Importação e geração de Log de arquivos massivos com Flask + Map + lambda e multiprocessing do Python
Algumas semanas atrás estava estudando sobre Python e pensei em desenvolver uma rotina simples para realizar leitura de grandes arquivos com flask


Algumas semanas atrás estava estudando sobre Python e pensei em desenvolver uma rotina simples para realizar leitura de grandes arquivos e aplicar regras de tratamento de layout (Posicionamento de texto e retirada de duplicidades) utilizando recursos do Python que podem ter alguma vantagem neste cenário.
Neste artigo vamos criar duas APIs em Flask para executar rotina de importação e outra para acompanhar as linhas atuais em tratativa e o tempo total de processamento, será também utilizado o SQL Server para importar as linhas tratadas com base nas regras de layout, no final é gerado um arquivo de Log com os registros que não passaram nas regras de layout e as exceções geradas pela rotina.
Itens necessários:
1. Python 3.7.2
2. Pycharm
3. Flask
4. SQL Server 2017 Express
5. Redis
6. Postman
7. Criar uma base no SQL Server chamada Estudo.
8. Criar uma tabela na base estudo chamado estagetable.
Após ter instalado todos os itens necessários, vamos obter algum arquivo com muitos registros para que
possa ser tratado e importado com base nas regras definidas, neste artigo eu optei por obter um arquivo de
9.27 milhões de registros que se tratam de atores com algumas informações sobre os mesmos, este arquivo
pode ser obtive através dos datasets do Imdb (https://datasets.imdbws.com/) que é um banco de dados de
praticamente todos os filmes, musicas e series registrados desde 1990.

Agora vamos criar nosso primeiro programa (apiapp.py) python que será nossas API para execução da rotina
e monitoramento. Primeiro vamos informar os pacotes que vamos utilizar neste primeiro arquivo (apiapp.py), aqui temos o próprio flask para criação dos endpoint, o jsonify para tratamento do retorno como json e o request para
obter os parâmetros do body da requisição. O readarchive que será nosso próprio pacote com as funções
para execução da rotina e tratativa de layout do arquivo, o redis para manter em memória a situação atual da
importação do arquivo, o Time para contabilização do tempo de processamento de algumas etapas e do
processo total da rotina e por ultimo inicializamos para a variável app o Flask.
from flask import Flask, jsonify, request
import readarchive
import redis
import time
app = Flask(__name__)Aqui estamos iniciando uma instância do redis localmente através da porta padrão, estamos criando uma rota
chamada readarchive para receber requisições do tipo Post para a função save_archive(), recebemos para a
variável data o corpo da requisição Json e atribuímos a variável arquivo e arquivo_log o caminho de diretório dos arquivos de leitura para tratamento e importação e o arquivo que servira como Log de resultado do arquivo, chamamos então nossa função inicia a importação e tratamento do arquivo no qual recebe os
dois parâmetros com os diretórios dos arquivos, por fim o resultado será apresentado em Json com a resposta 201.
Na outra rota temos a função obter_situa que ira retornar através do método Get, a etapa atual do arquivo e o tempo total de processamento até o momento, onde utilizamos o Redis para obter o conteúdo da chave ‘situacao’ que contem a etapa atual do processamento, convertemos a mesma para string e atribuímos a frase
com o tempo atual menos o tempo registrado em memória através do Redis dividindo por 60 para obter em minutos o tempo total até o momento e retornamos esta mensagem como String.
