AI Practitioner – AWS | Como passar na certificação
Se você chegou até aqui, é porque tem um objetivo claro: dominar o mundo da Inteligência Artificial na AWS e conquistar a certificação AI Practitioner.


Se você chegou até aqui, é porque tem um objetivo claro: dominar o mundo da Inteligência Artificial na AWS e conquistar a certificação AI Practitioner. E adivinha? Você está no lugar certo!
Este guia é o seu mapa do tesouro, recheado de dicas práticas, insights valiosos e um simulado para você testar seus conhecimentos. Preparei tudo com base na minha própria experiência (e sucesso!) na prova, usando as anotações que você já tem.
AI Practitioner – AWS | O Que Esperar da Prova (e Como se Preparar!)
A certificação AWS AI Practitioner não é um bicho de sete cabeças, mas exige dedicação. Ela quer saber se você:
- Entende os conceitos-chave: IA, Machine Learning (ML), Deep Learning, IA Generativa… Tudo isso precisa estar na ponta da língua.
- Sabe usar as ferramentas da AWS: Não basta conhecer a teoria, você precisa saber como aplicar os serviços da AWS para resolver problemas reais.
- Pensa como um(a) consultor(a) de IA: Você não vai construir modelos do zero, mas precisa saber qual ferramenta usar em cada situação.
- Tem a IA Responsável no coração: Ética, justiça, transparência… A AWS leva isso muito a sério (e você também deveria!).
As Áreas Que Você Precisa Dominar
A prova é dividida em quatro grandes áreas:
1. Fundamentos de IA e ML (20%)
- Conceitos básicos (IA, ML, Deep Learning).
- Tipos de aprendizado (supervisionado, não supervisionado, por reforço).
- Ciclo de vida do desenvolvimento de ML (com foco nos serviços da AWS!).
2. Fundamentos de IA Generativa (24%)
- O que é e como funciona.
- Modelos de linguagem (LLMs).
- Amazon Bedrock (a plataforma da AWS para IA Generativa).
- Engenharia de prompt (a arte de “conversar” com a IA).
3. Aplicações de Modelos Fundacionais (28%)
- Serviços da AWS para tarefas específicas (Rekognition, Comprehend, Polly, Kendra, Personalize…).
- Casos de uso (como aplicar esses serviços em situações reais).
- Integração entre serviços (como eles funcionam juntos).
4. Diretrizes para IA Responsável (28%)
- Ética, justiça, transparência, explicabilidade.
- Design centrado no ser humano.
- Segurança, conformidade e governança (IAM, criptografia, Macie, monitoramento…).
- Regulamentações (Ato da IA da UE, Framework do NIST…).
Iniciando a jornada do curso
- Parte 1: Conceitos Básicos de IA
Inteligência Artificial (IA)
A IA é uma área da ciência da computação que visa criar máquinas ou programas que possam realizar tarefas que normalmente requerem a inteligência humana. Isso inclui desde jogar xadrez até interpretar linguagem natural. Pense na IA como a “mente” artificial que tenta imitar o cérebro humano.
Aprendizado de Máquina (ML)
O ML é um subcampo da IA focado em desenvolver algoritmos que permitem aos computadores aprender a partir de dados. Imagine que você tem um cão-robô; ao invés de programá-lo para reconhecer cada tipo de objeto, você o ensina a identificar objetos mostrando várias imagens e deixando-o aprender por conta própria.
Deep Learning
O deep learning é uma subárea do ML que utiliza redes neurais profundas, que são compostas por várias camadas de neurônios artificiais. Pense nisso como uma versão mais avançada do ML, semelhante ao funcionamento do nosso cérebro, mas em um nível muito mais complexo.
Além do aprendizado supervisionado e não supervisionado, tem o aprendizado sobe Reforço, que é o modelo aprender baseado em recompensa e punições. Imagine seu cão-robô recebendo um biscoito cada vez que ele encontra a bola correta.
Tecnologias de ML apropriadas:
Diferentes tecnologias são adequadas para diferentes casos de uso. Amazon Rekognition, por exemplo, é ótimo para reconhecimento de imagem, enquanto o Amazon Polly é usado para Converter texto em Fala.
Ciclo de vida do desenvolvimento de ML
1 – Coleta de dados: AWS Glue
2 – Preparação de dados: Amazon S3
3 – Treinamento: Amazon SageMaker
4 – Avaliação: Amazon SageMaker
5 – Implantação e monitoramento: Amazon SageMaker e AWS CloudWatch
Como Funciona o Machine Learning?
1 – Algoritmo Matemático
O processo começa com um algoritmo que recebe dados como entradas e gera uma saída. O treinamento ocorre fornecendo dados conhecidos para análise.
2 – Análise de Características
As características são como colunas em uma tabela ou pixels em uma imagem. O objetivo é encontrar correlações entre as características e a saída esperada.
3 – Ajuste de Parâmetros
O modelo é ajustado alterando valores de parâmetros internos até produzir consistentemente a saída esperada.
Ajuste e Inferência
Após o treinamento, o modelo pode fazer previsões precisas e produzir saídas a partir de novos dados não vistos durante o treinamento. Isso é Conhecido como Inferência.
Treinamento do Modelo e Modelos Desdobráveis
Focaremos no que ocorre após o treinamento do modelo, explorando os artefatos do modelo e seu uso subsequente.
Após o treinamento do modelo são gerados alguns artifects ou artefatos do modelo:
Artefatos de Modelo:
Parâmetros treinados
- Valores ajustados durante o treinamento do modelo.
