

Introdução
Nos artigos anteriores, falei sobre conceitos e construção de modelos para uma aplicação do LUIS. Desta vez, a conversa é sobre como treinar este modelo antes de levá-lo para ambiente produção.
O que é o treinamento
Em primeiro lugar, é importante se acostumar com a ideia de que um modelo de aprendizado de máquina (ou ML) precisa necessariamente estar continuamente sendo treinado e melhorado. ML nunca é um projeto, com início, meio e fim. É um processo contínuo, que precisa ser repetido periódica e sistematicamente enquanto o modelo estiver em uso.
O treinamento do LUIS nada mais é do que vincular um conjunto de sentenças às intenções e entidades correspondentes. Usando algoritmos de linguagem natural, o LUIS analisa e extrapola este conjunto de sentenças, indo muito além de uma aplicação de perguntas e respostas (ou Q&A).
Por razões óbvias, não se deve cadastrar uma mesma sentença ou sentenças parecidas a mais de uma intenção. A escolha das sentenças é fator chave no treinamento do modelo. Este processo merece especial atenção na fase de planejamento e, por esta razão, é uma das etapas que consomem mais tempo na construção de uma nova aplicação.
Treinando o modelo
Para o primeiro treinamento do modelo, utilizei as 15 sentenças que apresentei no artigo anterior. São cinco sentenças associadas a cada uma das intenções que fazem parte do modelo: comprar, cancelar e pagar.
Já cadastrei todas as intenções e entidades que fazem parte desta aplicação demo. O próximo passo é associar sentenças a estas intenções e entidades. Para isso vou usar novamente a interface padrão do LUIS, abrindo a guia INTENTS e digitando as sentenças que serão associadas a cada intenção.
Observe na imagem a seguir que associei a sentença “Como faço para comprar pacote turístico?” à intenção COMPRAR e automaticamente foi marcada a entidade PRODUTO para o texto “pacote turístico”. Mas esta marcação automática falhou para duas outras sentenças: nas palavras “pacote” e “voos” nas frases um e dois, que deveriam ser reconhecidas como parte da entidade PRODUTOS.
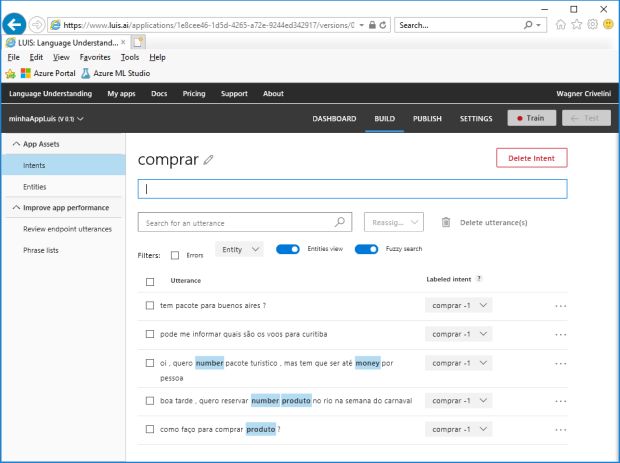
Isso mostra que seria interessante incluir mais palavras na lista que define esta entidade. Esta ação é executada clicando na guia ENTITIES e cadastrando as palavras “voos”, “vôo”, “voô”, “pacote”, “pct”, como mostra a imagem a seguir.
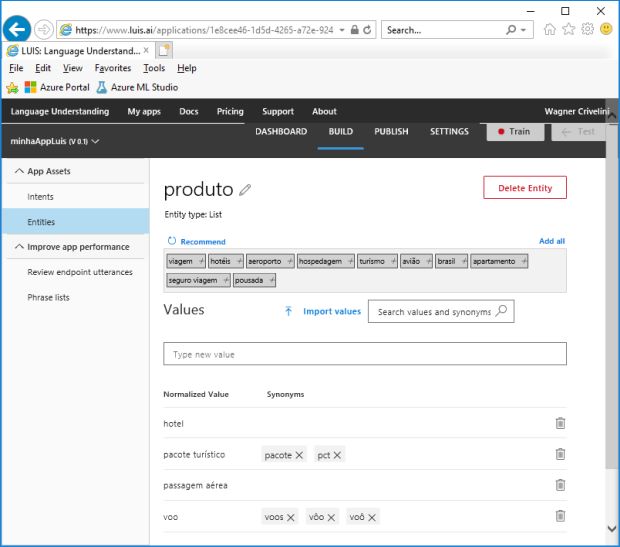
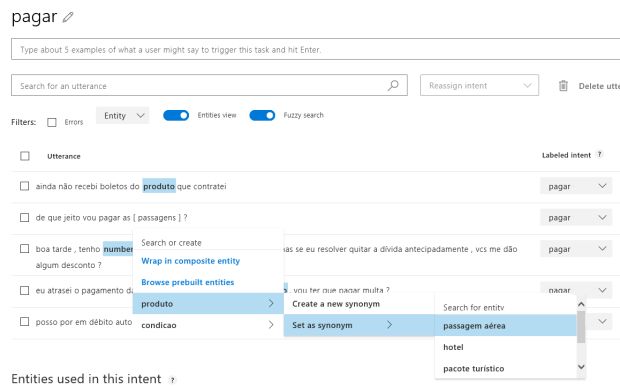
Outra forma de adicionar sinônimos, é mapeando a entidade diretamente no cadastramento da sentença.