Por último temos aquela verificação básica para inicializar o Flask caso seja a aplicação principal de execução.
r = redis.Redis(host='localhost', port='6379')
@app.route('/readarchive', methods=['POST'])
def save_archive():
data = request.get_json()
arquivo = data['arquivo']
arquivo_log = data['arquivo_log']
resultproc = readarchive.inicia(arquivo, arquivo_log)
return jsonify(resultproc), 201
@app.route('/situation', methods=['GET'])
def obter_situa():
situacao = str(r.get('situacao'))
situacao += "\n tempo total: "+str((time.time() - float(r.get('tempo_inicial')))/60) + " minutos"
return situacao
if __name__ == '__main__':
app.run(debug=True)
Agora vamos para o arquivo readarchive.py que conterá as funções de inicialização e registro ao SQL
Server. Primeiramente vamos informar as importações dos pacotes, temos o OS para leitura do arquivo em
disco, novamente o time para obter o tempo atual como forma de registrar as etapas, o pacote
multiprocessing onde utilizamos o mesmo para trabalhar com cada processador disponível de forma
paralela através dos Pool, o pyodbc para importação ao SQL Server, redis para mantermos atualizado em
memória a situação do processamento e por ultimo o nosso próprio pacote config que ira conter as funções
de tratamento de layout do nosso arquivo.
import os
import time
# multiplas threads
from multiprocessing.pool import ThreadPool as Pool
import pyodbc
import redis
from config import filtrosTrabalhando agora com a função principal inicia(), vamos detalhar o que esta sendo feito inicialmente,
temos as declarações das variáveis de controle onde o count serve para armazenar como contador o total de
linhas gerais já lidas, tratadas e importadas, a variável linhas serve para receber a quantidade de linhas do arquivo para tratamento, a variável do tipo lista texto recebe o conteúdo das linhas do arquivo em tratamento e por último a variável quantidade que recebe um valor de controle de quantas linhas devem ser tratadas e importadas por vez, neste caso vamos armazenar em memória 100 mil linhas por vez onde faremos:
1. Recebe as próximas 100 mil linhas
2. Aplica tratamentos do pacote config
3. Importa resultado para SQL Server
4. Registra no arquivo de log os resultados com erro
5. limpa lista texto para as próximas 100 mil linhas liberando memória
Na variável R iniciamos a mesma instância do Redis, na variável inicio gravamos o tempo atual em segundos para registrar o inicio da execução, imprimo no console da aplicação a informação de inicio do processamento com o diretório do arquivo a ser processado, gravamos na chave tempo_inicial o tempo gravado na variável inicio.
Abaixo do Try fazemos a abertura dos dos arquivos (importação e log) e caso tenhamos um erro de abertura será retornado ao endpoint a mensagem de erro e por ultimo imprimo no console da aplicação que o arquivo foi lido com sucesso e será iniciado o processamento das primeiras linhas.
def inicia(caminho, caminholog):
# Contagem de linhas totais ja tratadas
count = 0
# Contagem de linhas em tratamento
linhas = 0
# Lista que contem as linhas atuais
texto = []
# Quantidade de linhas a serem processadas por vez
quantidade = 100000
r = redis.Redis(host='localhost', port='6379')
inicio = time.time()
print("Iniciando processamento de leitura....")
print(f'Arquivo a ser lido: {caminho}')
r.set('tempo_inicial', inicio)
try:
arq = open(caminho, 'r', encoding='UTF8')
arqlog = open(caminholog, 'w', encoding='UTF8')
except OSError:
return "Caminho especificado esta invalido valide se possui \\ entre os diretorios"
print("Arquivo lido com sucesso iniciando obtenção das primeiras linhas")Aqui iniciamos a abertura do arquivo para leitura que esta contido na variável Arq, registramos na variável iniciotm o tempo atual desta etapa, fazemos um loop sobre cada linha contida em F que representa o arquivo a ser processado e atribuímos a lista texto o conteúdo da primeira linha e atualizamos o contador linhas para controle, caso a quantidade de linhas já lidas seja maior que a variável quantidade que é a variável de controle para processarmos um certo montante por vez inicia o tratamento e importação das linhas.