Definição do modelo
- Descrição de como realizar inferências com o modelo.
Metadados
- Informações adicionais que descrevem o modelo treinado.
Os artefatos são armazenados no Amazon S3 e empacotados com o código de inferência.
Opções para Hospedar um Modelo
Existem duas opções principais para hospedar um modelo: inferência em tempo real e processamento em lote.
Inferência em Tempo Real
Indicada para inferências online com baixa latência e alto rendimento. O modelo é desdobrado em um endpoint persistente.
Processamento em Lote
Adequado para processamento offline de grandes quantidades de dados. Mais econômico quando não há necessidade de respostas imediatas.
Deep Learning:
Como Funciona o Deep Learning?
No deep learning, a informação flui pela rede neural do input para o output. Cada nó atribui pesos autonomamente a cada característica. Durante o treinamento, a diferença entre a saída prevista e a real é calculada, e os pesos dos nós são ajustados repetidamente para minimizar o erro.
Deep Learning vs. Machine Learning Tradicional
Deep Learning:
Ideal para dados não estruturados como imagens, vídeos e texto. Destaca-se em tarefas que requerem identificação de relações complexas entre pixels e palavras.
Machine Learning Tradicional:
Funciona bem com dados estruturados e rotulados, como tabelas de dados. Eficiente para identificar padrões, como em sistemas de recomendação.
Generative AI e Modelos de Linguagem
A Generative AI utiliza modelos de deep learning pré-treinados em datasets enormes. Eles usam redes neurais transformer que processam sequências de entrada (prompts) em paralelo, acelerando o treinamento e permitindo o uso de datasets maiores.
Modelo de Linguagem de Grande Escala:
Contém bilhões de atributos que capturam uma ampla gama de conhecimentos humanos. Podem entender e gerar linguagem humana, traduzir textos, escrever histórias, artigos e até programar.
A Amazon Bedrock pode ser usada para explicar sobre grandes modelos de linguagem. Você pode construir seu próprio app de IA em partyrock.aws.
Inferência e Overfitting
Inferência:
É quando o modelo de machine learning faz uma previsão ou classificação. Por exemplo, um modelo treinado com imagens de peixes na água pode não reconhecer peixes fora da água.
Overfitting:
Ocorre quando um modelo funciona bem com os dados de treinamento, mas não consegue generalizar para novos dados. É como se o modelo tivesse decorado os exemplos, mas não aprendido a essência.
Correção de Overfitting:
A melhor maneira de corrigir overfitting é usar um conjunto de dados mais diversificado para o treinamento, ajudando o modelo a reconhecer a essência em diferentes situações.
Underfitting e o Ponto Ideal
Underfitting:
É o oposto do overfitting. Ocorre quando o modelo não consegue identificar corretamente a relação entre os dados de entrada e saída, tanto no conjunto de treinamento quanto nos novos dados.
Quando Acontece:
Pode ocorrer se não treinarmos o modelo por tempo suficiente ou se não tivermos dados suficientes para o treinamento.
O Ponto Ideal:
Os cientistas de dados buscam o “sweet spot” ou ponto ideal de tempo de treinamento, onde o modelo aprende o suficiente para generalizar bem sem cometer overfitting ou underfitting.
Amazon Rekognition
Vamos começar falando sobre o Amazon Rekognition. Este é um serviço de aprendizado profundo pré-treinado voltado para visão computacional. Ele atende a diversas necessidades comuns sem que você precise treinar seus próprios modelos. E o melhor: funciona tanto com imagens quanto com vídeos, incluindo vídeos em streaming.
Como acessar:
Para acessar o Amazon Rekognition, basta entrar na página do serviço e clicar em “Get started with Amazon Rekognition”. Você precisará de uma conta AWS para continuar. Depois de fazer login, você poderá acessar a console do Amazon Rekognition e começar a explorar suas funcionalidades.
O Rekognition pode detectar e rotular objetos, tornando sua biblioteca de imagens ou vídeos pesquisável. Ele pode ser implementado, por exemplo, em sistemas de segurança para detectar e identificar objetos em vídeos em tempo real e enviar alertas.
- Detecção e rotulagem de objetos em imagens e vídeos
- Torna bibliotecas de mídia pesquisáveis
- Implementação em sistemas de segurança
- Identificação de objetos em tempo real
- Envio de alertas baseados na detecção
Como acessar o Amazon Textract
Customização de Objetos
Se você tiver objetos customizados ou proprietários, basta fornecer algumas imagens rotuladas para que ele aprenda a reconhecê-los.
Reconhecimento de Texto
E mais: ele também pode adicionar rótulos para qualquer texto que encontrar, como placas de rua.
Aprendizado Personalizado
O Amazon Textract permite que você adapte o serviço às suas necessidades específicas, melhorando o reconhecimento de objetos e textos personalizados.
Casos de Uso do Amazon Comprehend
Descoberta de Insights:
O Amazon Comprehend é um serviço de processamento de linguagem natural projetado para descobrir insights e relações em textos.
Processamento de Linguagem Natural:
Este serviço oferece capacidades avançadas de processamento de linguagem natural para analisar e extrair informações valiosas de textos.Agora vamos falar sobre o Amazon Comprehend, um serviço de processamento de linguagem natural. Ele é projetado para descobrir insights e relações em textos.
Como acessar:
Para acessar o Amazon Comprehend, visite a página oficial e clique em “Get started with Amazon Comprehend”. Após fazer login na sua conta AWS, você terá acesso à console para explorar as capacidades de processamento de linguagem natural.
