


Métricas para algorítimos de regressão
Neste artigo vamos abordar as principais métricas de erro para algorítimos de regressão efetuando os cálculos manualmente em Python e medindo o erro

Quando elaboramos um algorítimo de regressão e queremos saber o quão eficiente foi esse modelo, utilizamos de métricas de erro para obter valores que representam o erro do nosso modelo de machine learning, portanto as métricas desse artigo são importantes quando queremos medir o erro de modelos de previsão de valores numéricos (reais, inteiros) . Neste artigo vamos abordar as principais métricas de erro para algorítimos de regressão efetuando os cálculos manualmente em Python e medindo o erro do modelo de machine learning de um dataset de cotação de dolar, as métricas abordadas são:
- SE – Sum of error.
- ME – Mean error.
- MAE – Mean Absolute error.
- MPE – Mean Percentage error.
- MAPAE – Mean Absolute Percentage error.
Ambas as métricas são um pouco parecidas, onde temos métricas para media e porcentagem do erro e métricas para media e porcentagem absoluta do erro, diferenciado assim apenas que um grupo obtêm o valor real da diferença e o outro obtêm o valor absoluto da diferença, importante lembrar que ambas as métricas quanto menor o valor, melhor esta minha previsão.
SE – Sum of error.
A métrica SE é a mais simples dentre todas desse artigo, onde sua formula é SE = εR – P. Portanto se trata do somatório da diferença entre o valor real (variável alvo do modelo) e o valor previsto, esta métrica tem alguns pontos negativos como por exemplo não tratar os valores como absolutos o que consequentemente vai resultar em um valor falso.
ME – Mean of error.
A métrica ME é um “complemento” da SE, onde temos basicamente a diferença de que vamos obter uma média do SE diante da quantidade de elementos, portanto:
ME = ε(R-P)/N
Diferente do SE, apenas dividimos o resultado do SE pela quantidade de elementos, esta métrica assim como a SE depende de escala, ou seja, devemos usar o mesmo conjunto de dados e podemos comparar com modelos de previsão diferentes.
MAE – Mean absolute error.
A métrica MAE é o ME mas considerando apenas valores absolutos (não negativos), quando estamos calculando a diferença entre o real e o previsto, podemos ter resultados negativos e essa diferença negativa é aplicada nas métricas anteriores, já nesta métrica temos que transformar a diferença em valores positivos e posteriormente tirar a média com base no numero de elementos.

MPE – Mean Percentage error.
A métrica MPE é a media do erro em porcentagem do somatório de cada diferença, ou seja, aqui temos que retirar o percentual da diferença, somar e posteriormente dividir pela quantidade de elementos para obtermos a média. Portanto é feito a diferença entre o valor real e o previsto, divido pelo valor real, multiplicado por 100, faço o somatório de toda essa porcentagem e divido pelo quantidade de elementos, esta métrica é independente de escala (%).

MAPAE – Mean Absolute Percentage error.
A métrica MAPAE é bem parecido com a métrica anterior, porem a diferença do previsto x real é feito de formula absoluta, ou seja, você calcula de forma com valores positivos, portanto esta métrica é a diferença absoluta do percentual de erro. Esta métrica também é independente de escala.

Utilizando as métricas na pratica
Dado uma explicação sobre cada métrica, vamos calcular ambas manualmente no Python em cima de uma previsão de um modelo de machine learning de cotação do dólar. Atualmente existe boa parte das métricas de regressão em funções prontas no pacote do Sklearn, no entanto aqui vamos calcular manualmente apenas para fins didáticos.
Importando os pacotes necessários:

Utilizaremos os algorítimos RandomForest e o Decision Tree apenas para comparativo de resultado entre os dois modelos.
Realizando a importação dos dados:

Aqui temos uma coluna de SaldoMercado e saldoMercado_2 que são informações que influenciam na coluna Valor (nossa cotação dólar), vamos ver algumas informações estatísticas sobre esse dataset:

Como podemos observar o saldoMercado possui uma relação mais próxima da cotação do que o saldoMerado_2, também é possível observar que não temos valores ausentes (infinitos ou valores Nan) e que a coluna de saldoMercado_2 possui muitos valores não absolutos.

Vamos preparar nossos valores para o modelo de machine learning, aqui estamos definindo as variáveis preditoras e a variável que queremos prever e utilizamos o train_test_split para fazer uma divisão aleatória dos dados em 30% para teste e 70% para treino.