Atribuímos a variável count o total de linhas em processamento, atualizamos a chave ‘Linha’ do redis com as linhas atuais em processamento, imprimo no console o tempo total para obter as 100 mil primeiras linhas do arquivo, atualizo no redis a chave ‘situacao’ com a etapa atual do processamento do arquivo, novamente eu gravo o tempo atual para a proxima etapa do processamento que é a retirada da duplicidade das 100 mil primeiras linhas do arquivo aplico a função de duplicidade do meu pacote config.filtros (será apresentado mais a frente o que esta sendo feito) que me retorna uma lista sem duplicidades, imprimo no console o tempo total para retirada da duplicidade e por ultimo atualizo a chave ‘situacao’ no redis com a situação atual do processamento.
with arq as f:
iniciotm = time.time()
for line in f:
texto.append(line)
linhas += 1
if linhas > quantidade:
count += linhas
r.set('linha', count)
print(f"Tempo total para obter as {linhas} linhas de um total de {count} "
f"linhas: {time.time() - iniciotm} ")
r.set('situacao', 'Iniciando retirada de duplicidade... Linhas atuais:' + str(count))
# Retira duplicidade do arquivo caso exista
iniciotm = time.time()
texto = filtros.duplicidade(texto)
print(f"Tempo total para retirar duplicidades das {linhas} linhas de um total de {count} "
f"linhas: {time.time() - iniciotm} ")
r.set('situacao', 'Tratativa de duplicidade executada! Linhas atuais:' + str(count))Continuando ainda na função inicia(). Agora na primeira linha atualizamos o redis com a nova etapa,
gravamos o tempo atual, utilizamos um recurso muito interessante do python para executar a função filtros
para cada índice da minha lista texto, onde o retorno de cada chamada dessa função ele ira me retornar em
uma lista. A função filtros se trata da função para aplicação de regras de layout que será mostrado
posteriormente.
Com minhas 100 mil linhas já tratadas em seu layout definido e sem duplicidades iniciamos um Pool para
cada CPU disponível e utilizamos o map para executar em paralelo a função insertbd em cada CPU
disponível recebendo de forma distribuída a lista contendo as 100 mil linhas já tratadas, a função insertbd é
responsável por inserir no SQL Server as 100 mil linhas.
No meu caso estou utilizando um processamento i7 de 8° geração que possui 4 núcleos.
Ao final das execuções será retornado ao returnlog uma lista com os logs de erros (caso exista) para que o
mesmo seja gravado no arquivo de log, posteriormente estamos imprimindo no console o tempo total para
inserir as linhas no Sql server e fazemos um loop para gravar o conteúdo da minha lista returnlog no arquivo
de log. Por fim zeramos nossa lista texto para limparmos a memória da maquina e zeramos nosso contador
de linhas em processamento.
r.set('situacao', 'aplicando regras de layout Linhas atuais:' + str(count))
iniciotm = time.time()
result = list(map(filtros.filtros, texto))
print(f"Tempo total para aplicar regras de layout das {linhas} linhas de um total de {count} "
f"linhas: {time.time() - iniciotm} ")
pool = Pool(processes=os.cpu_count())
iniciotm = time.time()
returnlog = pool.map(insertbd, result)
print(f"Tempo total para inserir no SQL Server das {linhas} linhas de um total de {count} "
f"linhas: {time.time() - iniciotm} ")
for linha in returnlog:
if len(linha) > 0:
arqlog.write(linha)
texto = []
linhas = 0Após todo loop de leitura de linhas é gravado o tempo atual, fechado os arquivos de importação e log,
impresso no console o tempo total de processamento onde fazemos a variavel fim menos inicio e retornamos
para nossa API a mensagem de processamento com sucesso e o tempo total:
fim = time.time()
arq.close()
arqlog.close()
print(f"Tempo de processamento: {fim - inicio}")
return "Processado com sucesso, tempo total: " + str(fim - inicio)Agora vamos detalhar a função insertbd utilizada no Pool para gravação no SQL Server,
Nesta função recebemos uma lista com o código INSERT do sql server já pronto que foi criado pela função
filtros executada junto ao Map conforme mostrado anteriormente, aqui obtemos o código t-sql da lista e
fazemos a conexão com o banco de dados sql server e executamos um Insert na base com os registros
tratados caso não exista erro de layout, se conter erros de layout será retornado qual foi o erro de layout.