Amazon Polly
O Amazon Polly transforma texto em fala natural em vários idiomas usando deep learning.
1. Conversão de artigos em áudio:
Transforme posts de blog em áudio para ouvir enquanto dirige ou se exercita.
2. Sistemas de resposta de voz interativa (IVR):
Crie mensagens automáticas mais agradáveis para bancos e outros serviços.
3. Uso em mídia:
O Washington Post e USA Today usam para converter notícias em áudio.
Amazon Kendra
O Amazon Kendra usa machine learning para buscas inteligentes em sistemas empresariais.
- Busca inteligente: Funcionários podem fazer perguntas naturais e obter respostas precisas.
- Resultados Relevantes: O Kendra entende a pergunta e fornece a resposta correta rapidamente.
Amazon Personalize
O Amazon Personalize cria recomendações personalizadas para clientes.
Recomendações de Produtos:
Gera sugestões do tipo “Você também pode gostar disso” automaticamente.
Personalização:
Baseado nas preferências e comportamento do usuário.
Marketing:
Segmenta clientes para campanhas mais eficazes.
Pipeline de Machine Learning
No caso de uma pipeline em marchine learning os passos incluem:
- Definição do problema
- Coleta e preparação dos dados de treinamento.
- Treinamento do Modelo.
- Implantação do modelo
- Monitoramento Contínuo do Modelo
E esses passos são iterativos – repete alguns deles até alcançar certos objetivos.
Etapas do Ciclo de Vida de um Modelo de ML
- Visão Geral
Vamos olhar cada fase em detalhe e ver quais serviços da AWS podem nos ajudar em cada uma delas.
- Identificação do Objetivo de Negócio
O desenvolvimento de um modelo de ML deve sempre começar com a identificação de um objetivo de negócio claro.
Sem isso, como saber se o nosso modelo é bem-sucedido? É essencial medir o valor de negócios contra objetivos específicos e critérios de sucesso.
- Exemplo Prático
Imagine que você trabalha numa empresa que deseja prever a rotatividade de clientes. O objetivo de negócio é reduzir a perda de clientes. Certo, mas como você mede isso? Talvez seja pela taxa de retenção de clientes após usar o modelo.
Identificando e Coletando Dados de Treinamento
- Identificar Dados Necessários
- drminar quais dados serão usados e onde estão.
- Opções de Coleta:Ecolher entre dados em fluxo contínuo ou processamento em lot
- Serviços AWS:Amazo Kinesis, MSK ou S3 para coleta.
Preparação dos Dados
- Análise ExploratóriaUsar SageMaker Data Wrangler para visualização e entendimento.
- Engenharia de FeaturesSelecionar características importantes para treinar o modelo.
- Divisão do DatasetSeparar em dados de treinamento, validação e teste.
Serviços AWS para Ingestão e Preparação de Dados:
- AWS GlueServiço ETL gerenciado para transformação de dados.
- AWS Glue DataBrewFerramenta visual para limpeza e normalização de dados.
- SageMaker Ground TruthConstrução de datasets de treinamento de alta qualidade.
Avaliação e Ajuste de Hiperparâmetros
Hiper parâmetros:
São valores definidos antes do treinamento que influenciam o desempenho do algoritmo. Exemplos incluem número de camadas neurais e nós em cada camada.
Experimentação:
É necessário experimentar várias combinações de hiperparâmetros para encontrar os valores ótimos. Isso envolve executar experimentos para encontrar a melhor solução.
Avaliação do Modelo
SageMaker Experiments:
Permite criar, gerenciar, analisar e comparar experimentos de machine learning.
Tuning Automático:
Encontra a melhor versão do modelo executando vários jobs de treinamento.
Métricas de Desempenho:
Identifica os melhores modelos com base em critérios específicos.
Tipos de Inferência no SageMaker
Tipo de Inferência Descrição Uso Ideal
Inferência em Tempo Real:
Usa instâncias EC2 ML, que podem estar em um grupo de auto scaling. Cargas de trabalho que precisam de respostas imediatas.
Inferência Assíncrona:
Enfileira requisições e escala o endpoint para zero quando não há requisições. Payloads grandes com tempos de processamento elevados.
Inferência Serverless:
Utiliza funções Lambda e você só paga quando as funções estão rodando. Requisições em tempo real sem provisionar diretamente instâncias.
Batch Transform:
Fornece inferência offline para grandes conjuntos de dados. Quando persistência no endpoint não é necessária e pode-se esperar resultados.
Automação no Ciclo de Vida de ML
O Que é MLOps?
MLOps aplica boas práticas de engenharia de software ao desenvolvimento de modelos de machine learning, focando na automação de tarefas manuais, testes e respostas automáticas a incidentes.
Benefícios do MLOps
Inclui aumento de produtividade, repetibilidade, confiabilidade, conformidade e melhoria na qualidade de dados e modelos.
Amazon SageMaker Pipelines
Orquestração:
O Amazon SageMaker Pipelines é uma ferramenta para orquestrar jobs no SageMaker e autorar pipelines de ML reprodutíveis.
Funcionalidades:
Inclui orquestração de jobs personalizados, inferência em tempo real, inferência batch, automação de práticas operacionais e versatilidade na criação de pipelines.
Exemplo de Aplicação:
Um modelo que infere a idade de um abalone com base no tamanho.
Métricas de avaliação de modelos de Machine Learning:
Acurácia, precisão e recall são métricas comuns para avaliar modelos de machine learning, especialmente em tarefas de classificação.
