Jacky, Mary, John)
· Cidade (NY, LA, KC)
|
|
Observe que o modelo tem 03 bordas (edges) que envolvem os nós “Pessoa” e “Cidade” e outras 02 bordas que envolvem autorrelacionamento do nó “Pessoa”.
É hora de avaliar um caso mais elaborado.
Estudo de Caso
Para este estudo, eu escolhi um modelo com dados sobre a Copa do Mundo de 2022. Este modelo contém:
• 032 países classificados para o evento
• 064 jogos que aconteceram
• 008 estádios
• 831 jogadores inscritos
• 296 clubes
Vale dizer que dados envolvendo números dessa ordem favorecem o modelo relacional. Como poucos elementos envolvidos, tanto o modelo relacional como o de grafos vão trabalhar adequadamente.
Sobre a criação dos modelos, vamos começar com o modelo relacional. Figura 03 apresenta este modelo.

Figura 03: modelo relacional para Copa do Mundo 2022
O modelo de grafos para os mesmos dados está disponível na Figura 04. Veja que as bordas estão representadas pelos relacionamentos entre entidades.
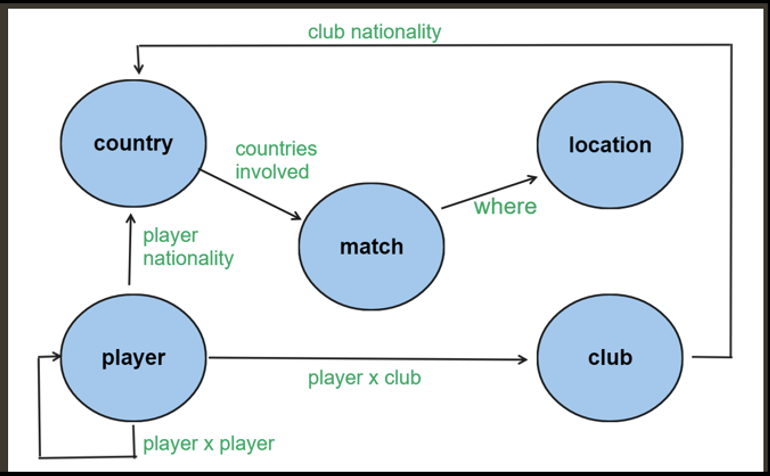
Figura 04: modelo de grafos para Copa do Mundo 2022
Para os interessados em conferir esta demo em detalhe, eu compartilho o script para criação desses modelos (assim como os dados envolvidos) está disponível no GitHub.
Sobre a Construção dos Modelos
A implementação do modelo relacional não apresenta nenhum desafio. Basta checar o script que mencionei acima.
Em relação ao modelo de grafos, a sintaxe é bastante simples, como se vê no quadro a seguir:
| CREATE SCHEMA node
GO CREATE SCHEMA edge GO — nodes CREATE TABLE node.club ( clubID INTEGER NOT NULL PRIMARY KEY , club VARCHAR(100) ) AS NODE GO … CREATE TABLE edge.playerXclub ( status VARCHAR(10) DEFAULT ‘CURRENT’ ) AS EDGE GO |
Na criação do nó “Club”, basicamente a única diferença em relação à declaração de tabela relacional é a declaração “AS NODE”. Como veremos adiante, esta declaração garante a inclusão automática de metadados a respeito destes grafos.
Na criação da tabela de borda “playerXclub”, que trata de jogares e seus clubes de origem, inclui-se a declaração “AS EDGE”. Novamente, esta declaração garante que metadados serão adicionados a cada novo registro inserido na tabela.
Um detalhe interessante é que eu adicionei um atributo para a relação entre jogares e seus clubes: “status”, que permitirá que meu modelo suporte dados históricos da passagem do dos clubes por onde o jogador passou. Na verdade, isso não existe na minha amostra depor outros times. Meus dados. Portanto não incluem esta informação, portanto eu poderia criar essa tabela de borda sem nenhum atributo.
Parece estranho para quem está acostumado com o modelo relacional, mas é possível criar tabelas de borda sem nenhum campo. Parando para pensar do ponto de vista dos grafos, isso faz sentido. No modelo grafos, as bordas se propõem a definir a relação entre duas entidades. Então o que interessa de fato são os metadados que são gravados ali.
Veja o exemplo da tabela de borda “playerXcountry”. Mesmo que um jogador mude sua nacionalidade, ela não poderá mais jogar na seleção de outro país. Então, no nosso estudo, não há necessidade manter este histórico. E a relação não precisa de atributos, como mostra o quadro.
| CREATE TABLE edge.playerXcountry
AS EDGE GO |
Carga de Dados
Mais uma vez, passo direto para o modelo de grafos para falar de inserção de dados. Esta tarefa muitas vezes exige atenção especial, particularmente no caso dos dados de borda.