Observe também que para variável errolayout que recebe da minha lista tanto o código T-SQL como meu
erro de layout.
# Função para tratamento de inserção dos dados no banco de dados
# E inserção no arquivo de log em caso de erro do insert ou layout
def insertbd(lista):
code = lista[1]
errolayout = lista[0][0] if len(lista[0]) > 0 else ""
if len(errolayout) == 0:
try:
stringinsert = code[0] if len(code[0]) > 0 else ""
except:
stringinsert = " Erro trativa de if linha 71 sobre a lista: " + str(code)
retorno = ""
conn_str = 'DRIVER={SQL Server};SERVER=DESKTOP-32JQ24J\\SQLEXPRESS;DATABASE=Estudo;Integrated Security=true'
conn = pyodbc.connect(conn_str)
cursor = conn.cursor()
if len(stringinsert) > 0:
try:
cursor.execute(stringinsert)
except pyodbc.ProgrammingError:
retorno = "Erro de T-SQL na inserção, validar: " + stringinsert + " \n"
conn.commit()
else:
retorno = errolayout
return retornoAgora apresentado a função filtros do nosso pacote config que é utilizada no Map mostrado anteriormente:
Esta função realiza a seguintes tratativas:
1. Recebe uma lista contendo as 100 mil linhas do arquivo.
2. Cria um dicionário chamado regras contendo um nome para a regra de layout e uma expressão lambda que
retorna Verdadeiro ou Falso para saber se aquela linha especifica passou pela regra.
3. Criamos um outro dicionario chamado tratativas que servira como filtro para obter os trechos da linha que
foi validada com sucesso pelas regras contidas no dicionário Regras.
4. Criamos uma lista chamada registro que recebe uma string com um INSERT pronto para a tabela EstageTable
somente dos registros validades pelas regras contidas no dicionário regras e tratadas no dicionário tratativas.
5. Por ultimo retornamos uma lista composta com os erros de layout com base no nome e a string de inserção
no sql server.
Observe que as lambdas presentes nos dicionarios servem para ser executadas em um For de cada linha
recebida, podendo atribuir mais filtros de acordo com sua necessidade:
def filtros(linha):
# Dicionario com os filtros para cada linha
regras = {}
# Resultado com a chave do filtro que retornou falso
result = []
# Dicionario com tratativa de linhas para importação
tratativas = {}
# Lista com os registros a serem inseridos na base
registro = []
insbd = []
"""Filtros que serão aplicados linhha a linha"""
regras.update({"NM000": lambda line: len(linha[0:9].strip(" ")) == 9})
regras.update({"NAME": lambda line: len(linha[13:20].strip(" ")) >= 1})
"""Tratativas das linhas para importação"""
tratativas.update({"NM000": lambda line: linha[0:9].strip(" ")})
tratativas.update({"NAME": lambda line: linha[13:26].strip(" ")})
for retira in regras.items():
teste = regras[retira[0]]
if not teste(linha):
result.append("Erro de layout"+retira[0]+" para o conteudo:"+linha)
else:
funcfiltro = tratativas[retira[0]]
retstring = funcfiltro(linha)
registro.append(retstring)
# Somente inseri no banco se todos os filtros foram verdadeiros
if len(registro) == 2:
stringinsert = 'INSERT INTO ESTAGETABLE VALUES '+str(tuple(registro))
insbd.append(stringinsert)
return [result, insbd]Reparem que conforme mostrado anteriormente na função insertbd, ela recebe tanto a string de inserção no
banco como o erro de layout visto que o retorno da mesma ira gravar no arquivo de log.
