


Feature Engineering para Embeddings com SparkML e MLFlow no Databricks Experiments
Neste artigo vou demonstrar como utilizar a lib do spark de machine learning e criar o experimento ou seja a pipeline no MLFlow dentro do Databricks.


Hoje resolvi relembrar alguns conceitos de machine learning e entre eles a parte de vetorização de categorias para ter um dataset mais apto para deep learning (Redes neurais). Portanto neste artigo vou demonstrar de forma pura como utilizar a lib do spark de machine learning e criar o experimento ou seja a pipeline no MLFlow dentro do Databricks.
Escolhendo um dataset adequado:
Para este artigo vou utilizar um dataset publico do Kaggle chamado parking transaction que é um dataset em csv que contém registros de transações de estacionamento de várias fontes, incluindo medidores de estacionamento e aplicativos de pagamento móveis.
-> https://www.kaggle.com/datasets/aniket0712/parking-transactions
Agora vamos montar o notebook e realizar uma série de passos para fazer feature engineering, especificamente para criar embeddings **categóricos usando Apache Spark e técnicas de **NLP (Natural Language Processing). Vou detalhar cada célula e seu objetivo principal.
📌Requisitos:
- Databricks (recomendado) ou um ambiente com Apache Spark configurado (Spark 3.0 ou superior recomendado).
- Suporte para PySpark (Python API para Spark) pyspark (Spark ML)
- kagglehub (para baixar datasets do Kaggle)
- mlflow (para registro de modelos no MLflow)
Caso esteja utilizando o Databricks, você só precisa instalar a lib do kagglehub.
📌. Kaggle Authentication (opcional):
Caso execute localmente ou fora do Databricks, precisará configurar o acesso ao Kaggle:
- Autentique no Kaggle criando uma API Key em https://www.kaggle.com/settings/account.
- Baixe o arquivo kaggle.json e coloque-o em:
~/.kaggle/kaggle.json
- Dê as permissões adequadas:
chmod 600 ~/.kaggle/kaggle.json
Nota: No Databricks, pode ser mais fácil baixar manualmente o dataset ou usar uma integração alternativa (como upload direto).
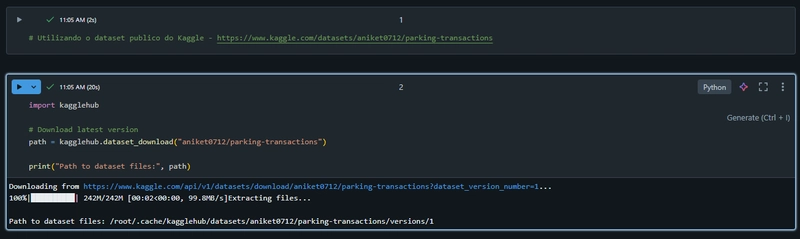
Copiar dados para o DBFS (Databricks File System):
O arquivo baixado localmente é copiado para o DBFS, ambiente Databricks que permite processamento distribuído no Spark.
Carregar o dataset no Spark DataFrame:
Os dados são carregados em um DataFrame Spark para processamento distribuído.

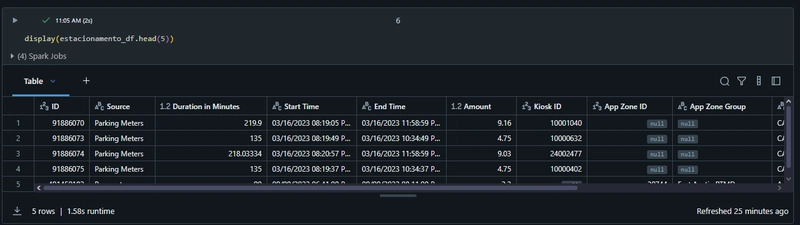
Seleção e tratamento inicial de colunas:
Apenas colunas relevantes são selecionadas: “Source”, “Duration in Minutes”, “App Zone Group”, “Payment Method”, “Location Group”, “Amount”.
Valores null são tratados explicitamente, substituindo por valores apropriados para evitar problemas nas etapas seguintes.