Começo pela parte mais simples, a carga de dados para os nós.
Veja a seguir o exemplo para a tabela de clubes, em que trago dados da tabela relacional para a tabela de nó.
| –nodes
INSERT INTO node.club SELECT clubID , name FROM relational.club GO SELECT TOP 5 * FROM node.club WHERE club LIKE ‘B%’ |
||||||||||||||||||
|
Observe que esta operação adicionou a coluna de metadados “$node_id”. Esta coluna é criada em todos os nós, cada uma com o nome “$node_id” seguido de um identificador alfanumérico como, no quadro anterior.
Agora o exemplo de carga da tabela de borda que lida com jogadores e seus clubes.
| INSERT INTO edge.playerXclub
SELECT NP.$node_id , NCL.$node_id, status = ‘CURRENT’ FROM node.player NP INNER JOIN relational.player RP ON NP.playerID = RP.playerID INNER JOIN node.club NCL ON RP.clubID = NCL.clubID
SELECT TOP 5 * FROM edge.playerXclub |
||||||||||||||||||||||||
|
Aqui temos três colunas de metadados, que vão existir em toda tabela de borda. A coluna 1, “$edge_id”, mostra o identificador do registro daquela relação, seguido de uma coluna “$from_id” para outra “$to_id”.
Isso evidencia um ponto fundamental das relações representadas nas tabelas de borda. Elas têm direção. Ela diz que o “jogador X“ joga no “clube Y”. Nas suas consultas, você obrigatoriamente terá que ter isso em mente.
Uma Caso Especial De Carga de Dados
Nessa minha demo, todos os nós e bordas são bem elementares. Exceto um caso: o que trata a relação entre jogadores.
O modelo especifica que o jogador joga na seleção de seu país, mas ele também joga num clube. Então temos parceiros de seleção e parceiros do clube.
Para carregar estes dados, temos que buscar informação por dois caminhos distintos. Mas tem dois agravantes:
1. Devo excluir uma “relação” entre o jogador e ele próprio
2. Se eu jogo na seleção com um jogador que também joga comigo no meu clube, não posso contar isso como duas relações.
Adotei como critério que a relação na seleção prevalece. Então a carga de dados tem que fazer a união dos dados que vem de seleções e clubes, e excluir da lista dos clubes os jogadores que já foram computados na seleção. Eu usei aqui a cláusula EXCEPT para resolver este problema. O resultado está no quadro a seguir.
| ;
WITH ctePlayerNationalTeam AS ( SELECT P1 = NP1.$node_id , P2 = NP2.$node_id, source = ‘national team’ FROM node.player NP1 INNER JOIN node.player NP2 ON NP1.countryID = NP2.countryID WHERE NP1.player <> NP2.player )
INSERT INTO edge.playerXplayer SELECT * FROM ctePlayerNationalTeam UNION SELECT NP1.$node_id , NP2.$node_id, source = ‘club’ FROM node.player NP1 INNER JOIN node.player NP2 ON NP1.clubID = NP2.clubID WHERE NP1.player <> NP2.player EXCEPT ( SELECT NP1=C.P1, NP2=C.P2, source = ‘club’ FROM ctePlayerNationalTeam c ) |
Consultando os Dados
Como o leitor já observou nos exemplos acima, a execução de um SELECT sobre tabelas de nós e de borda não apresenta nenhuma novidade.
O que muda é que não se usa o operador JOIN para consultar dados de múltiplas tabelas de grafos. O correto é usar o operador MATCH na cláusula WHERE. (Não confundir a palavra “match”, jogo, usada na definição das tabelas).
Exemplo 1: identificar quem era o time mandante de cada partida e quantos gols ele marcou. Veja no quadro as sintaxes para modelo relacional e modelo de grafos.
| 01
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 |
–relational
SELECT m.matchID, m.matchDate, G.name AS [group], R.name [round], m.homeTeam, m.homeGoal FROM relational.worldcupmatch M INNER JOIN relational.country C ON M.homeTeam = C.countryID INNER JOIN relational.worldcupgroup G ON M.groupID = G.groupID INNER JOIN relational.worldcupround R ON M.roundID = R.roundID
–graph SELECT m.matchID, m.matchDate, m.[group], m.round, C1.country , M.homeGoal FROM node.country C1 , edge.matchXcountry MC1 , node.worldcupmatch M WHERE MATCH (M – (MC1)-> C1) — <============== AND MC1.teamStatus = ‘home’ |
A linha 15 mostra como definir a combinação das tabelas de nós com a de borda. Como a relação foi definida de jogo para país (matchXcountry), a direção do relacionamento foi escrita como
WHERE MATCH (M – (MC1)-> C1)
Mas eu poderia também escrever este “match” na forma inversa, obtendo o mesmo resultado:
WHERE MATCH (C1 <- (MC1)- M)
Uma vez entendido este princípio, fica fácil escrever consultas mais elaboradas. Esse é o caso tratado no Exemplo 2.