Acurácia (Accuracy): Mede a proporção de predições corretas em relação ao total de predições feitas. É útil quando as classes estão balanceadas (quantidade semelhante de exemplos em cada classe).
Precisão (Precision): Mede a proporção de predições positivas que realmente eram positivas. É crucial quando o custo de falsos positivos é alto (ex.: diagnósticos médicos)
Recall (Sensibilidade): Mede a proporção de casos positivos identificados corretamente. É importante quando queremos minimizar os falsos negativos (ex.: detectar fraudes)
F1 Score é uma métrica que combina precisão e recall em uma única medida, especialmente útil quando há um desequilíbrio entre as classes (muito mais exemplos de uma classe do que de outra). É a média harmônica entre precisão e recall, dando igual importância a ambos. Em cenários de dados desbalanceados, onde acurácia pode ser enganosa. Por exemplo, em detecção de fraudes, onde a maioria das transações são legítimas, o F1 Score avalia melhor o desempenho do modelo.
Área Sob a Curva (AUC)
Conceito Básico
A Área Sob a Curva (AUC) é uma métrica poderosa usada em algoritmos de classificação binária. Ela oferece uma visão abrangente do desempenho do modelo em diferentes limiares de classificação.
Construção da Curva ROC:
A AUC é baseada na curva ROC (Receiver Operating Characteristic), que plota a Taxa de Verdadeiros Positivos contra a Taxa de Falsos Positivos em vários limiares de classificação.
Interpretação dos Valores:
As pontuações AUC variam de 0 a 1. Um valor de 1 indica precisão perfeita, enquanto 0,5 sugere um classificador aleatório. Valores acima de 0,8 geralmente indicam um bom desempenho do modelo.
Vantagens e Aplicações:
A AUC é particularmente útil para comparar diferentes modelos e é insensível a desequilíbrios nas classes. É amplamente utilizada em problemas de detecção de fraudes, diagnósticos médicos e sistemas de recomendação. A AUC é a área sob a Curva ROC e fornece um único valor que representa a performance do modelo. Um AUC de 1 significa separação perfeita, enquanto um AUC de 0.5 indica que o modelo não é melhor que o acaso. A AUC fornece um número entre 0 e 1; quanto mais perto de 1, melhor. Um AUC de 0.5 indica performance semelhante a um chute.
Exemplo Prático:
Suponha que nosso classificador de peixes alcance uma AUC de 0.85. Isso indica que em 85% das vezes, o classificador irá atribuir uma pontuação mais alta ao peixe verdadeiro do que ao não peixe.
Interpretação:
AUC = 1.0: Excelente, classificação perfeita.
AUC = 0.85: Muito bom, o classificador é robusto.
AUC = 0.7: Modelo moderadamente bom.
AUC = 0.5: Desempenho semelhante à escolha aleatória.
Visualização:
Imagine que a Curva ROC se parece com um arco tênue esticando-se do ponto (0,0) ao (1,1). Quanto mais curvada em direção ao topo esquerdo do gráfico (ponto (0,1)), melhor o desempenho do modelo.
Cenários de arquitetura:
![[arquitetura_badrock.png]]
Foundation models – Modelos de fundação:
Modelos pré-treinados são modelos de fundação:
![[foundation_model.png]]
Ciclo de vida de um modelo de função para treinamento de novos dados:
![[ciclo_de_vida_modelo_fundacao.png]]
- São grande dados e de alta volatidade
- Diferente de machine learning aqui pode ter vários tipos de arquivos e um grande volume de dados de entrada.
- Engenharia de prompt é uma técnica de otimização, se tornando um prompt eficaz. Demonstração de entrada e saída por exemplo.
- Avaliação é para avaliar se o métricas atingiu métricas especificas como coerência, bias, relevância, avaliação humana etc..
Tokens e Embeddings:
Embeddings é uma representação numérica de Tokens
Tokens são unidades básicas de processamento de texto, podendo ser palavras sub palavras ou caracteres individuais, como uma frase que depois ela será tokenizada, ex: [“Um”,”filhoete”,”está”,”para”,”cão”,”como”,”um”,”gato”,”esta”,”para”,”gato”].
Já falando melhor sobre embeddings eles capturam significado e relações semânticas, por exemplo: Embedding para “gato” estaria próximo no espaço vetorial aos embeddings de “felino” e “gatinho”.
Exemplo de embedding mostrando a similaridade:
![[exemploDeEmbedding.png]]
Exemplo de tokenização GPT:
Vamos usar a frase “O gato preto pulou o muro alto” como exemplo. Note que este é um exemplo simplificado, pois o tokenizador real do GPT tem um vocabulário muito maior e mais complexo.
1. Pré-processamento: o_gato_preto_pulou_o_muro_alto
2. Tokenização possível: ["o", "_gato", "_preto", "_pul", "ou", "_o", "_mu", "ro", "_alto"]
3. Com IDs (hipotéticos): [35, 234, 567, 1023, 45, 15, 789, 15, 456]
Engenharia de prompt – Otimização de Saídas do Modelo:
Otimização de Saídas do Modelo
A otimização das saídas do modelo é crucial para adaptar os FMs a tarefas específicas e melhorar seu desempenho. Vamos explorar em detalhes as principais técnicas de otimização:
1. Engenharia de Prompts
A engenharia de prompts é uma técnica que envolve o design cuidadoso das instruções ou perguntas fornecidas ao modelo para obter os resultados desejados.
Elementos de um prompt eficaz:
- Instruções: Descrição clara e concisa da tarefa a ser realizada.
- Contexto: Informações de fundo relevantes para a tarefa.