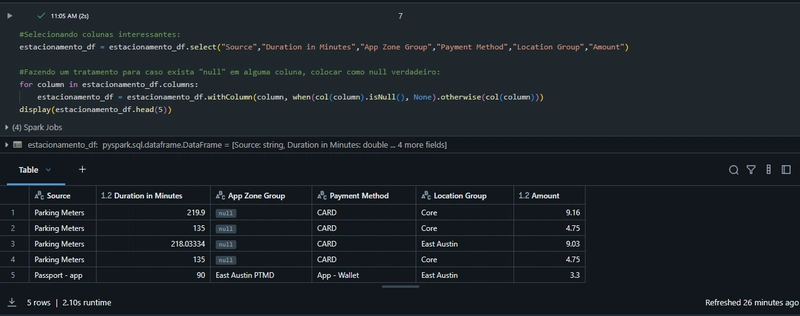
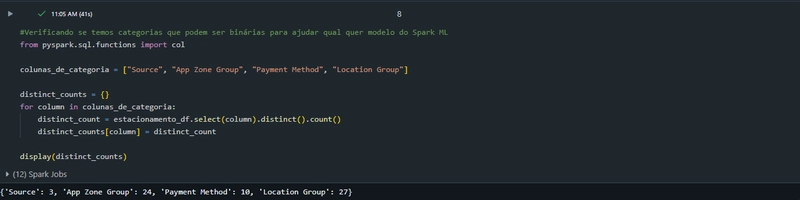
Identificação de variáveis categóricas:
As colunas categóricas (“Source”, “App Zone Group”, “Payment Method”, “Location Group”) são avaliadas para verificar o número de categorias únicas que cada uma contém, ajudando a decidir quais serão usadas no embedding.
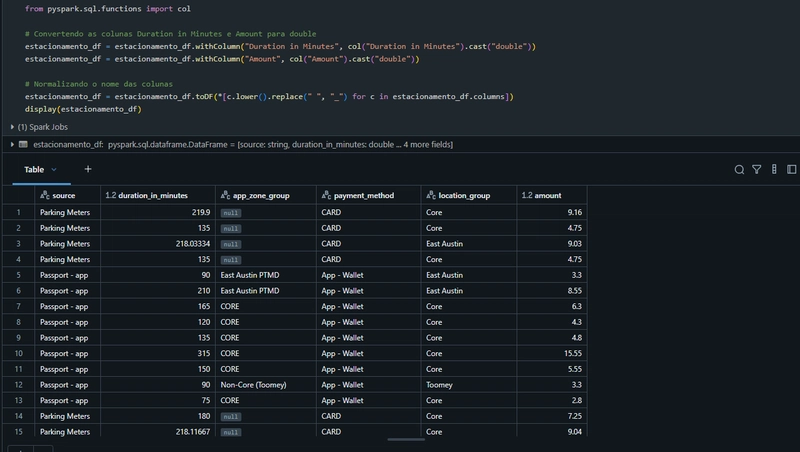
Ajuste de tipos e nomes das colunas:
As colunas numéricas são convertidas para tipo double.
O nome das colunas é normalizado para o formato snake_case (ex.: “Duration in Minutes” para “duration_in_minutes”).
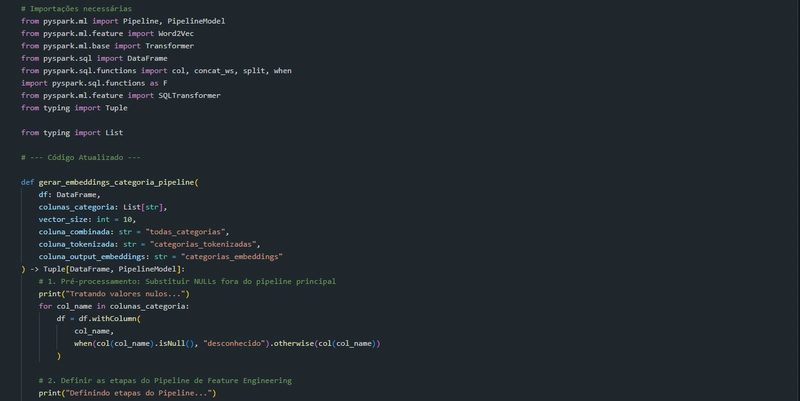
Função para gerar embeddings com Word2Vec:
Essa é a principal célula do notebook. Aqui ocorre a criação de embeddings categóricos.