Por fim, a ultima função a ser apresentada é a função de duplicidade que é uma função bem simples graças
ao tipo de dado ‘tuple’ do Python, basicamente recebemos as 100 mil linhas convertemos para uma ‘tuple’ e
depois convertemos para uma lista novamente, com isso por padrão toda ‘tuple’ não pode ter registros iguais
então o Python internamente utiliza um algoritmo avançado para identificar a duplicidade de retirar a mesma
da lista.
def duplicidade(linhas):
# Cria um conjunto e depois transforma em lista, conjunto não pode ter dados repetidos,
# logo o mesmo retira a duplicidade.
result = list(set(linhas))
return resultAté o momento foi apresentado todo código da aplicação, ao final deste artigo disponibilizo o link do Github
para código completo.
Hora de rodar e validarmos a performance
Iniciando a nossa aplicação:
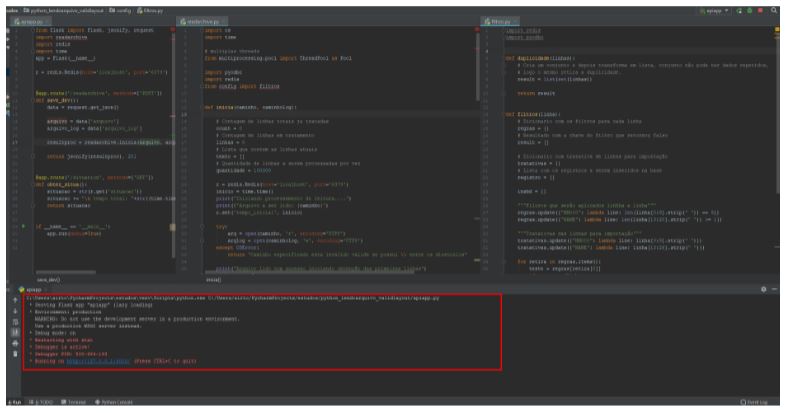
Abrindo o Postman e executando o endpoint readarchive passando os diretórios do arquivo baixado do imdb com 9
milhões de registros e um arquivo de log:
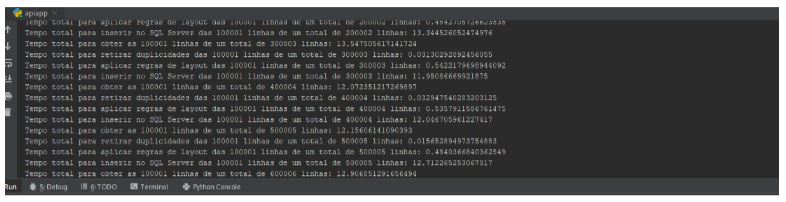
Ao executar nossa aplicação, nos primeiros segundos ja podemos observar em nosso console do Pycharm os
resultados de processamento das 100 mil primeiras linhas e o tempo de execução das etapas é fantástico:
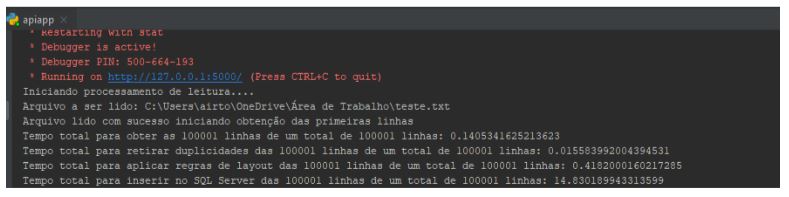
Somando as etapas para obter as 100 mil linhas, retirar duplicidade de 100 mil linhas, aplicar 4 filtros através de
função lambda para cada linha das 100 mil linhas e inserir as 100 mil linhas no SQL Server com multiprocessing
tivemos um tempo de 0.14+0.015+0.41+14.83 segundos que resulta em 15 segundos.