- Dados de entrada: Informações específicas sobre as quais o modelo deve operar.
- Indicador de saída: Especificação do tipo ou formato de saída desejado.
Modelos de difusão: Visão geral:
Os modelos de difusão são baseados na ideia de transformar dados gradualmente entre dois estados: dados estruturados (por exemplo, uma imagem clara) e ruído puro. Este processo ocorre em duas fases principais: difusão direta e difusão reversa.
Difusão Direta
A difusão direta é o processo de adicionar ruído gradualmente a uma amostra de dados até que ela se torne ruído puro.
Características da Difusão Direta:
- Processo Markoviano: Cada etapa depende apenas do estado anterior.
- Adição Gradual de Ruído: O ruído é adicionado em pequenas quantidades em cada etapa.
- Destruição de Informação: Gradualmente, a estrutura original dos dados é perdida.
Difusão Reversa
A difusão reversa é o processo de aprender a reverter a difusão direta, gerando dados a partir do ruído.
Características da Difusão Reversa:
- Processo Iterativo: Começa com ruído e gradualmente o remove.
- Aprendizagem de Modelo: Um modelo neural é treinado para prever e remover o ruído.
- Geração Gradual: A estrutura dos dados emerge progressivamente do ruído.
**Multi-Modal em Machine Learning:
Multi-modal em Machine Learning é um conceito avançado que combina diferentes tipos de dados para criar modelos mais robustos e eficientes. Esta apresentação explorará os fundamentos, aplicações e desafios dessa abordagem inovadora.
O Que é Multi-Modal?
Definição
- Utilização de múltiplas formas de dados em um modelo de ML
- Inclui texto, imagens, áudio, vídeo e sensores
Por que Utilizar?
- Replica a capacidade humana de processar informações diversas
- Cria modelos mais robustos e precisos
![[comofuncionaMultiModal.png]]
Exemplos de Integração
- Comércio Eletrônico: Integração de texto e imagens para recomendações de produtos mais precisas.
- Assistentes Virtuais Combinação de processamento de voz e texto para interações mais naturais.
- Diagnóstico Médico Análise de imagens médicas e dados de pacientes para diagnósticos mais acurados.
Desafios em Multi-Modal
- Sincronização Alinhar diferentes tipos de dados temporalmente.
- Dimensionalidade Lidar com diferentes escalas e dimensões de dados.
- Processamento Gerenciar recursos computacionais para múltiplos tipos de dados.
Ferramentas e Tecnologias:

Já na AWS você poderia utilizar o SageMaker e o Recoknition para analise de texto e vídeo, o comprehend para fazer analise de linguagem natural NLP (extrair analise de sentimento), o AWS Transcribe para tradução em tempo real.
Limitações da IA Generativa:

Interoperabilidade dos modelos:
Ferramenta AWS que oferece um hub de ML integrados para serem implementados em poucos cliques:
O Amazon SageMaker JumpStart é um hub de machine learning (ML) que facilita e acelera a criação e implantação de aplicações de ML. Ele oferece acesso a uma ampla variedade de modelos pré-treinados de código aberto, incluindo aqueles dos hubs TensorFlow, PyTorch e Hugging Face, permitindo que você implante ou ajuste esses modelos com apenas um clique.
Além disso, o JumpStart disponibiliza soluções completas para casos de uso comuns, como previsão de demanda, detecção de fraudes e compreensão de documentos. Essas soluções são totalmente personalizáveis e podem ser implantadas rapidamente, ajudando a reduzir o tempo de desenvolvimento e a complexidade na implementação de projetos de ML.
Com o SageMaker JumpStart, você também pode compartilhar artefatos, incluindo modelos e notebooks, dentro da sua organização, facilitando a colaboração e acelerando a construção e implantação de modelos de ML. Os administradores podem controlar quais modelos são visíveis para os usuários, garantindo conformidade e segurança.
Em resumo, o Amazon SageMaker JumpStart é uma ferramenta poderosa que simplifica o processo de desenvolvimento de machine learning, oferecendo recursos que vão desde a seleção de modelos pré-treinados até soluções completas para casos de uso específicos, tudo com o objetivo de acelerar sua jornada em ML.
Modelos fundacionais – Foundation Models com Amazon Bedrock – AWS Bedrock:
O Amazon Bedrock é um serviço totalmente gerenciado da AWS que facilita a criação e escalabilidade de aplicações de IA generativa. Ele oferece acesso a uma variedade de modelos de base (FMs) de alto desempenho de empresas líderes em IA, como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI e Amazon, por meio de uma única API. Isso permite que os desenvolvedores experimentem, personalizem e integrem modelos de IA generativa em suas aplicações de forma segura e eficiente.
Caso de Uso: Assistente Virtual para Atendimento ao Cliente
Uma empresa pode utilizar o Amazon Bedrock para desenvolver um assistente virtual capaz de interagir com clientes de maneira natural e personalizada. Ao integrar modelos de linguagem avançados disponíveis no Bedrock, o assistente pode compreender e responder a perguntas frequentes, fornecer recomendações de produtos e auxiliar em processos de suporte técnico. Além disso, com a capacidade de personalizar os modelos com dados específicos da empresa, o assistente pode alinhar suas respostas ao tom e às políticas da marca, melhorando a experiência do cliente e aumentando a eficiência operacional.
Em resumo, o Amazon Bedrock oferece uma plataforma robusta para empresas que desejam incorporar IA generativa em suas operações, permitindo a criação de soluções inovadoras e adaptadas às necessidades específicas de cada negócio.
