Agrupando Dados com GROUPING SETS
SQL Server: Chega ser estranho pensar que trabalhemos com tanta frequência com sumarização de dados e ainda assim a opção GROUPING SETS seja desconhecida


Chega ser estranho pensar que trabalhemos com tanta frequência com sumarização de dados e ainda assim a opção GROUPING SETS seja uma ilustre desconhecida para a maioria dos mortais.
Uma explicação provável é que pouca gente entende de fato o seu potencial e, por esta razão, ela seria relegada ao segundo plano no mundo dos desenvolvedores de bancos de dados.
Pode até parecer à primeira vista que os GROUPING SETS sejam facilmente substituíveis por operadores mais antigos como os ROLLUP e CUBE. Mas é exatamente aí que você se engana ?.
SQL Server
Relembrando os Operadores ROLLUP e CUBE
Os operadores ROLLUP e CUBE existem no T-SQL desde as primeiras versões do SQL Server. Ambos funcionam em conjunto com a cláusula GROUP BY e a funcionalidade dos dois é bem parecida:
GROUP BY […] WITH ROLLUP: acrescenta à listagem de sumarização os totais parciais calculados da esquerda para direita. Se a consulta fizer um agrupamento sobre uma única coluna, o ROLLUP acrescenta o total geral para esta coluna. Quando são duas colunas, acrescenta o total geral e mais o total geral para cada valor da coluna 1, como mostra a imagem a seguir.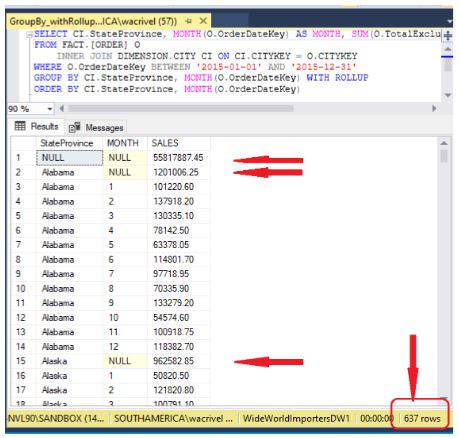
GROUP BY […] WITH CUBE: a diferença do CUBE é que ele acrescenta à listagem todas as possíveis combinações de totais parciais relacionadas aos valores distintos de cada coluna de agrupamento. A figura mostra esta ideia. Observe que existem mais linhas de totais parciais neste relatório, que são os totais por Mês
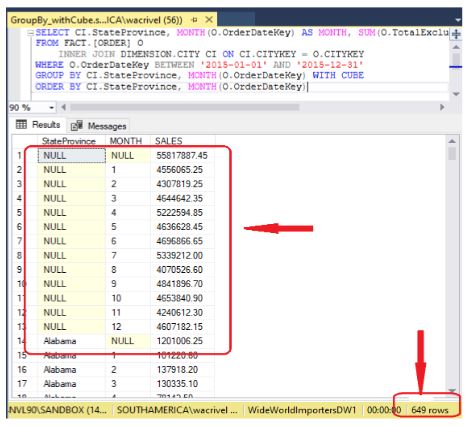
Enquanto trabalhamos com 2 colunas, é tudo muito simples. Com 3 colunas agrupadas, a complexidade é consideravelmente maior e ela cresce exponencialmente à medida que se acrescentam novas colunas. Não é raro que relatórios com 4 ou mais colunas se tornem tão complexos e lentos que simplesmente inviabiliza o uso destes operadores.
Os Desconhecidos GROUPING SETS
Apesar de pouco conhecida, esta opção da cláusula GROUP BY faz parte do padrão ANSI SQL 2006 e existe no SQL Server desde a versão SQL 2008! E ela é realmente bem fácil de usar.
A forma mais simples de explicar os GROUPING SETS é comparando-os com os operadores ROLLUP e CUBE. E a vantagem de usá-los está exatamente no controle que eles nos dão sobre o cálculo de totais parciais. Em outras palavras, você pode facilmente criar um relatório parecido com os que geramos com operadores ROLLUP e CUBE, mas GROUPING SETS permite que você tenha controle sobrequais totais parciaisserãocalculados.
Assim, a utilidade dos GROUPING SETS costuma aparecer apenas quando se trabalha com relatórios mais complexos. Para começar, vamos reescrever as consultas com ROLLUP e com CUBE para usar GROUPING SETS na geração de relatórios idênticosaos anteriores.
