

Neste artigo dou sequência no estudo de grafos usando a base de dados European Soccer Database, publicada por Hugo Mathien no KAGGLE.
Desta vez vou tratar da implementação do modelo de grafos definido no artigo anterior usando o SQL Server 2019.
Apresento também algumas consultas e análises sobre estes grafos.
Criando as Tabelas
Definido o modelo de grafos, é preciso criar as tabelas e carregar os dados. Para facilitar, apresento abaixo o diagrama do modelo.
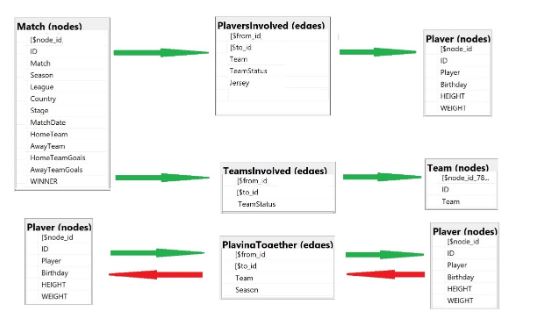
A criação das tabelas usando T-SQL não tem segredo: é preciso apenas informar que tipo de tabela está sendo criada, se é nó (“as node”) ou borda (“as edge”). No diagrama acima, os campos que são exibidos com um cifrão (“$”) na frente do nome são criados automaticamente pelo SQL Server. É necessário apenas definir os demais
campos.
Para facilitar a identificação das tabelas, criei os esquemas “nodes” e “edges”. O quadro a seguir mostra a sintaxe destas instruções.

Apesar da criação de tabelas ser bastante simples, a carga de dados requer mais cuidado, como descrevo a seguir.
Considerações sobre a Carga de Dados
Em primeiro lugar, é preciso respeitar a sequência: tabelas de nós são carregadas primeiro. Além dos campos que são definidos explicitamente, as tabelas de nós têm um campo que é criado e gerenciado automaticamente, cujo nome é “$node_id” (seguido de uma sequência de caracteres alfanuméricos que tornam este nome único). Estes campos contém um JSON que identifica o registro, como se vê a seguir.
![]()
O passo seguinte é a carga dos dados para tabelas de borda. Na prática, estas tabelas sempre vinculam dois nós, sejam eles quais forem. Do mesmo modo que as tabelas de nós, elas também têm campos que são criados e gerenciados automaticamente.
Os principais deles são os campos “$from_id” e “$to_id”. Neles são carregados os JSONs que se tem no campo “$node_id” das tabelas de nós vinculadas a esta borda. Perceba que, se a definição da borda tem um “DEPARA”,
significa que o relacionamento tem uma direção que é definida na carga dos dados! O quadro a seguir mostra um registro da tabela de borda “edges.PlayersInvolved”.
Escolhi que a coluna “$from_id” traria informação sobre a partida (match) e a coluna “$to_id” informaria o jogador (player) que participou dela.