Exemplo2: lista de jogos completa (time mandantes e visitantes HOME + AWAY)
| 01
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 |
–relational
SELECT M.matchID, m.matchDate, G.name AS ‘group’, R.name AS round, score = M.homeTeam + ‘ ‘+ CAST( M.homeGoal AS VARCHAR(2)) + ‘ x ‘ + CAST( M.awayGoal AS VARCHAR(2)) + ‘ ‘ +M.awayTeam FROM relational.worldcupmatch M INNER JOIN relational.worldcupgroup G ON M.groupID = G.groupID INNER JOIN relational.worldcupround R ON M.roundID = R.roundID
— graph SELECT M.matchID, m.matchDate, m.[group], m.round, score = C1.country + ‘ ‘ + CAST(M.homeGoal AS VARCHAR(2)) + ‘ x ‘ + CAST( M.awayGoal AS VARCHAR(2)) + ‘ ‘ + C2.country FROM node.country C1 , edge.matchXcountry MC1 , node.worldcupmatch M , node.country C2 , edge.matchXcountry MC2 WHERE MATCH (C1 <- (MC1)- M – (MC2) -> C2) AND MC1.teamStatus = ‘home’ AND MC2.teamStatus = ‘away’
|
|||||||||||||||||||||||||||||||||||
|
Veja que agora usamos duas vezes a relação entre jogo e país: uma quando o status é “home” (time mandante) e outra quando é “away” (time visitante).
O operador ficou mais complexo, mas é só à primeira vista. Basta observar as direções de cada relacionamento:
WHERE MATCH (C1 <- (MC1)- M – (MC2) -> C2)
A primeira relação, em amarelo, (M com C1) representa o time mandante (MC1.teamStatus = ‘home’)
A segunda, destacada em azul, (M com C2) representa o time visitante (MC2.teamStatus = ‘away’)
Estes exemplos ajudam a entender a sintaxe, mas não mostram o verdadeiro poder dos grafos. Nestes exemplos, não é de se esperar melhoria de performance com uso de grafos, especialmente com este volume de dados tão pequeno.
Fazendo a Diferença
Existem análises que são simplesmente complexas demais para se fazer com modelos relacionais.
Um caso clássico são as pesquisas do tipo “caminho mais curto”. Imagine que você pretende fazer uma viagem aérea e não exista um voo direto disponível. Qual a combinação de voos você deve escolher para ter o menor preço ou o menor tempo entre partida e chegada?
Outro exemplo: como o LINKEDIN identifica o “grau de separação” entre você e qualquer outro usuário? Seus contatos diretos são contatos de 1º grau. Contatos dos seus contatos são apresentados para como você como sendo de 2º grau e assim por diante.
O T-SQL oferece a função SHORTEST_PATH para resolver estas questões.
O próximo exemplo estuda este cenário.
Exemplo 3: classificar relacionamento entre 1 jogador e demais atletas, baseado nas seleções e clubes em que jogam. Como exemplo, considerei a rede de contatos de Lionel Messi.
Contatos que jogam na mesma seleção ou clube são contatos de 1º grau.
Jogadores que jogam com alguém que joga com Messi são de 2º grau.
Contatos de 3º grau são jogadores que jogam com alguém q joga com outro alguém que joga com Messi, e a mesma lógica vale para os casos seguintes.
Vamos começar com a declaração relacional. Não é difícil identificar os contatos de primeiro grau, mas na lista dos jogadores de 2º grau precisam ser excluídos aqueles que já são contatos de 1º grau e isso se repete para os demais níveis.
Esta declaração começou a ficar complexa demais já no segundo nível e eu parei aí. O quadro a seguir mostra esta declaração.
