

Artigo escrito em parceria com Paulo Elias*
Um dos componentes mais importantes de um sistema gerenciador de bancos de dados (SGBD) é o seu otimizador de consultas. É ele quem decide como transformar as declarações SQL que escrevemos numa sequência de ações que será executada de forma confiável e eficiente, conhecida como “plano de execução”.
Porém, os otimizadores de consultas não são mecanismos à prova de falhas. Eventualmente acontecem situações onde o otimizador não tem informações adequadas para tomar as decisões, gerando resultados abaixo da expectativa. Estas “falhas” podem ocorrer por uma série de razões. As principais delas talvez sejam a inexistência de estatísticas de uso de índices e/ou a existência de estatísticas desatualizadas.
Os principais fornecedores de sistemas gerenciadores de bancos de dados (SGBDs) oferecem em seus softwares extensões da linguagem SQL para que o próprio desenvolvedor forneça dicas (ou hints, em inglês) de como sua consulta deve ser executada. A função destas dicas, ao final das contas, é especificar os métodos que serão usados em determinadas etapas do plano de execução de uma consulta, desprezando a análise/recomendação do otimizador de consultas.
Porém devemos lembrar que o otimizador de consultas é um mecanismo dinâmico, que adequa o plano de execução às condições atuais das tabelas envolvidas, bastando que as estatísticas da tabela e/ou índice estejam atualizadas. Por exemplo: conforme aumenta e/ou diminui a quantidade de registros nas tabelas da consulta, o otimizador pode se decidir pelo método A ou método B para execução de um determinado passo do plano.
Portanto, quando o desenvolvedor decide usar estas dicas, ele está adotando uma solução rígida, que não vai mudar conforme mudam as características das tabelas. É por isso que os DBAs recomendam fortemente que se evite o uso de dicas SQL, deixando a definição do plano de execução a cargo do otimizador de consultas. Dicas só devem ser usadas se o desenvolvedor conhecer muito bem a situação que está tratando ou se identificar um comportamento inconsistente por parte do otimizador de consultas.
Neste artigo, os autores apresentam um estudo de caso real onde foi identificado um aparente “comportamento inconsistente” do otimizador de consultas do SQL Server 2008 R2.
Planos de execução e os métodos de junção do SQL Server
O plano de execução de uma consulta é, em última análise, um roteiro detalhado das operações conduzidas pelo SGBD para chegar ao resultado desta consulta. O plano mostra cada operação que é executada, quais os parâmetros envolvidos, o seu custo de execução e o custo acumulado de toda árvore de operações anteriores. Com isso conseguimos identificar quem são as operações mais “custosas” de cada consulta.
Este valor de custo é um número adimensional que expressa uma ponderação entre o custo de processamento e custo de acesso a disco. Estes números são bastante diferentes para cada SGBD. No caso do SQL Server, consultas simples tem custo menor que 1,0. Consultas complexas passam de 100,0.
Um dos tipos de operação mais pesados em uma consulta é a junção de tabelas. De forma genérica, os otimizadores de consultas dos SGBDs optam entre três diferentes métodos para realizar a junção entre duas tabelas: HASH JOIN, MERGE JOIN e NESTED LOOP. Estes três métodos também são usados no SQL Server e a seguir apresentamos uma breve descrição deles:
- HASH JOIN: neste método, cria-se uma tabela com a lista de campos pesquisados (com base nos valores da menor das duas tabelas) e os registros da outra tabela são comparados com os valores da tabela construída;
- MERGE JOIN: quando as tabelas são grandes e possuem índices apropriados, geralmente o otimizador de consultas prefere este método;
- NESTED LOOP: quando uma das tabelas envolvidas não for tão grande ou quando os dados não estiverem ordenados, este método costuma ser mais eficiente.
O leitor interessado encontrará muita informação sobre os planos de execução e os tipos de junção. Nós sugerimos que você veja a série de artigos de Darren White sobre os planos de execução (veja Referências).
O problema
Recentemente identificamos uma consulta importante de um sistema usado na nossa empresa que estava sofrendo com problemas de performance.
Estudos iniciais mostravam um plano de execução de custo baixo (0,466976). E este custo era condizente com uma consulta que retornava apenas 254 registros. A Figura 1 mostra o plano de execução desta consulta.
Figura 1: Custo total da consulta segundo o plano de execução original:
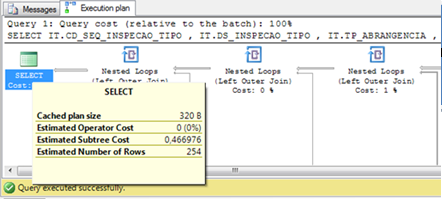
Porém o tempo de resposta da consulta era da ordem de 40 segundos, que é um tempo astronômico para uma consulta que envolve tabelas pequenas (como era o caso) e retorna poucos registros.