Esta escolha precisa ser considerada em todas as consultas que forem feitas sobre estes dados. Se acidentalmente eu inverter a relação, buscando dados com base numa relação jogador/partida (ao invés de partida/jogador), nenhum registro será retornado.
Carregando Dados
Para que fique mais claro, apresento a seguir o modelo relacional dos dados, com as tabelas e campos que vamos carregar.
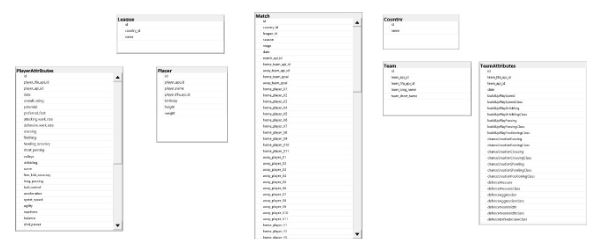
A carga de dados para tabelas de nós é elementar, porque geralmente temos uma tabela relacional para a mesma entidade que será representada como nó (neste caso, temos MATCH, TEAM e PLAYER).
No caso das bordas, vão existir necessariamente uma ou mais junções de tabelas. Isso porque será preciso trazer dados das tabelas relacionais (os atributos da borda) e dados de grafos, visto que os arquivos JSON das duas tabelas de nós envolvidas na relação serão carregados para as colunas “$from_id” e “$to_id” da tabela de borda.
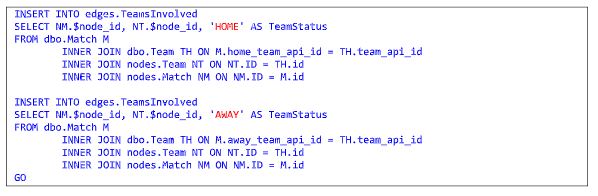
Para carga dos dados da borda “edges.TeamsInvolved”, por exemplo, foi necessário criar duas declarações separadas em virtude da modelagem da tabela relacional “dbo.Match”. A primeira declaração busca dados do time local (“home”) e a segunda do time visitante (“away”).
A carga da tabela de borda “edges.PlayersInvolved” é mais elaborada, já que a tabela relacional “dbo.Match” usa 22 colunas para identificar os jogadores que iniciaram a partida. Deste modo, foram criadas 22 declarações SQL para carregar estes dados.
No caso da terceira borda, “edges.PlayingTogether”, a situação é ainda mais complexa. Basicamente, preciso criar para cada jogador uma lista com o nome de todos os jogadores que jogaram no mesmo time que ele. Esta lista não pode ter repetições e não pode associar um jogador a ele mesmo. Existem diversas maneiras de se escrever estas declarações. Eu preferi criar um SQL dinâmico para simplificar a tarefa.
Analisando Dados com T-SQL
A principal diferença das declarações SQL que usam grafos é que elas não utilizam o operador JOIN entre as tabelas de nós e bordas. Na verdade, a conexão entre tabelas é feita através do operador MATCH.
O MATCH é incluído na cláusula WHERE junto com os demais predicados que sejam necessários. Ele define o relacionamento entre nós e bordas, sejam eles quantos forem necessários. A sequência dos nós pode ser colocada da maneira que preferir, desde que mude também os marcadores. Por exemplo (os parênteses, traços e símbolos fazem para da sintaxe):
![]()
Começo apresentando um exemplo simples, que por sinal seria resolvido com igual facilidade no modelo relacional. Desejo saber quantas partidas o Cristiano Ronaldo jogou pela liga espanhola na temporada “2009/2010”.

Agora quero saber quantos jogos Cristiano Ronaldo e Lionel Messi fizeram um contra o outro na Liga Espanhola durante todas as temporadas disponíveis na base (2008 a 2015). Esta é uma informação mais complicada de se extrair no modelo relacional.
Com grafos, basta especificar uma relação entre o jogador1 e uma partida e verificar se o jogador2 participou da mesma partida. Como sei que Messi e Cristiano nunca jogaram no mesmo time, não me preocupei em identificar os times deles como local ou visitante.

A próxima consulta é bastante difícil de se escrever num modelo relacional. Quero saber com quantos jogadores diferentes Cristiano e Messi jogaram durante este período de 2008 a 2015, não importa se jogaram juntos ou contra eles. No modelo de grafos, a complexidade é a mesma da consulta anterior.

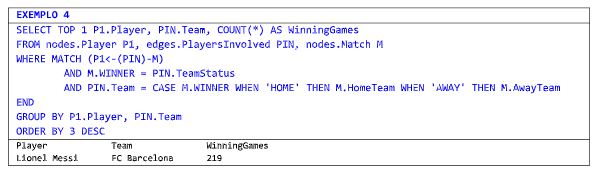
Agora quero identificar quem foi o jogador que mais ganhou jogos em campeonatos nacionais no período estudado e por quantos times diferentes. Este tipo de consulta poderia envolver 03 nós e 02 bordas caso meu modelo não incluísse dois atributos na borda que identifica os jogadores que participaram de uma partida: um informando o
nome do time em que o jogador estava e outro informando se este time era local ou visitante. Deste modo temos uma consulta mais simples e com performance melhor, graças ao alinhamento entre a modelagem da base e as expectativas de uso.
Mais um exemplo: quero saber se algum jogador já jogou junto com os goleiros Gianluigi Buffon (ex-seleção italiana) e Julio Cesar (ex-seleção brasileira) em ligas nacionais durante o período em estudo, quais foram os times, ligas e temporadas.
Neste caso, preciso identificar que esse(s) jogador(es) estavam naquelas partidas no mesmo time que um dos dois goleiros. Aqui é preciso distinguir 3 nós, P1 (Buffon), P2 (o jogador que estou procurando) e P3 (Julio). O time em que P2 jogou a partida precisa ser necessariamente igual ao time onde jogaram Buffon ou ao time do Julio
Cesar. A lógica aqui é um pouco mais complexa, pois preciso relacionar P1 e P2 a uma partida M1 e P3 e P2 a outra partida M2. Ainda assim, esta declaração é muito mais simples e rápida do que seria num modelo relacional (mesmo considerando que não criei índices customizados para estas tabelas).


