Bate-bola com Grafos e SQL Server Parte 1 – Definindo o Modelo
É espantosa a popularização que as novas tecnologias de dados alcançaram. A utilização de Grafos para análise de dados e o SQL Server…


É espantosa a popularização que as novas tecnologias de dados alcançaram na última década. Uma das mais bacanas é a utilização de Grafos para análise de dados, apesar de ela não ser propriamente uma tecnologia nova.
Teoria dos Grafos é um ramo da matemática inventado por Leonhard Euler há quase 300 anos! Seu foco é a análise de relações (complexas) entre entidades.
Você pode dizer que um banco relacional também trata de objetos relacionados, mas nele sempre haverá um número pequeno de relações diretas entre um objeto e seus pares.
Não é comum encontrar um modelo relacional em que uma tabela se relacione diretamente com mais que 10 outras tabelas. Mas quando pensamos, por exemplo, nos relacionamentos entre pessoas numa rede social, os números rapidamente passam dos milhares.
Portanto, mesmo que dados relacionais e grafos trabalhem com os mesmos princípios (entidades e relacionamentos), eles claramente ocupam nichos distintos. O primeiro trata de relações simples, enquanto os grafos são úteis nos casos em que se trabalha com relações complexas entre entidades.
Existe inclusive um jogo chamado “Seis Graus de Separação” que alega que você pode rastrear uma rede de relacionamentos de você até qualquer pessoa do planeta envolvendo, no máximo, outras seis pessoas.
Em outras palavras, seis relacionamentos. A primeira vez que ouvi falar disso foi nos anos 90, numa matéria da
revista DISCOVER MAGAZINE. É uma pena que não consegui encontrá-lo no site da revista
Nesta série, mostro como implementar Grafos usando T-SQL, ou seja, apresento códigos, conceitos e funcionalidades para criação de grafos nos seguintes SGBDs:
- MICROSOFT SQL Server 2017 ou superior (on-premises)
- MICROSOFT PARALLEL DATA WAREHOUSE (on-premises)
- AZURE SQL DATABASE (nuvem)
- AZURE SYNAPSE ANALYTICS (nuvem)
Para fins de exemplo, escolhi uma massa de dados disponível no KAGGLE que trata de resultados de jogos de ligas europeias de futebol entre as temporadas de 2008 e 2015, a European Soccer Database, compartilhada por Hugo Mathien.
Entendendo o Modelo
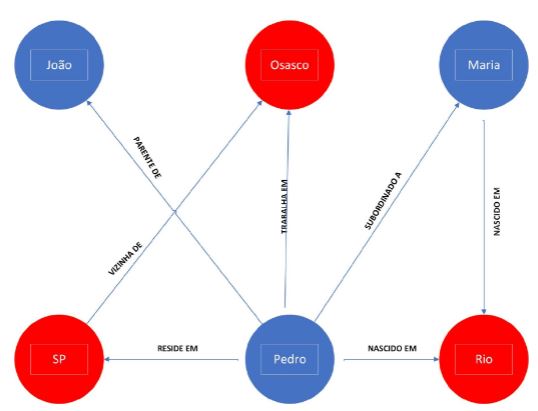
O diagrama a seguir apresenta um grafo, envolvendo 02 tipos de entidade, diferenciadas por cores, com 03 elementos diferentes em cada uma. Apresenta também 06 tipos de relacionamentos, que são identificados por rótulos.
Perceba que a entidade “PEDRO”, por exemplo, se relaciona com todos os outros nós através de diferentes relações, com exceção da relação “VIZINHA DE”, que se refere exclusivamente a cidades.
Quando trabalhamos com grafos, o foco passa a ser nos elementos de cada entidade, os chamados nós (do inglês “nodes”). Estes nós podem ou não ter atributos associados a eles, dependendo da sua necessidade.
Outro elemento essencial são as bordas (do inglês “edge”), que definem os relacionamentos que existem entre estes
nós. Observe ainda que as relações têm direção: uma relação é definida de “A” para “B”. Isso será muito importante na hora de definir o modelo e de executar as consultas.
Para implementar grafos com T-SQL, são necessárias pequenas adaptações nos modelos físico e lógico da base de dados. Assim criamos N tabelas de entidades, contendo todos os nós e atributos referentes a cada entidade. Em seguida criamos M tabelas de bordas, que definem os tipos de relacionamento analisados, informando
que nós estão envolvidos nesta relação.
Esta estrutura permite armazenar os dados fisicamente de forma muito parecida com os dados relacionais. Ao mesmo tempo, ela nos dá a flexibilidade de analisá-los da maneira desejada, já que o modelo lógico os representa como verdadeiros grafos.
Detalhe importante: os especialistas alertam que a definição do modelo do grafo está intimamente ligada ao tipo de consultas que se deseja fazer. Em outras palavras, a escolha das bordas, nós e atributos de um modelo pode ser diferente conforme o tipo de consultas que serão feitas sobre estes grafos.
Exemplo de Modelagem
Isto posto, vamos criar nosso modelo de grafos. Meu objetivo é analisar as interações entre jogadores, times e resultados das partidas disputadas em diversas ligas europeias durante o período estudado. O modelo relacional desta base é apresentado a seguir.