Uma análise mais profunda mostrou que a consulta em questão usava uma visão que rodava num servidor externo (um linked server). Mais que isso, esta visão montava uma lista parecida com um organograma da empresa, que por sua vez era construída através de uma expressão de tabela recursiva (normalmente chamada de CTE recursiva).
A nossa questão era: como melhorar a performance da nossa consulta?
A proposta
Depois de analisarmos detalhadamente a consulta e o seu plano de execução, observamos que o custo do passo que tratava da junção das tabelas com a visão externa representava apenas 1% do custo total da consulta. Isso era estranho, especialmente em se tratando de um “linked server”. Este detalhe é mostrado na Figura 2.
Figura 2: detalhe do plano de execução da consulta original:
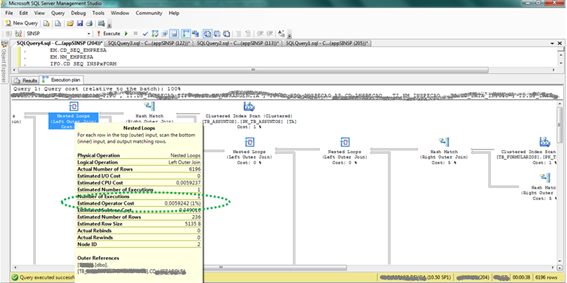
Como se pode observar na Figura 2, o otimizador estimava que esta junção trabalharia com apenas 236 registros, mas ela trabalhou de fato 6196 registros. Veja parâmetros “Estimated Number of Rows” e “Actual Number of Rows”, respectivamente. Esta diferença entre a estimativa e o resultado real era mais um indicativo que este plano de execução provavelmente não estava otimizado.
Por conta disso, resolvemos testar uma abordagem diferente. Como citamos anteriormente, o otimizador de consultas pode executar junções através de três métodos e que o método mais apropriado quando uma das “tabelas” é pequena é método HASH JOIN. Sendo assim, aparentemente a escolha do HASH JOIN poderia trazer resultados melhores.
Para forçar o otimizador a usar este método de junção, usamos a dica SQL “HASH JOIN”. A sintaxe é muito simples: basta editar a declaração SQL e substituir a palavra JOIN pela expressão HASH JOIN.
Assim declarações ‘[INNER/LEFT/RIGHT] JOIN’ se transformam em ‘[INNER/LEFT/RIGHT] HASH JOIN’.
Resultados com a dica HASH JOIN
Neste teste executamos a consulta original (que chamamos de ORIG) e a consulta com HASH JOIN (que chamamos de HASH) e anotamos o custo total de cada consulta e o tempo de execução. A Listagem 1 documenta as sintaxes das consultas ORIG e HASH.
Listagem 1: alterações de sintaxe na consulta para uso da dica HASH JOIN:

Na Listagem 2, apresentamos o modelo de script para coleta do tempo de execução de cada consulta.
Listagem 2: coletando tempo de resposta da consulta:
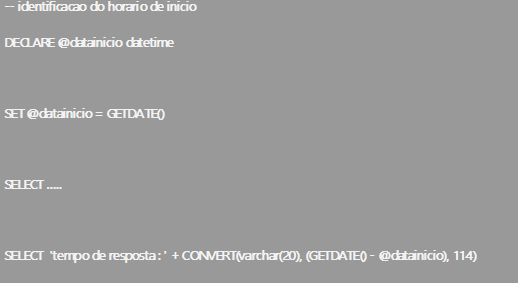
Feitos os testes, tivemos resultados ainda mais estranhos. A Tabela 1 mostra o custo e o tempo de execução de cada consulta.
Tabela 1: resumo dos resultados:
| Consulta |
Custo |
Tempo de resposta (seg) |
| ORIG |
0,466976 |
37,79 |
| HASH |
0,69 |
1,63 |
| Diferença |
48% maior |
23 VEZES menor |
O custo da consulta HASH era 48% maior do que o da consulta ORIG. Se nossa decisão se baseasse exclusivamente em custo, não haveria espaço para uso do HASH JOIN.
Mas enquanto a consulta original (ORIG) rodou em 37,79 segundos, a consulta HASH rodou em apenas 1,63 segundos. Portanto a consulta HASH usou cerca de 4% do tempo consumido pela consulta ORIG, ou seja, ela era 23 vezes mais rápida.
Se o que realmente nos interessa é o tempo de resposta de uma consulta, pq o custo da consulta HASH era mais elevado se ela era absurdamente mais rápida do que a consulta ORIG?