Este caso era razoavelmente simples, porque de fato existiam 02 jogadores que jogaram diretamente com Buffon e também com Julio Cesar. Dizemos que estes grafos têm 02 graus de separação: Buffon “Jogador P2” Julio Cesar. Mas o que faríamos se não soubéssemos a “distância” entre estes dois jogadores?
Aqui entra um novo operador de grafos, implementado no SQL Server 2019 (ou superior): SHORTEST_PATH. Este operador informa o menor grau de separação existente entre 02 nós quaisquer. A sintaxe usada define uma chamada recursiva sobre os nós e a borda envolvidos, por essa razão que se usa a cláusula FOR PATH para identificar as tabelas recursivas.

Tenha em mente que o objetivo do operador SHORTEST_PATH é encontrar apenas um exemplo de caminho mais curto entre os nós “nó1” e “nó2”. Caso eu queira identificar todos os registros (ou “triplas”) que tenham este mesmo grau de separação, vou precisar escrever outra consulta diferente.
Meu objetivo no próximo exemplo é descobrir qual o caminho mais curto de jogadores que jogaram com Cristiano Ronaldo e Leonel Messi. O fato de ambos terem jogad o por poucos clubes (2 para Ronaldo e apenas para Messi), aliado à conhecida rixa existente entre Real Madrid e Barcelona, tornam muita baixa probabilidade de encontrar jogadores diretamente ligados a eles dois. Neste exemplo eu uso a borda JOGANDO JUNTOS (“edges.PlayingTogether”), que foi criada exatamente com a finalidade de avaliar as relações entre jogadores que jogaram juntos (pelo mesmo time). Com ela, a sintaxe da consulta será ainda mais simples. O fator principal a se considerar nesta consulta é que não se sabe quantos graus de separação existem entre Messi e Ronaldo, considerando apenas campeonatos nacionais europeus. Por esta razão, tenho que utilizar o operador SHORTEST_PATH.
Muitas vezes se usa as funções STRING_AGG, LAST_VALUE e/ou COUNT juntamente com o operador SHORT_PATH, visto que elas trazem informações relevantes sobre o caminho e os graus de separação dos grafos. É o que faço na consulta a seguir.
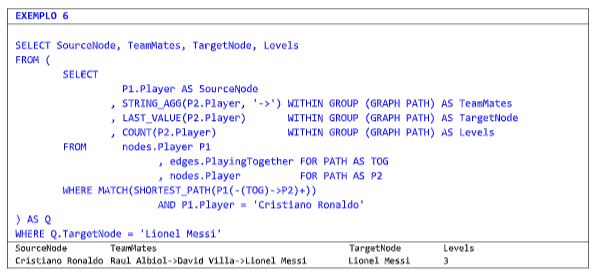
Note que esta consulta retorna um único exemplo de tripla que tenha o mínimo de níveis possíveis para ligar Ronaldo e Messi. Na verdade, a quantidade de triplas que atendem a este quesito é maior. Sabendo que preciso fazer a consulta com 03 graus de separação, fica fácil escrevê-la.

Comentários Finais
Como se vê, a implementação de tabelas de grafos usando T-SQL é simples e direta. Até mesmo as consultas usando os operadores MATCH e SHORTEST_PATH são relativamente simples de definir e implementar.
Deixo para os leitores mais céticos a tarefa de implementar consultas equivalentes numa base relacional, pois certamente serão consultas muito maiores e mais lentas.
É verdade que o modelo relacional da base original de Hugo Mathien não favorece estas consultas, mas o resultado final, em termos de complexidade e performance, não seria muito diferente mesmo que as tabelas relacionais fossem modeladas com um grau maior de normalização.
No terceiro e último artigo desta série, apresentarei a construção de um dashboard para análise dos grafos aqui criados.
Leituras Sugeridas
1. SQL Graph Architecture por MICROSOFT.
2. Graph processing with SQL Server and Azure SQL Database por
MICROSOFT.
3. European Soccer Database por Hugo Mathien @KAGGLE
4. Graph Databases for Beginners por Roberto Zicari (série de 5 artigos).
5. SHORTEST_PATH (Transact-SQL) por MICROSOFT.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?