O processo envolve:
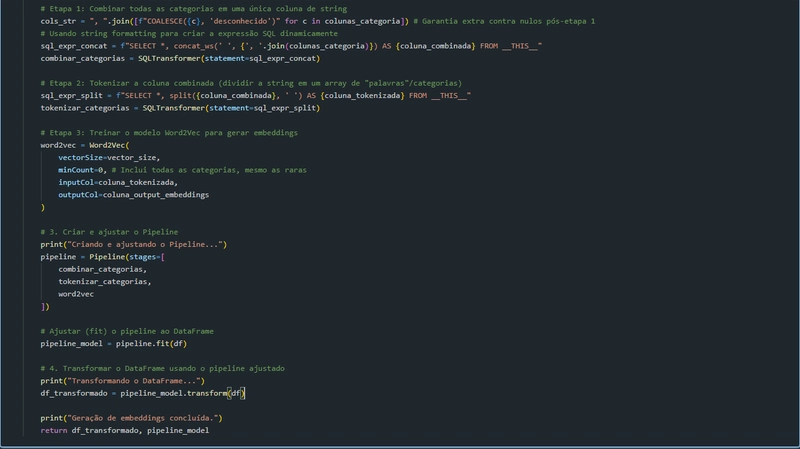
- Combinação de categorias: Todas as colunas categóricas são concatenadas em uma única coluna de texto.
- Tokenização: Essa coluna combinada é dividida em tokens individuais (palavras).
- Treinamento Word2Vec: Um modelo Word2Vec é treinado nos tokens categóricos. Este modelo captura a semântica das categorias ao gerar representações numéricas (vetores).
- Pipeline Spark ML: Essas etapas são encapsuladas em um pipeline Spark, que facilita a execução sequencial e reutilização do processo.
Motivos do uso do Word2Vec:
Representação numérica semântica: Captura similaridades entre categorias, ajudando modelos posteriores a entender relações implícitas.
Eficácia em modelos ML: Os embeddings produzidos são úteis em modelos de aprendizado profundo, banco de dados vetoriais e ou outros modelos Spark ML que precisam de inputs numéricos contínuos.
Transformar variáveis categóricas em representações vetoriais (embeddings) com o modelo Word2Vec, além de registrar o pipeline resultante no MLflow para garantir rastreabilidade e versionamento.
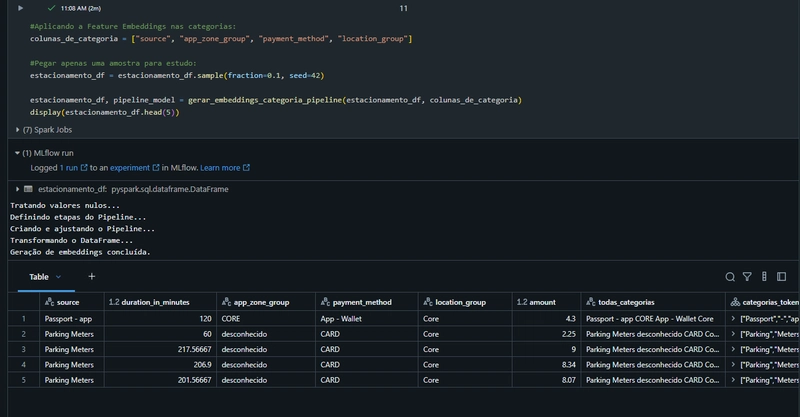
- Seleção de Categorias para Embeddings
Primeiramente, definimos as variáveis categóricas que serão convertidas em embeddings. - Amostragem dos Dados
Em seguida, selecionamos uma amostra menor dos dados originais para fins de demonstração, economizando tempo computacional. - Construção da Pipeline de Embeddings
Construímos então uma pipeline personalizada com Spark ML, que executa os seguintes passos automaticamente:
- Tratamento de valores nulos (substituindo por “desconhecido”).
- Combinação das categorias em uma única string (coluna intermediária todas_categorias).
- Tokenização dessa string em tokens individuais (coluna categorias_tokenizadas).
- Geração de embeddings via modelo Word2Vec (vetores armazenados na coluna categorias_embeddings).