Por fim, realizamos a inicialização de ambos os algoritmos (RandomForest e DecisionTree) e já realizamos o fit dos dados e fazemos uma medição do score de ambos com os dados de teste. Obtemos um score de 83% para o TreeRegressor e 90% para o ForestRegressor, o que na teoria o ForestRegressor teve um melhor desempenho.

Diante do desempenho parcialmente observado do ForestRegressor, vamos criar um dataset com alguns dados necessários para aplicarmos as métricas desse artigo. Primeiramente eu realizo a predição dos meus dados de teste e atribuo a uma variável denominada previsto, na segunda linha faço a criação de um dicionario com atributos de previsto e Real de acordo com os meus dados da variável real e previsto, faço criação do meu dataframe com base no meu dicionario de dados, crio uma nova coluna chamada diff com a diferença do previsto e real, crio uma coluna chamada porcen com a porcentagem da diferença entre o previsto e real, realizo um arrendondamento em todas as colunas para 2 casas decimais e retiro possíveis valores nan.

Com meu dataset criado, vamos retirar alguns valores com base nesse dataset para que fique mais tranquilo calcularmos as métricas desse artigo. No código acima estou obtendo os totais de cada variável que preciso para os cálculos das métricas conforme comentários do código acima.

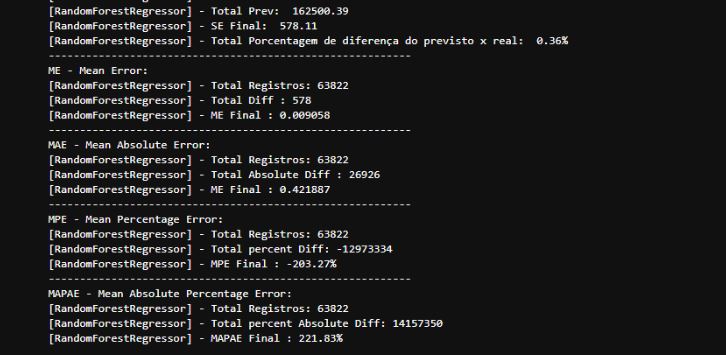
Com nossos totais obtidos, aplicamos as formulas para cada métrica desse artigo e disponibilizamos no console cada resultado e parâmetros da formula envolvida de acordo com cada métrica. Obtemos o resultado conforme abaixo:

Podemos observar que em relação ao total real da cotação dolar vs cotação que nosso modelo fez de previsão, tivemos uma diferença total de R$578,00 o que representa 0.36% de diferença entre o previsto x Real (não considerado valores absolutos).
Já na parte do erro médio (ME) tivemos um valor baixo também, média de R$0.009058, para média absoluta esse valor já aumenta um pouco, visto que temos valores negativos em nosso dataset. E por fim as duas ultimas métricas de percentuais médios.
Reforço que aqui realizamos o calculo manualmente para fins didáticos, no entanto o recomendado é utilizar as funções de métricas do pacote Sklearn devido a melhor performance e baixa chance de erro no calculo.
Disponibilizo este notebook no meu github: https://github.com/AirtonLira/artigo_metricasregressao
Thank you for reading!
Airton Lira Junior é um profissional de Tecnologia da Informação com mais de 10 anos de experiência, especializado em Big Data, Engenharia de Dados e Arquitetura de Soluções em nuvem. Atualmente atua como Engenheiro Sênior de Dados e Analytics na Dock, liderando melhorias em plataformas de dados, orquestração de pipelines com Databricks e otimização de workloads em AWS (EC2, EMR, SageMaker). Com passagens por empresas como iFood e Bemobi, destacou-se na concepção de soluções inovadoras, como modelos LLM para chatbots, integrações de IA em pipelines de áudio e projetos de conciliação financeira regulatória, utilizando tecnologias como Golang, Python, Apache Spark e Kubernetes. Possui certificações em AWS, Databricks e Power BI, além de formação em Análise de Sistemas pela FIA e especialização em Banco de Dados. Reconhecido por sua proatividade e expertise técnica, contribui ativamente para a comunidade tech como colunista no iMasters, compartilhando conhecimentos em automação, engenharia de prompts e arquitetura de dados escaláveis.