Considerações de Design para Aplicações com Foundation Models
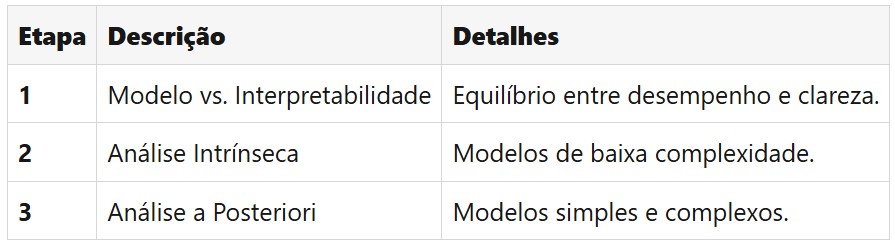
Nesta aula, exploramos as principais considerações para projetar aplicações que utilizam modelos fundacionais (foundation models), ferramentas poderosas de aprendizado de máquina. São destacados três critérios essenciais: custo, latência e propriedades multimodais.
- Custo: A escolha do modelo deve equilibrar precisão, orçamento e desempenho. Modelos menores ou otimizados podem ser mais vantajosos, especialmente em infraestruturas de cloud computing, onde os custos de processamento podem se acumular.
- Latência: Em aplicações que demandam respostas em tempo real, como veículos autônomos, modelos mais simples e rápidos são preferíveis para atender aos requisitos de negócios.
- Modalidades: Modelos multimodais são ideais para processar diferentes tipos de dados (texto, imagem, áudio) e são essenciais em tarefas como tradução multimídia. Além disso, a arquitetura do modelo deve ser adequada à tarefa, equilibrando precisão e recursos computacionais.
Por fim, a avaliação de desempenho é essencial, utilizando métricas padronizadas, mas sempre considerando a finalidade da aplicação. O objetivo é garantir sistemas eficientes e eficazes, maximizando o retorno sobre investimento (ROI) e alinhando os modelos às necessidades específicas do projeto.
Bancos de Dados Vetoriais na Prática: Potencializando o RAGFluxo de Funcionamento
- Input prompt → Prepare input for retrieval → Retrieve and reclassify → Augment prompt → Call LLM and return completion → Completion Conexão com EXTERNAL DATA SOURCES (fontes de dados externas, como bancos de dados ou arquivos).
Descrição Geral
Os bancos de dados vetoriais são fundamentais para a implementação eficiente do RAG, permitindo buscas rápidas e precisas em grandes volumes de dados. O processo de uso prático desses bancos envolve várias etapas cruciais, começando pela codificação do prompt de consulta em um vetor numérico, conhecido como embedding.
Uma vez gerado o embedding da consulta, o sistema realiza uma busca de similaridade no banco de dados vetorial, identificando os embeddings mais próximos. Essa busca é geralmente realizada usando métricas como a distância cosseno ou euclidiana. Os dados relevantes associados aos embeddings similares são então recuperados e combinados com o prompt original, formando um contexto enriquecido para o modelo de linguagem.
Etapas do Processo

A AWS oferece uma gama diversificada de serviços para o armazenamento eficiente de embeddings, cada um com características únicas que atendem a diferentes necessidades de aplicações de IA. O Amazon OpenSearch Service destaca-se pela sua capacidade de realizar buscas de baixa latência e agregações complexas, ideal para aplicações que exigem respostas rápidas e análises em tempo real.
Para aplicações que requerem alta disponibilidade e escalabilidade, o Amazon Aurora e o Amazon RDS com PostgreSQL oferecem soluções robustas. O Redis, por sua vez, é excelente para cenários que demandam cache em memória e operações de alta velocidade. O Amazon Neptune se destaca em aplicações que envolvem dados altamente conectados, enquanto o Amazon DocumentDB oferece compatibilidade com MongoDB, facilitando a migração de aplicações existentes.
Comparativo dos Serviços AWS

O Amazon OpenSearch Service se destaca como uma solução poderosa para a implementação de buscas semânticas e RAG. Sua arquitetura distribuída permite buscas de baixa latência em grandes volumes de dados, tornando-o ideal para aplicações que exigem respostas rápidas e precisas. Além disso, suas capacidades de agregação permitem análises complexas em tempo real, essenciais para insights avançados.
Um diferencial significativo do OpenSearch é seu suporte nativo a vetores, facilitando a implementação de buscas por similaridade em embeddings. Isso é crucial para aplicações de RAG, onde a recuperação eficiente de informações relevantes é fundamental. Ademais, a plataforma oferece dashboards e visualizações integradas, permitindo a criação de interfaces intuitivas para exploração de dados e monitoramento de desempenho.