E os tempos variavam minimamente:
Se observamos o consumo de memória do pycharm podemos observar que esta baixo devido ao processamento ser
de 100mil em 100mil:

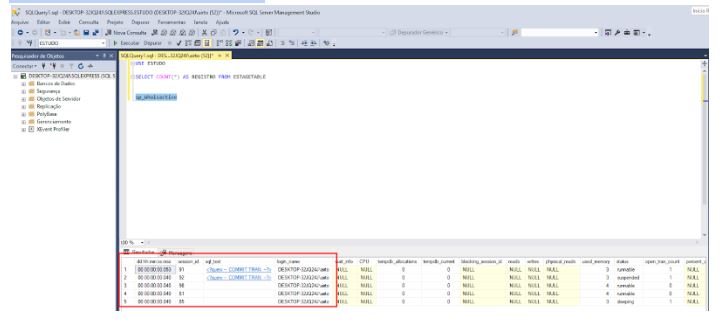
Olhando agora para o banco de dados SQL Server observamos que temos 5 sessões trabalhando na base, sendo 4 da aplicação e 1 de consulta minha do SSMS:
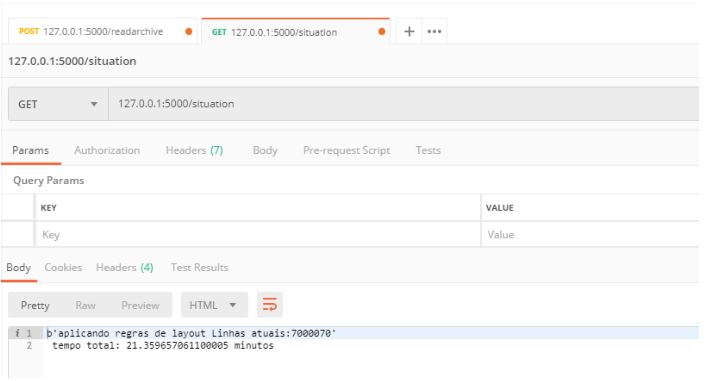
Agora vamos consumir o outro endpoint situation para verificamos a situação atual do processamento e quantas linhas já foram tratadas:
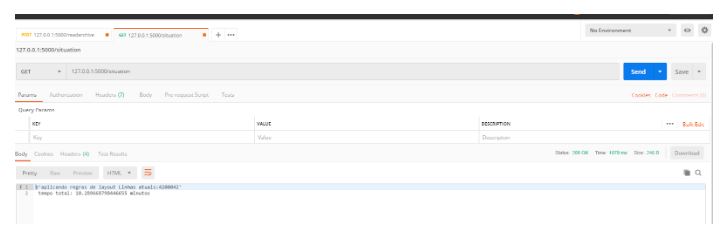
Em 10 minutos já processamentos 4 milhões e 200 mil linhas, lembrando que esta sendo aplicado 4 regras de layout (2 para validação e 2 para tratamento do conteudo da linha para importação), retirada de duplicidade, importação ao SQL Server e escrita em arquivo de Log.
