


Documentando automaticamente suas tabelas e colunas do Unity Catalog com AI – DBRX – Databricks
… você documentar automaticamente … suas tabelas e colunas … no Unity Catalog … uma AI de precificação … que é a DBRX-Instruct da Databricks…


Fala galera de Data, espero que todos estejam bem e acompanhando essa nova era da tecnologia que estamos vivenciando e, desta forma, nada melhor do que surfar nesse tsunami do que deixar ele te atingir, não é mesmo? Hoje vou explicar ensinar uma das formas de você documentar automaticamente todas as suas tabelas e colunas que estiverem no Unity Catalog utilizando uma AI de precificação baixa que é a DBRX-Instruct da Databricks, sim isso mesmo automaticamente contudo por que isso é importante?
A utilização de AI com dados corporativos precisam estar o mais “gritante” possível do que se trata, em outras palavras seu datalake precisa estar bem organizado desde definição da arquitetura de dados até nome de colunas, tabela, schema etc.. além é claro de documentar sobre do que se trata aquele banco de dados, schema, tabela e coluna e o que for mais possível documentar. Isso é muito importante por que quando você precisar e você VAI PRECISAR criar uma solução de AI, muito provavelmente você vai utilizar a técnica de RAG e passar para um Banco de dados Vetorial os seus dados e é aqui que entra a relevância da documentação. Para quem não sabe quando mais contexto o LLM receber melhor e mais rápido é a resposta, isso é devido entre outras variáveis ao contexto que você forneceu, aumentando a precisão de similaridade entre o que você quer saber.
Requisitos para auto documentar minhas tabelas e colunas:
- Obviamente as tabelas devem estar no Unity catalog.
- Ter habilitado a nível de workspace o uso da API DBRX.
- Criação de um Token de usuário ou de service principal.
Vamos documentar automaticamente uma tabela:
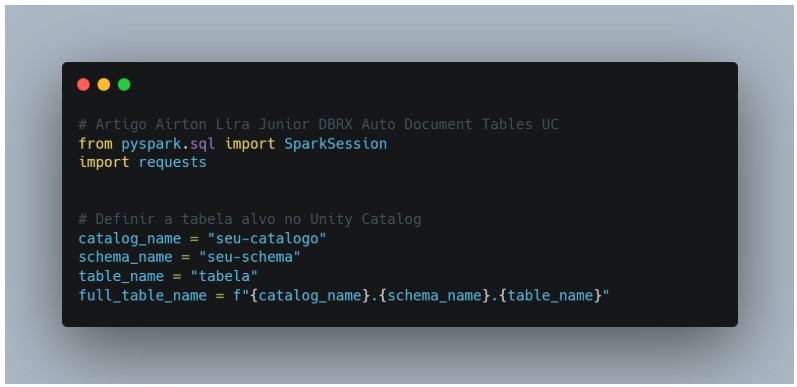
Vamos importar o pacote de request para chamar a API DBRX com o prompt e o SparkSession para montagem da Sessão referente a aplicação em execução no cluster Spark:
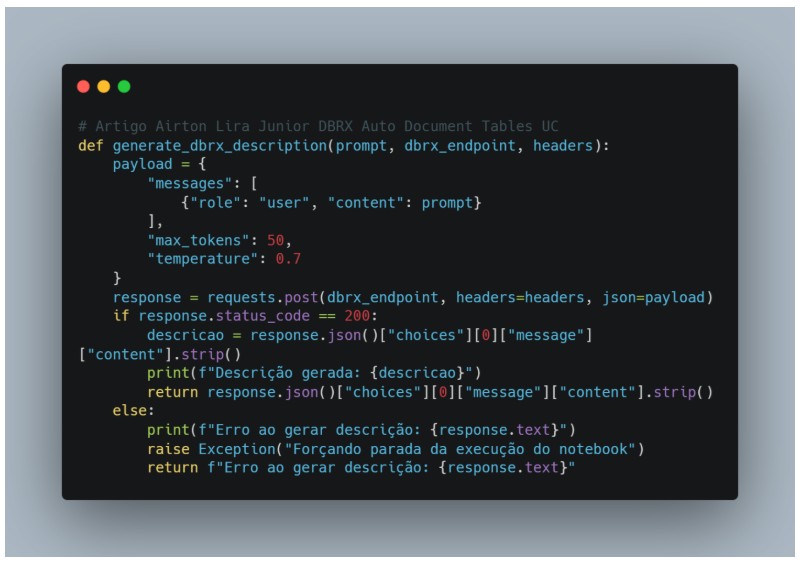
Posteriormente, vamos montar uma função que vai retornar a descrição efetuada pela chamada da API, mas já com alguns atributos importantes como max_tokens que é a quantidade máxima de palavras que você deseja considerar no retorno da API e o parâmetro de temperature que é o nível de criatividade do modelo, existem outros parâmetros mas estes são essenciais.
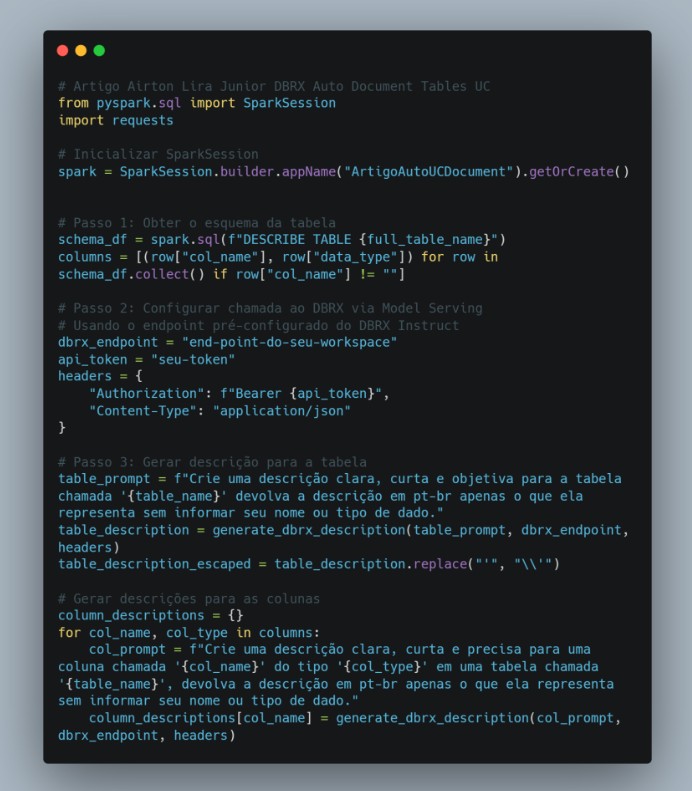
Agora vamos de fato fazer a chamada e a montagem dos prompts. Este código Python utiliza o Apache Spark para gerar automaticamente descrições de uma tabela e suas colunas, empregando o serviço DBRX Instruct da Databricks.
Detalhamento das etapas:
- Importação de bibliotecas:
- Inicialização da SparkSession:
- Obtenção do esquema da tabela:
- Configuração da chamada ao DBRX via Model Serving:
- Geração da descrição para a tabela:
- Geração de descrições para as colunas:
Durante a execução você terá um output semelhante a este:

Agora com as descrições das colunas e da tabela hora de aplicar de fato na tabela alterando as propriedades:
Por fim você pode da um comando de DESCRIBE TABLE EXTENDEDpara visualizar a documentação na tabela e nas colunas.
Aqui foi apenas um exemplo simples em uma única tabela, você pode utilizar outros LLM além do DBRX bem como ir ajustando os parâmetros e o prompt para melhorar de acordo com seu cenário.
Fontes: https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
Airton Lira Junior é um profissional de Tecnologia da Informação com mais de 10 anos de experiência, especializado em Big Data, Engenharia de Dados e Arquitetura de Soluções em nuvem. Atualmente atua como Engenheiro Sênior de Dados e Analytics na Dock, liderando melhorias em plataformas de dados, orquestração de pipelines com Databricks e otimização de workloads em AWS (EC2, EMR, SageMaker). Com passagens por empresas como iFood e Bemobi, destacou-se na concepção de soluções inovadoras, como modelos LLM para chatbots, integrações de IA em pipelines de áudio e projetos de conciliação financeira regulatória, utilizando tecnologias como Golang, Python, Apache Spark e Kubernetes. Possui certificações em AWS, Databricks e Power BI, além de formação em Análise de Sistemas pela FIA e especialização em Banco de Dados. Reconhecido por sua proatividade e expertise técnica, contribui ativamente para a comunidade tech como colunista no iMasters, compartilhando conhecimentos em automação, engenharia de prompts e arquitetura de dados escaláveis.