Principais Funcionalidades

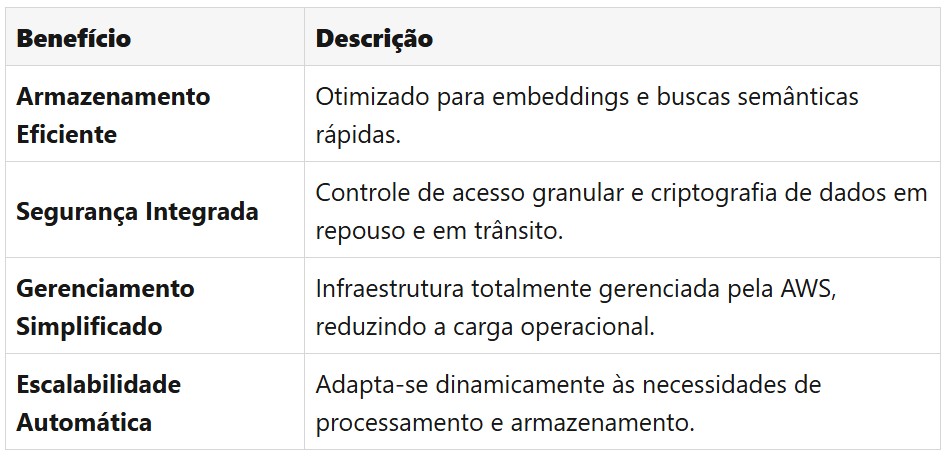
As Knowledge Bases para Amazon Bedrock representam um avanço significativo na implementação de soluções RAG, oferecendo um ambiente totalmente gerenciado que simplifica a integração entre modelos de linguagem e dados corporativos. Esta solução elimina a necessidade de infraestrutura complexa, permitindo que as empresas se concentrem na criação de valor a partir de seus dados, em vez de gerenciar a infraestrutura subjacente.
O coração desta solução é o Vector Engine, um componente especializado para armazenamento e recuperação eficiente de embeddings. Ele permite buscas semânticas rápidas e precisas, essenciais para o RAG. Além disso, as Knowledge Bases oferecem uma conexão segura e controlada entre os modelos de base do Bedrock e os dados da empresa, garantindo a conformidade com políticas de segurança e privacidade.
Benefícios Principais
Os Agentes para Amazon Bedrock representam um salto significativo na automação de tarefas complexas baseadas em IA. Estes agentes são capazes de decompor automaticamente tarefas grandes em subtarefas menores e gerenciáveis, gerando a lógica de orquestração necessária para executá-las de forma eficiente. Esta capacidade de decomposição e orquestração permite a criação de workflows sofisticados que podem lidar com uma ampla gama de cenários e requisitos de negócios.
Uma das características mais poderosas dos Agentes é sua capacidade de se conectar de forma segura com bancos de dados e APIs externas. Isso permite que os agentes acessem e manipulem dados em tempo real, enriquecendo suas respostas e ações com informações atualizadas e relevantes. Além disso, os agentes podem ingerir e estruturar dados de diversas fontes, tornando-os particularmente úteis em cenários que envolvem a integração de múltiplos sistemas e fontes de dados.
Funcionalidades dos Agentes
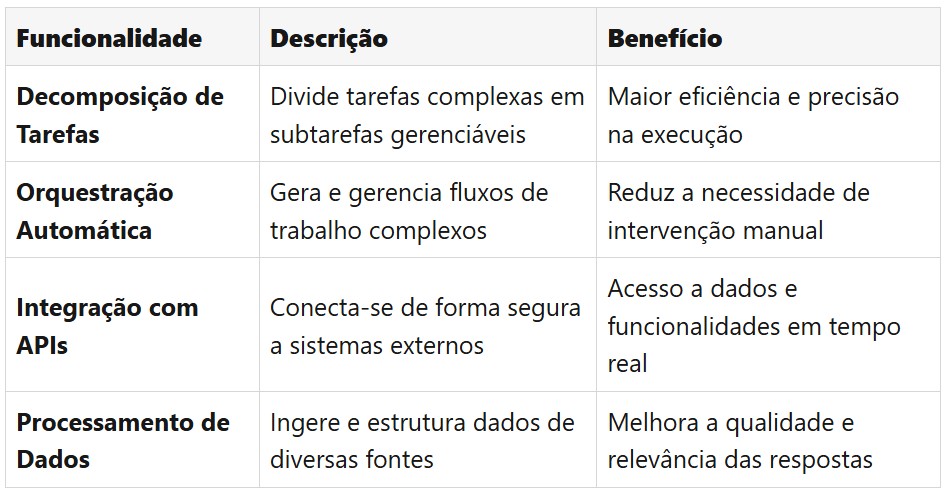
![[instrucao_prompt.png]]
Desenvolvimento de sistemas de IA Éticos e Justos:importância de Modelos Transparentes e Explicáveis
Transparência e Explicabilidade
O que torna um modelo transparente e como ele pode ser explicado adequadamente.
Ferramentas de Explicação
Examinar as ferramentas disponíveis que ajudam a esclarecer os resultados dos modelos.
Trade-offs entre Segurança e Transparência
Analisar as trocas entre manter um modelo seguro e torná-lo compreensível.
Design Centrado no Humano
Descobrir como um design focado nos usuários finais pode tornar a IA mais acessível e compreensível.
![[guardrails_aws_bedrock.png]]
Introdução ao Domínio 4: Diretrizes para IA ResponsávelNeste domínio, focaremos em um aspecto vital do desenvolvimento de inteligência artificial: a responsabilidade. O Domínio 4 é dividido em duas declarações de tarefas principais que exploraremos ao longo das próximas aulas.
Declaração de Tarefa 4.1: Desenvolvimento de Sistemas de IA Éticos e Justos
1. Conceito de IA Responsável
Entender o que significa responsabilidade na IA e por que é importante.
2. Características de Sistemas Responsáveis
Identificar os elementos que tornam um sistema ético, como imparcialidade e equidade.
3. Ferramentas de Implementação
Explorar ferramentas que ajudam a manter a responsabilidade, como avaliação de riscos e gestão de dados.
4. Princípios da IA Responsável
Ver como esses princípios impactam a seleção de modelos, avaliação de riscos e características dos conjuntos de dados.
5. Viés e Variância
Compreender como esses conceitos afetam a confiabilidade dos modelos e as ferramentas para monitorá-los.