E a constância do tempo para as etapas se mantém:
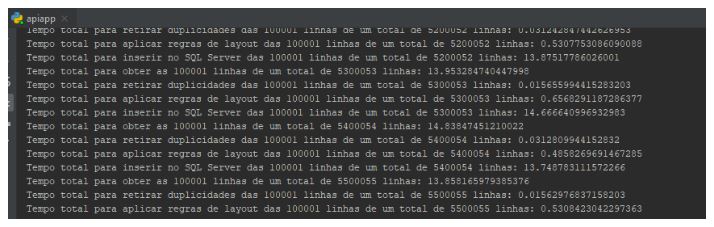
Quantidade de registros na base atualmente 5 milhões e 500 mil:
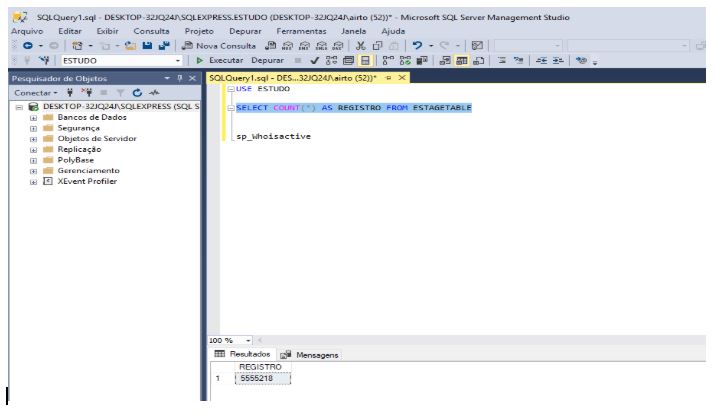
Validando nosso arquivo de Log que esta sendo preenchido de forma online, podemos ver alguns erros de inserção t-sql, isso deve-se a formação do conteúdo do arquivo do imdb, no qual podemos atribuir ao nosso dicionario da função filtros uma tratativa para retirar estes caracteres invalidos (\n e aspas simples dentro de apastas duplas), mas aqui evidenciamos a eficácia da gravação do log.
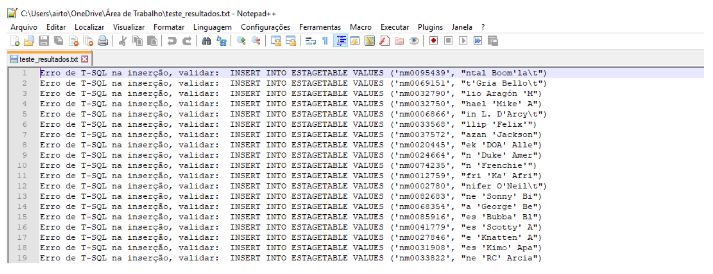
Validando novamente as linhas ja processadas e o tempo total de execução, temos 7 milhões de registros em 21 minutos.
Algumas considerações:
- Como estamos utilizando Python, podemos aplicar alguns cálculos estatísticos com numpy no lambda da função filtros para gerar informações sobre os dados que estão sendo lidos do arquivo.
- Acredito que no cenario de apenas tratar os registros e importar para base a linguagem Go poderia ter uma melhor performance mas em caso de trabalhar com algoritmos mais avançados os dados desse arquivo, o Python possui mais recursos prontos para isso.
- Aqui foi utilizando um notebook pessoal convencional, por tanto a performance geral deve ser considerada diante deste cenário.
- Podemos utilizar o Docker e suas tecnologias para rodar este tipo de cenário em varias maquinas em arquivos distribuídos.
Portanto este artigo foi interesse pessoal de compartilhar uma experiência que tive com Python neste cenário durante meus estudos, deixo abaixo o link do github para código fonte completo da aplicação.
https://github.com/AirtonLira/ReadMassiveArchive_Python
Obrigado!
Airton Lira Junior é um profissional de Tecnologia da Informação com mais de 10 anos de experiência, especializado em Big Data, Engenharia de Dados e Arquitetura de Soluções em nuvem. Atualmente atua como Engenheiro Sênior de Dados e Analytics na Dock, liderando melhorias em plataformas de dados, orquestração de pipelines com Databricks e otimização de workloads em AWS (EC2, EMR, SageMaker). Com passagens por empresas como iFood e Bemobi, destacou-se na concepção de soluções inovadoras, como modelos LLM para chatbots, integrações de IA em pipelines de áudio e projetos de conciliação financeira regulatória, utilizando tecnologias como Golang, Python, Apache Spark e Kubernetes. Possui certificações em AWS, Databricks e Power BI, além de formação em Análise de Sistemas pela FIA e especialização em Banco de Dados. Reconhecido por sua proatividade e expertise técnica, contribui ativamente para a comunidade tech como colunista no iMasters, compartilhando conhecimentos em automação, engenharia de prompts e arquitetura de dados escaláveis.