

Este artigo foi publicado em 23/09/2015. Por ter sido considerado um dos melhores artigos de 2015, foi republicado hoje
Lembro bem quando Cassio Politi falou comigo, nos primeiros meses da Tracto, sobre uma ideia apaixonante e capaz de fazer todo sentido. Na época, o mote da empresa era “conhecimento na prática” – que, no fundo, permaneceu implícito. “Precisamos mudar isso. É obrigatório estabelecermos nossa posição e se aprofundar nesse tema”, dizia. Foi quando a frase foi substituída pelo termo content marketing.
O rumo foi ajustado, mas eu insistia em compartilhar com ele a minha angústia. “O que content marketing significa de verdade? Qual a força desse conceito? Ou, mais importante ainda, o que content marketing não significa? Em que ele é diferente de algo que já existe ou melhor? Por quanto tempo essa ideia consegue se segurar sem ser questionada, tratada como algo consistente?”.
Estrategicamente, a Tracto é pioneira do assunto no Brasil, rótulo evidenciado tanto pelo livro quanto pelo histórico de artigos no site. Meus questionamentos, no entanto, permanecem firmes: enquanto nosso trabalho procura verificar permanentemente os limites e virtudes de uma técnica envolvendo definição de objetivos, produção de conteúdo relevante e escolha adequada de canais e métricas, nunca se falou tanto em “marketing de conteúdo” mundo afora. E a web tupiniquim trata de propagar boa parte do discurso.
Mais: a ideia por trás do content marketing se confunde com outras expressões mercadologicamente impactantes, mas que balançam diante da provocação concentrada na pergunta “o que é exatamente?”. Ou as expressões custom publishing, branded content, private media, content strategy, native advertising, inbound marketing, corporate storytelling não parecem significar a mesma coisa?
Inteligência dos metadados
Paralelamente ao meu envolvimento com content marketing, tenho profundo interesse na relação entre processos de comunicação e no constante envolvimento de computadores nesse contexto. Em minha pesquisa de doutorado, desenvolvo a seguinte hipótese: informações publicadas na Web podem ser fortemente enriquecidas por metadados, aumentando seu poder de fogo e permitindo o desenvolvimento de ferramentas e possibilidades capazes de dar fôlego a veículos, organizações e, evidentemente, usuários interessados em conteúdo.
Compartilho aqui uma síntese do conceito principal:
Metadados são rótulos capazes e estruturar dados armazenados em databases, assim informações podem ser compreendidas tanto por humanos quanto por máquinas. Isso vai além das categorias e tags de um blog, ou mesmo aquelas marcações HTML, comuns em processos de SEO: metadados contextualizam objetos e suas relações com outros conceitos por meio de regras de armazenamento, sintaxes e esquemas envolvendo relacionamentos e significados. Metadados são fundamentais para a criação, descrição, organização, atualização, reutilização, validação, recuperação e preservação de informações.
E qual a força desse conceito? Bom, essencialmente, encontramos a ciência da informação e a biblioteconomia preocupados desde sempre em construir esquemas, ontologias ou outras estruturas para indexar informação e recuperá-la da melhor forma; na ciência da computação e em sua presença firme inclusive nas tradicionais humanidades, vimos máquinas de elevada capacidade de processamento lidar com volume de dados, buscar padrões entre eles e ajudar a solucionar problemas ou mesmo encontrar novas perguntas; finalmente, com a popularização da Web nos últimos 25 anos, a visão de seu criador Tim Berners-Lee estimula um cruzamento destas e de outras áreas do conhecimento em busca de uma estruturação semântica da rede.
São trilhas de conhecimento fascinantes, que exigem um indispensável esforço multidisciplinar.
Estratégias de conteúdo inteligente
Foi por conta desta pesquisa que cheguei ao livro Managing Enterprise Content, de Ann Rockley e Charles Cooper. A publicação apresenta às organizações uma forma pragmática de resolver problemas e otimizar processos a partir de uma percepção: não faz sentido armazenar conteúdo relevante como se estivessem empilhados desordenadamente. Pior: tal prática revela-se uma armadilha.
Desde a publicação do livro, em 2012, os autores traziam seu conceito de intelligent content: trata-se de um conteúdo estruturalmente rico e semanticamente categorizado, permitindo formas automatizadas de descobri-lo, reutilizá-lo, reconfigurá-lo e adaptá-lo. Isso inclui o design de metadados, entre outras maneiras de formalizar a estrutura de seu conteúdo em modelos e relacioná-la com uma estratégia, baseada nos requisitos do negócio, e a tecnologias (como o formato XML).
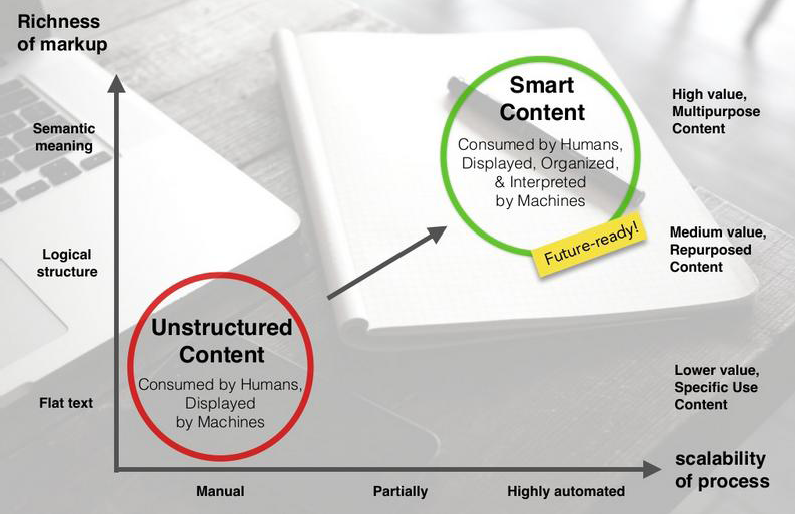
(Para conhecer melhor o tema, sugiro este e-book do CMI: Getting Started with Intelligent Content)
Mais inteligência, menos buzzword
Seja no campo acadêmico, onde o esforço para construir conexões entre ideias e suas origens tendem a deixá-las mais fortes, seja no dia-a-dia de mercado, onde é preciso agilidade e criatividade para solucionar os pain points das organizações: propostas incríveis como as que cercam o conceito de “conteúdo inteligente” merecem ser aplicadas na prática e, ao mesmo tempo, ganharem reforço concreto em sua base.
Dessa forma, vi com um misto de felicidade e preocupação a percepção do Cassio Politi durante o Content Marketing World: “uma das tendências do content marketing que será cada vez mais discutida é o conteúdo inteligente”. Ao mesmo tempo em que torço para que mais gente queira dialogar sobre estas possibilidades e pavimentar algumas possibilidades interessantes, temo pelos maus tratos que qualquer buzzword enfrenta quando se populariza.
Afinal, nem todo mundo quer saber “o que isso realmente quer dizer”, enfraquecendo uma boa ideia a partir de práticas questionáveis pautadas pelo hype. Exatamente como acontece hoje com content marketing.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?