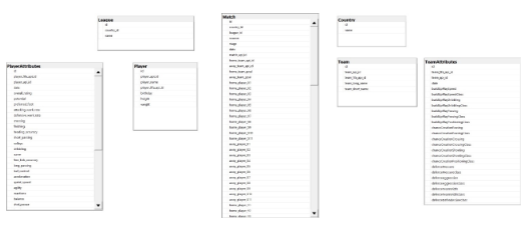
OBSERVAÇÃO: a massa de dados original foi compartilhada no KAGGLE como uma base do SQLITE. No entanto, a movimentação destas tabelas para o SQL Server 2019 é um processo tradicional que pode ser feito de inúmeras formas, inclusive como movimentação de arquivos CSV. Sendo assim, não me importei em detalhar as
operações desta etapa.
Uma vez disponíveis os dados relacionais, é necessário definir como serão os grafos utilizados. Para isso, preciso definir quais tabelas de nós e de bordas serão criadas e quais os atributos de cada uma delas.
A intenção do meu modelo é analisar as interações entre jogadores, times e partidas ocorridas. Para ser mais explícito: pretendo analisar interações entre jogadores (quem jogou no mesmo time, quem foi adversário), entre jogadores e times, entre jogadores e as partidas ocorridas (se ele jogou ou não), entre os times que jogaram entre si e entre times e as partidas que jogaram.
À primeira vista, é um modelo bem simples. Porém as relações entre estas entidades crescem muito rapidamente e este é o problema que os grafos procuram resolver. Veja só algumas contas: num torneio com 20 equipes que jogam 38 rodadas envolvendo 22 jogadores.
A base em estudo contém dados de 11 ligas por 8 temporadas. Teoricamente, isso representaria cerca de 1,5 milhão de combinações. Porém os times mudam de escalação de jogo para jogo, cada equipe seleciona seus 11 titulares dentro um grupo que tem em média 35 jogadores, o que torna mais difícil estimar o número real de combinações.
Considerando os tipos de análise que quero executar, defini o modelo com 03 nós e 03 bordas, a saber:
- Nó TIME (team): equipe que participa do torneio
- Nó JOGADOR (player): associado ao time
- Nó PARTIDA (match): traz dados dos confrontos dentro do torneio
- Borda TIMES ENVOLVIDOS (TeamsInvolved): identifica relação entre as partidas e as equipes participantes
- Borda JOGADORES ENVOLVIDOS (PlayersInvolved): identifica jogadores que participaram de cada partida.
- Borda JOGANDO JUNTOS (PlayingTogether): identifica diretamente os jogadores que entraram em campo por uma mesma equipe.
Informações relevantes que serão usadas apenas como filtros foram incluídas no modelo como atributos. Por exemplo: dia do aniversário, altura e peso do jogador foram incluídos como atributos no nó JOGADORES (players), porque se espera que eles não mudem de uma partida para outra.
Em contrapartida, o time pelo qual ele jogou, se era do time local ou visitante e qual o número da camisa do jogador foram incluídos na borda JOGADORES ENVOLVIDOS (PlayersInvolved), porque são atributos do jogador que podem variar de uma partida para a outra. Ao final, cheguei no seguinte modelo:
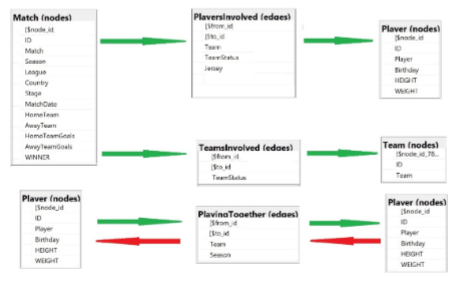
Devido à natureza das pesquisas que pretendo fazer usando a borda JOGANDO JUNTOS (PlayingTogether), precisei definir o relacionamento como se ele fosse bidirecional. Na prática, não existe este conceito no T-SQL e, portanto, o que pretendo fazer de fato é carregar dados considerando as duas direções (de “A” para “B” e de “B” para “A”). Este é um tópico que tratarei no próximo artigo.
Comentários Finais
Neste primeiro artigo da série, apresentei a definição de um modelo de grafos para analisar partidas de futebol. No próximo artigo, apresentarei a implementação deste modelo no SQL Server 2019 e como funcionam as consultas sobre estes dados.
Leituras Sugeridas
1. SQL Graph Architecture por MICROSOFT.
2. Graph processing with SQL Server and Azure SQL Database por
MICROSOFT.
3. European Soccer Database por Hugo Mathien @KAGGLE
4. Graph Databases for Beginners por Roberto Zicari (série de 5 artigos).
5. A Skeptics Guide to Graph Databases por David Bechberger
Consultor Sênior na Microsoft, na área de Data Insights para América Latina. Especialista em bancos de dados, é colunista em diversos portais de TI do Brasil e do exterior, com mais de 100 artigos técnicos publicados. É também co-produtor do DatabaseCast, primeiro podcast brasileiro sobre bancos de dados.