Sua sintaxe básica é esta:

Exemplo 1: GROUPING SETS substituindo operador ROLLUP
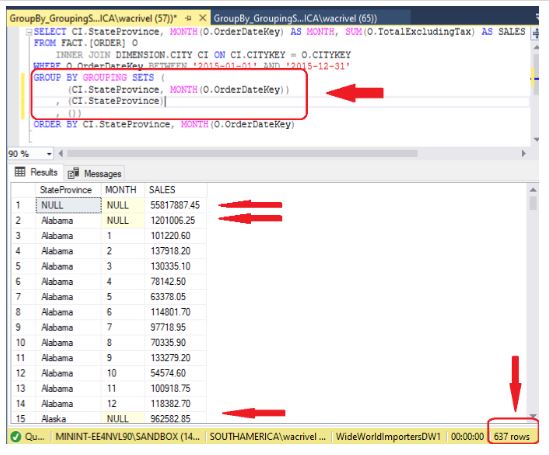
Observe que, para simularmos os subtotais exibidos em um ROLLUP, precisamos informar um set com a combinação das colunas de GROUP BY (Estado vs Mês), um set com os subtotais para a primeira coluna do GROUP BY (Estado) e um terceiro set com o consolidado geral (que é expresso como um set vazio).
A declaração SQL e o relatório gerado são apresentados a seguir.
Exemplo 2: GROUPING SETS substituindo operador CUBE
Para simular o resultado de um operador CUBE em um relatório de 2 dimensões, só precisamos acrescentar mais um set, com os subtotais da coluna Mês.
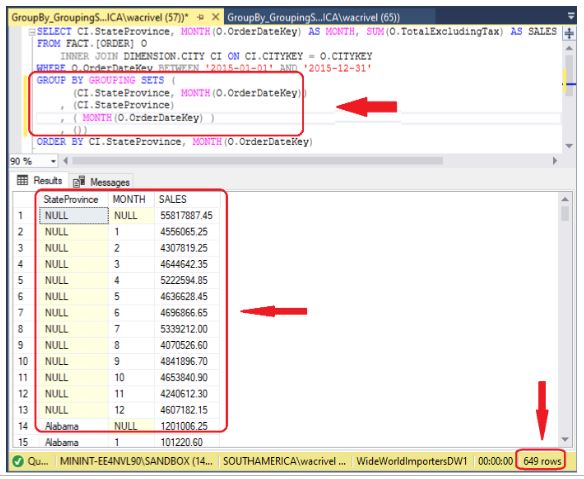
Exemplo 3: GROUPING SETS exibindo total geral e os subtotais da coluna 1.
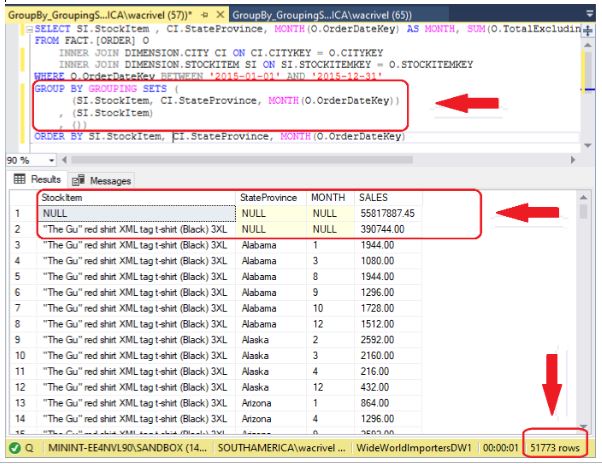
Considere, neste caso, que temos um relatório com 03 colunas sumarizadas, que são Produto, Estado e Mês. Queremos exibir só os totais parciais por Produto, mais o total geral.
Acontece que um relatório de 03 colunas é muito mais complexo do que os que vimos até aqui. Existe um número muito maior de combinações entre as colunas, além de que o tamanho do relatório dependerá da quantidade de itens distintos existem em cada uma das três colunas.
Considere um relatório com as colunas Produto, Estado e Mês. Tecnicamente, teremos os seguintes “sets” possíveis:
(Produto, Estado, Mês): nível do GROUP BY
(Produto, Estado): subtotais desta combinação de colunas
(Produto, Mês): subtotais desta combinação de colunas
(Estado, Mês): subtotais desta combinação de colunas
(Produto): subtotais desta coluna isolada
(Estado): subtotais desta coluna isolada
(Mês): subtotais desta coluna isolada
(): total geral
Se cada uma destas três colunas tivesse só 10 elementos distintos, o relatório todo teria ((10 x 10 x 10) + (10 x 10) + (10 x 10) + (10 x 10) + (10) + (10) + (10) + (1)), ou seja, 1331 linhas. Acontece que, no mundo real, geralmente as colunas tem muito mais do que apenas 10 elementos distintos ?.
Se você achou este relatório complexo, faça as contas para outro relatório com 04 colunas agrupadas. Agora sim você está pronto para entender a vantagem de se usar GROUPING SETS!