| 01
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74
|
–relational
DECLARE @player VARCHAR(200) = ‘MESSI’ ; WITH cteP0 AS ( SELECT Player0 = P0.fullName + ‘ (‘ + P0.countryID + ‘)’ FROM relational.player P0 WHERE P0.shirtName = @player ) , cteP1 AS ( SELECT Player = P1.fullName + ‘ (‘ + P1.countryID + ‘)’ , GRAU = 1 , PathTo = P0.Player0 + ‘==>’ + P1.fullName + ‘ (‘ + P1.countryID + ‘)’ , fullName1 = P1.fullName , countryID1 = P1.countryID , clubID1 = P1.clubID FROM cteP0 P0, relational.player P1 INNER JOIN relational.country CO1 ON P1.countryID = CO1.countryID WHERE P1.countryID = (SELECT countryID FROM relational.player WHERE shirtName = @player) AND P1.shirtName <> @player UNION SELECT Player = P1.fullName + ‘ (‘ + P1.countryID + ‘)’ , GRAU = 1 , PathTo = P0.Player0 + ‘==>’ + P1.fullName + ‘ (‘ + P1.countryID + ‘)’ , fullName1 = P1.fullName 2 , countryID1 = P1.countryID , clubID1 = P1.clubID FROM cteP0 P0, relational.player P1 INNER JOIN relational.club CL1 ON P1.clubID = CL1.clubID WHERE P1.clubID = (SELECT clubID FROM relational.player WHERE shirtName = @player) AND P1.shirtName <> @player AND P1.countryID <> (SELECT countryID FROM relational.player WHERE shirtName = @player) )
— 2o GRAU: necessário excluir jogadores que já foram classificados como ‘1o GRAU’ , cteP2 AS ( — 1o select: contato de 1o grau na seleção nacional, contato de 2o grau no clube SELECT Player = P2.fullName + ‘ (‘ + P2.countryID + ‘)’ , GRAU = 2 , PathTo = P0.Player0 + ‘==>’ + CP1.fullName1 + ‘ (‘ + CP1.countryID1 + ‘)’ + ‘==>’ + P2.fullName + ‘ (‘ +P2.countryID + ‘)’ FROM cteP0 P0, cteP1 CP1 INNER JOIN relational.player P2 ON CP1.clubID1 = P2.clubID WHERE P2.shirtName <> @player AND P2.fullName NOT IN (SELECT fullName1 FROM cteP1) UNION — 2o select: contato de 1o grau na clube, contato de 2o grau no clube SELECT Player = P2.fullName + ‘ (‘ + P2.countryID + ‘)’ , GRAU = 2 , PathTo = P0.Player0 + ‘==>’ + CP1.fullName1 + ‘ (‘ + CP1.countryID1 + ‘)’ + ‘==>’ + P2.fullName + ‘ (‘ +P2.countryID + ‘)’ FROM cteP0 P0, cteP1 CP1 INNER JOIN relational.player P2 ON CP1.clubID1 = P2.clubID WHERE P2.shirtName <> @player AND P2.fullName NOT IN (SELECT fullName1 FROM cteP1) ) SELECT GRAU, Player, PathTo FROM cteP1 UNION SELECT GRAU, Player,PathTo FROM cteP2 go |
A consulta equivalente, usando a função SHORTEST_PATH e o modelo de grafos, sem limite de níveis, é mostrada a seguir.
| 01
02 03 04 05 06 07 08 09 10 11 12 |
— graph
DECLARE @player VARCHAR(200) = ‘MESSI’ SELECT Player = NP1.player , GRAU = COUNT(NP2.Player) WITHIN GROUP (GRAPH PATH) , PathTo = NP1.player + ‘ ==> ‘ + STRING_AGG(NP2.Player, ‘ ==> ‘) WITHIN GROUP (GRAPH PATH) , Player2 = LAST_VALUE(NP2.Player) WITHIN GROUP (GRAPH PATH) FROM node.player NP1 , edge.playerXplayer FOR PATH AS EPP , node.player FOR PATH AS NP2 WHERE MATCH(SHORTEST_PATH(NP1(-(EPP)->NP2)+)) AND NP1.shirtName = @player |
||||||||||||||||||||||||
|
No meu teste, a consulta relacional, retornando só os contatos de 1º e 2º grau (relacionamento com 182 jogadores), demorou 03 segundos.
A de grafos, cobrindo todos os 831 jogadores da copa e sem limite de níveis, levou os mesmos 03 segundos.
Comentários Finais
Grafos são uma ferramenta importante de análise de dados e permitem pesquisas praticamente impossíveis no modelo relacional.
E, como mostrei aqui, não requer grande esforço para sua implementação.
Três pontos que me parecem importantes ter em mente quando começar seu projeto:
• Esteja atento à carga dos dados para reproduzir fielmente seus relacionamentos
• Avalie a direção mais adequada para construção do seu modelo
• Preocupe-se em definir relacionamentos que sejam realmente úteis.
Este artigo é apenas uma introdução ao tema de grafos e, como eu disse anteriormente, Azure SQL ou SQL Server são portas de entrada para este mundo. Espero ter conseguido convencê-lo a conhecer mais sobre o assunto.
Até a próxima!
*O conteúdo deste artigo é de responsabilidade do(a) autor(a) e não reflete necessariamente a opinião do iMasters.
Consultor Sênior na Microsoft, na área de Data Insights para América Latina. Especialista em bancos de dados, é colunista em diversos portais de TI do Brasil e do exterior, com mais de 100 artigos técnicos publicados. É também co-produtor do DatabaseCast, primeiro podcast brasileiro sobre bancos de dados.