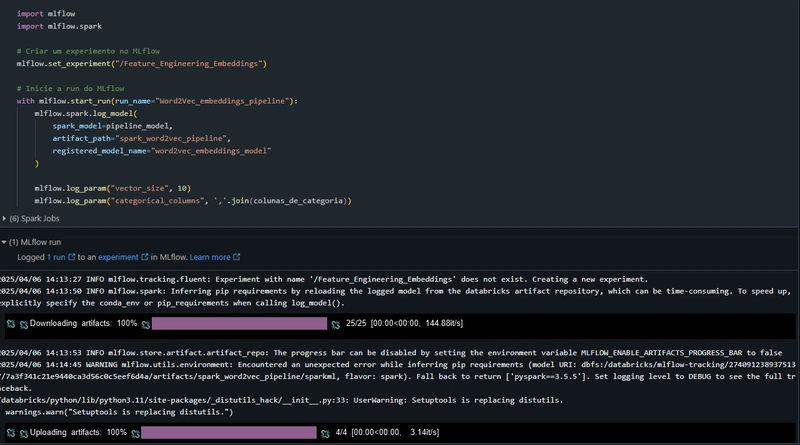
Registro da Pipeline no MLflow
A pipeline treinada é registrada no MLflow, uma plataforma aberta para gerenciar o ciclo de vida de modelos de Machine Learning, permitindo versionamento, reproducibilidade e compartilhamento:
Conclusão e motivo para eu relembrar e escrever este artigo:
Quando falamos de embeddings para serem armazenados em um Vector Database com o objetivo posterior de aplicar técnicas como Retrieval-Augmented Generation (RAG), existem essencialmente duas abordagens populares:
- API de Embeddings (Ex.: OpenAI, Cohere, Hugging Face)
- Treinamento local de embeddings (Ex.: Spark Word2Vec)
Ambas têm vantagens e desvantagens importantes que podem definir claramente a melhor escolha para seu caso específico.
API de Embeddings (OpenAI, Cohere, Hugging Face)
Exemplos populares:
- OpenAI Embeddings API (text-embedding-ada-002).
- Cohere Embeddings.
- Hugging Face API (Sentence-BERT).
Pontos Fortes ✅:
- Alta qualidade dos embeddings: já treinados em datasets massivos.
- Sem necessidade de infraestrutura própria: rápida integração, sem overhead técnico.
- Bom para RAG: Embeddings semânticos profundos otimizados para buscas contextuais.
Pontos Fracos ❌:
- Custo variável: Pode se tornar caro com grandes volumes.
- Latência da API: Depende da disponibilidade externa (tempo de resposta).
- Privacidade e compliance: Seus dados saem da sua infraestrutura.
Por que os Embeddings são essenciais para um Vector Database e RAG?
Em um fluxo de Retrieval-Augmented Generation (RAG):
Geração dos embeddings:
O texto/documento é convertido em vetores (embeddings).
Armazenamento em vector database (Qdrant, Pinecone, Chroma):
Armazena esses vetores para buscas rápidas baseadas em similaridade.
Retrieval eficiente:
Ao receber um prompt, converte-se em embeddings e realiza busca por similaridade no Vector Database, retornando o contexto mais relevante para o modelo generativo
Portanto espero que tenham gostado, deixo abaixo meu Linkedin e Repositório do projeto:
Airton Lira Junior é um profissional de Tecnologia da Informação com mais de 10 anos de experiência, especializado em Big Data, Engenharia de Dados e Arquitetura de Soluções em nuvem. Atualmente atua como Engenheiro Sênior de Dados e Analytics na Dock, liderando melhorias em plataformas de dados, orquestração de pipelines com Databricks e otimização de workloads em AWS (EC2, EMR, SageMaker). Com passagens por empresas como iFood e Bemobi, destacou-se na concepção de soluções inovadoras, como modelos LLM para chatbots, integrações de IA em pipelines de áudio e projetos de conciliação financeira regulatória, utilizando tecnologias como Golang, Python, Apache Spark e Kubernetes. Possui certificações em AWS, Databricks e Power BI, além de formação em Análise de Sistemas pela FIA e especialização em Banco de Dados. Reconhecido por sua proatividade e expertise técnica, contribui ativamente para a comunidade tech como colunista no iMasters, compartilhando conhecimentos em automação, engenharia de prompts e arquitetura de dados escaláveis.