De fato é de se esperar algum impacto em performance quando tratamos de objetos externos ao banco. Muito mais grave do que isso, neste caso específico a visão externa se baseava numa CTE recursiva. Este é um recurso SQL muito poderoso, mas que inspira enormes cuidados.
O que parece ter ocorrido aqui é que o otimizador de consultas não soube avaliar adequadamente o tamanho da listagem que seria retornada pela visão (leia-se: pela CTE recursiva). O tamanho final da listagem dependeria do número de iterações do processo recursivo e seria muito difícil para o otimizador estimar esta variável.
Consequentemente o otimizador de consulta não tinha informações adequadas para escolher entre os métodos HASH (para tabelas pequenas), MERGE(para tabelas grandes) ou NESTED LOOP (para situações intermediárias). Nesta situação, o otimizador tomou uma decisão de segurança e escolheu o NESTED LOOP, que poderia se “adaptar” a qualquer um dos três cenários descritos.
A decisão é correta tendo em vista a falta de informações para a tomada de decisão. Mas, como vimos, esta decisão tecnicamente correta levou a resultados práticos de péssima qualidade.
Isso não quer dizer necessariamente que esta decisão do otimizador de consultas fosse ruim. A decisão não era adequada para a situação em que se encontravam as tabelas envolvidas. Os resultados poderiam ser completamente diferentes se a CTE recursiva retornasse uma quantidade maior de registros.
Conclusão
Como vimos aqui, foi necessário um estudo detalhado para se entender porque uma consulta aparentemente simples apresentava um desempenho muito inferior ao esperado.
Observe que nossa decisão de testar uma dica SQL (“HASH JOIN”) só foi cogitada depois de que foram constatadas evidências que demostravam a existência de um problema no plano de execução. Desprezar recomendações do otimizador de consultas nunca é uma boa prática!
Porém os testes mostraram que o uso da dica SQL se mostrou muito mais eficiente do que o uso da recomendação do otimizador, mas isso dentro do contexto da aplicação que descrevemos aqui.
Otimizadores adaptam suas recomendações conforme o banco de dados vai sendo utilizado. E, como foi dito, a qualidade destas recomendações depende apenas da existência de estatísticas atualizadas.
Ao final de contas, entendemos que este estudo de caso nos permite tirar uma série de recomendações importantes sobre os otimizadores de consulta:
- Otimizadores de consulta usam algoritmos eficientes que baseiam suas decisões em estatísticas de tabelas e índices (tamanho, número de registros, índices disponíveis, etc);
- É fundamental manter atualizadas as estatísticas de tabelas/índices para não comprometer as decisões tomadas pelo otimizador de consultas;
- DBAs e desenvolvedores devem sempre se lembrar que a qualidade dos planos de execução gerados está intimamente relacionada com a atualização das estatísticas;
- DBAs e desenvolvedores devem se lembrar que as recomendações do otimizador devem sempre ser vistas como a referência principal;
- Caso haja evidências em contrário, deve-se avaliar o que está acontecendo no caso em estudo;
- Dicas SQL só devem ser usadas em situações extremas e com profundo conhecimento de causa;
- Em caso de dúvida, sempre analise o plano de execução da consulta.
Referências
- BEN-GAN, ltzik & DELANEY, Kalen. Advanced JOIN Techniques – Save time and improve performance. SQL SERVER PRO. 23/10/1999. http://sqlmag.com/database-performance-tuning/advanced-join-techniques;
- MICROSOFT. Query Hints (Transact-SQL). MICROSOFT TECHNET. http://technet.microsoft.com/en-us/library/ms181714(v=sql.105).aspx;
- WHITE, Darren. Understanding Graphical Execution Plans – Part 3: Analyzing the Plan. SQL Server Central. 25/02/2014. http://www.sqlservercentral.com/articles/Execution+Plans/105810;
- KEJSER, Thomas. The Ascending Key Problem in Fact Tables– Part one: Pain! Blog “KEJSER”. 01/07/2011. http://blog.kejser.org/2011/07/01/the-ascending-key-problem-in-fact-tables-part-one-pain/;
- LITTLE, Kendra. Query Plans: What Happens when Row Estimates Get High. Blog “BRENT OZAR”. 28/08/2013. http://www.brentozar.com/archive/2013/08/query-plans-what-happens-when-row-estimates-get-high/
*Paulo Roberto Elias é formado em Administração de Empresas e Especialista em TI, hoje é Analista de Sistemas .NET. Entusiasta Oracle e SQL Server, tecnologias nas quais tem se especializado nos últimos anos.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?