Retomando o exemplo, neste relatório 03 colunas agrupadas, queremos apenas os resultados do GROUP BY normal, mais os subtotais de produto e total geral. Com GROUPING SETS a solução é muito simples. Observe que mesmo mostrando só os subtotais por Produto, este relatório já chega 51.773 linhas. (Apenas para comparar, o mesmo relatório com o operador CUBE tem 65.462 linhas)!
GROUPING SETS e Performance
Uma característica especialmente interessante dos GROUPING SETS é que o custo de execução da consulta é proporcional à quantidade de subtotais solicitados. Portanto o “engine” do SQL Server é suficientemente esperto para calcular apenas o que é necessário.
Veja estes 03 exemplos:
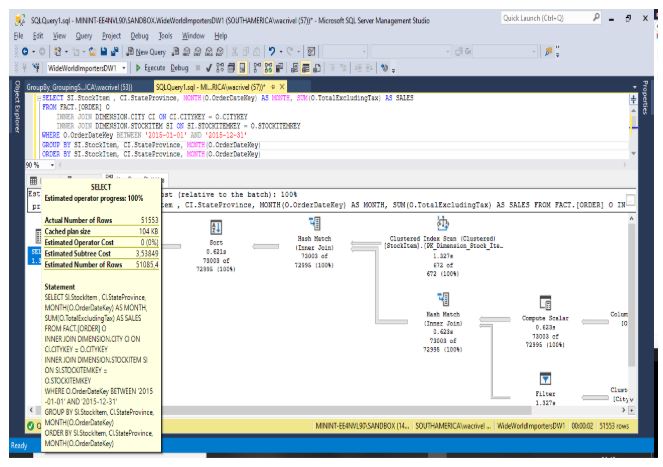
Caso 1: Plano de Execução para um GROUP BY simples
Custo total é de 3,53849
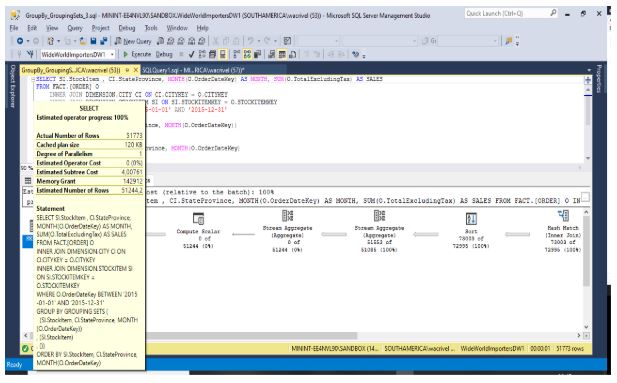
Caso 2: Plano de Execução usando GROUPING SETS apenas para coluna Produto
Custo total é de 4,00761, pois foram adicionados 220 subtotais
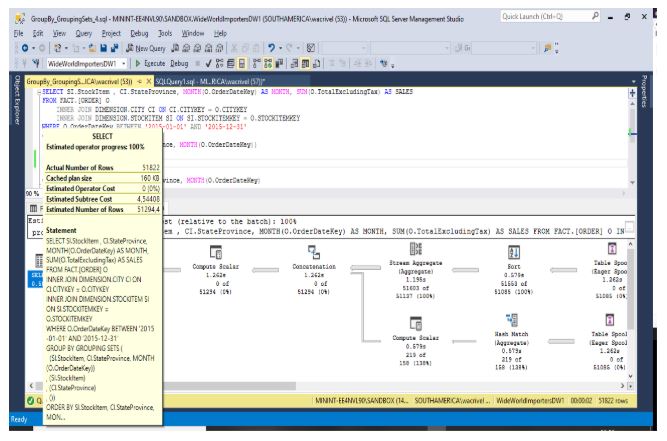
Caso 3: Plano de Execução usando GROUPING SETS para colunas Produto e Estado
Custo total é de 4,54408, pois foram acrescentados mais 49 subtotais em relação ao exemplo anterior
Comentários Finais
A opção GROUPING SETS facilita muito a geração de subtotais em relatórios SQL, permitindo que o desenvolvedor tenha muito mais controle sobre o relatório gerado. A performance segue dentro dos padrões esperados, tendo em vista que só os subtotais desejados são calculados durante a execução da consulta.
Leituras Sugeridas
SELECT – GROUP BY – Transact-SQL por MICROSOFT.
GROUPING SETS in SQL Server 2008 por Craig Freedman.
Consultor Sênior na Microsoft, na área de Data Insights para América Latina. Especialista em bancos de dados, é colunista em diversos portais de TI do Brasil e do exterior, com mais de 100 artigos técnicos publicados. É também co-produtor do DatabaseCast, primeiro podcast brasileiro sobre bancos de dados.