Declaração de Tarefa 4.2: Importância de Modelos Transparentes e Explicáveis
Transparência e Explicabilidade
O que torna um modelo transparente e como ele pode ser explicado adequadamente.
Ferramentas de Explicação
Examinar as ferramentas disponíveis que ajudam a esclarecer os resultados dos modelos.
Trade-offs entre Segurança e Transparência
Analisar as trocas entre manter um modelo seguro e torná-lo compreensível.
Design Centrado no Humano
Descobrir como um design focado nos usuários finais pode tornar a IA mais acessível e compreensível.
Preparação para o Exame AWS Certified AI Practitioner
1. Introdução ao Domínio 4
Nesta introdução ao Domínio 4, pretendemos preparar você para entender as diretrizes essenciais que governam o desenvolvimento de uma IA responsável.
2. Próximas Aulas
Nas próximas aulas, discutiremos cada uma das declarações de tarefa com maior profundidade, preparando você para o exame AWS Certified AI Practitioner.
3. Início da Jornada
Vamos começar essa jornada!
Task 4.1 – Aula 01: Desenvolvimento de Sistemas de IA Éticos e Justos
Bem-vindos à aula sobre o desenvolvimento de sistemas de IA éticos e justos. Nesta lição, exploraremos os princípios fundamentais da IA responsável e como implementá-los em sistemas inteligentes.
Introdução à IA Responsável
Vamos começar entendendo o conceito de Inteligência Artificial (IA) responsável. Pense na IA responsável como as diretrizes que garantem que os sistemas de IA operem de maneira segura, confiável e ética.
Dimensões Centrais de um Modelo de IA Responsável:
- Justiça: Tratar todos de maneira equitativa, evitando preconceitos.
- Explicabilidade: Explicar por que um modelo tomou uma decisão específica.
- Robustez: Garantir tolerância a falhas e minimizar erros.
- Privacidade e Segurança: Proteger dados sensíveis.
- Governança: Cumprir normas e gerir riscos.
Dados Éticos
1. Inclusão e Diversidade
Representar uma gama ampla de populações, evitando preconceitos.
2. Conjuntos de Dados Balanceados
Garantir a representação igualitária de todos os grupos.
3. Desequilíbrio de Classes
Técnicas como reamostragem e geração de dados sintéticos podem ajudar.
4. Consentimento e Privacidade
Proteger a privacidade e obter consentimento informado.
Ética na Seleção de Modelos de IA
1. Impacto Ambiental
Priorizar modelos sustentáveis que reutilizem trabalhos existentes.
2. Transparência
Prover informações claras sobre capacidades e limitações do modelo.
3. Accountability
Estabelecer responsabilidades claras pelos resultados.
Task 4.2 – Aula 01: Transparência e Explicabilidade em Modelos de IA
Bem-vindos a uma discussão crucial no universo da IA: a transparência e explicabilidade dos modelos.
Introdução
Entender como a IA toma decisões é crucial para sua adoção e confiança.
O Desafio da Confiança na IA:
- Complexidade: Modelos difíceis de compreender.
- Falta de Transparência: Processos internos obscuros.
- Necessidade de Confiança: Crucial para adoção ampla.
Medindo a Transparência
Dois conceitos principais:
- Interpretabilidade: Compreender o funcionamento interno.
- Explicabilidade: Entender como entradas e saídas estão conectadas.
Ferramentas para Modelos Transparentes e Explicáveis
Software de Código Aberto
Oferece transparência máxima, aumentando a confiança.
Ferramentas da AWS
- AI Service Cards: Detalhes sobre casos de uso e limitações.
- SageMaker Model Cards: Registra toda a jornada do modelo.
- SageMaker Clarify: Investiga e explica decisões de IA.
IA Centrada no Ser Humano
Aprendizado por Reforço com Feedback Humano (RLHF)
- Humanos avaliam respostas da IA.
- Modelo de recompensa aprimora decisões.
Dicas Finais
- Mergulhe nos conceitos: Não decore, entenda!
- Explore os serviços da AWS: Experimente e pratique.
- Pense em casos de uso: Como aplicar no mundo real.
- Foco em segurança e custos: AWS gosta de perguntar sobre isso.
- Faça simulados: Treine bastante!
Com este guia completo e sua dedicação, a certificação AWS AI Practitioner está ao seu alcance. Boa sorte e arrase na prova!
Me segue no linkedin e me manda um pv que envio anotações resumidas e simulados diretos que fiz que me ajudaram ainda mais a passar na prova:
Airton Lira Junior é um profissional de Tecnologia da Informação com mais de 10 anos de experiência, especializado em Big Data, Engenharia de Dados e Arquitetura de Soluções em nuvem. Atualmente atua como Engenheiro Sênior de Dados e Analytics na Dock, liderando melhorias em plataformas de dados, orquestração de pipelines com Databricks e otimização de workloads em AWS (EC2, EMR, SageMaker). Com passagens por empresas como iFood e Bemobi, destacou-se na concepção de soluções inovadoras, como modelos LLM para chatbots, integrações de IA em pipelines de áudio e projetos de conciliação financeira regulatória, utilizando tecnologias como Golang, Python, Apache Spark e Kubernetes. Possui certificações em AWS, Databricks e Power BI, além de formação em Análise de Sistemas pela FIA e especialização em Banco de Dados. Reconhecido por sua proatividade e expertise técnica, contribui ativamente para a comunidade tech como colunista no iMasters, compartilhando conhecimentos em automação, engenharia de prompts e arquitetura de dados escaláveis.