Veja neste exemplo em que a frase “de que jeito vou pagar as passagens?” é associada à entidade PAGAR e a palavra “passagens” não é identificada como entidade PRODUTO. Após cadastrar a sentença, clico sobre a palavra que não foi marcada e a associo à entidade PRODUTO como sendo um novo sinônimo da expressão “passagem aérea” usando a opção SET AS SYNONYM.
Quando termino o processo de associação de sentenças, intenções e entidades, verifico as estatísticas do cadastramento na aba DASHBOARD, como mostra a imagem a seguir. Aqui vejo as quantidades de intenções, entidades e sentenças, além das datas em que ocorreram o último treinamento do modelo e a última publicação da aplicação.
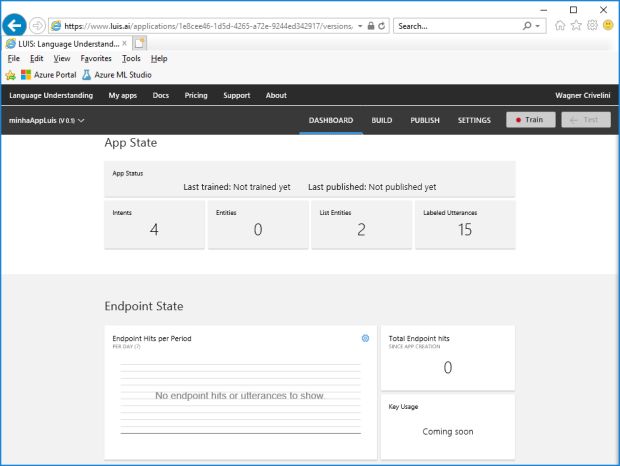
Clico o botão TRAIN para fazer o primeiro treinamento do modelo. A duração deste processo varia conforme a sofisticação do seu modelo. Nesta demo, que tem apenas 5 intenções, 15 sentenças e algumas entidades, o processamento leva apenas alguns segundos.
Testando/Retreinando o Modelo
Nenhum modelo deve ser movido para produção sem passar por uma longa bateria de testes. Por conta disso, o planejamento da aplicação precisa prever uma lista de sentenças usadas para treinamento e outro de igual tamanho para avaliação deste modelo.
Seguindo o teste da aplicação, clico no botão TEST e insiro as sentenças de teste para cada intenção estudada. Veja na imagem a seguir o resultado do teste de cinco frases que deveriam ter como resposta a intenção COMPRAR.
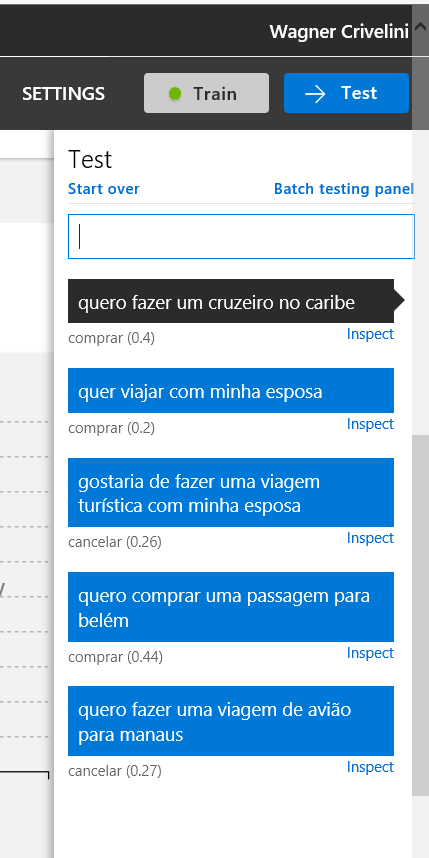
Em primeiro lugar, é preciso entender o número (ou score) que acompanha cada previsão. Este indicador representa uma nota para cada resposta e pode variar entre 0 a 1. Em teoria, quanto mais alta for a nota, maior é o nível de confiança desta resposta.
Vemos que em todos os cinco testes, esta nota foi baixa, chegando ao valor máximo de 0,44. Isso não é necessariamente um problema, mas é um sinal de alerta, pois pode ser um indício de que o modelo esteja mal treinado ou mal definido. Em outras palavras, pode ser que existam ambiguidades entre as intenções que se espera identificar, seja por causa da definição do modelo ou pelo treinamento que foi definido.
O segundo problema, este bem mais grave, é que o LUIS só acertou a resposta em três dos cinco testes. Isso mostra com toda certeza que o treinamento do modelo não está adequado.
De fato, dificilmente um modelo treinado com cinco sentenças para cada intenção poderá ser usado para aplicações práticas. A linguagem humana é muito complexa e normalmente você vai precisar de algumas dezenas de exemplos para treinar cada uma das intenções do seu modelo.
Considerando esta questão, eu decidi adicionar estas cinco sentenças de testes como parte do treinamento da intenção COMPRAR, que passa então de cinco para 10 sentenças treinadas. (Isso me obrigará a criar uma nova lista de sentenças para que eu possa repetir os testes).
Este processo de tentativa e erro é uma constante na história de uma aplicação do LUIS. Ao identificar erros, utilizo as frases erradas para melhorar o treinamento do modelo e obter melhores resultados no futuro.
Observe na imagem a seguir que, num modelo já treinado, quando eu abro a lista de sentenças associadas a uma intenção, o LUIS me informa o score de cada sentença. No caso das cinco primeiras frases (usadas no primeiro treinamento), os scores são bem altos, acima de 0,77. Em contrapartida, as cinco novas frases (que ainda não foram treinadas) apresentam scores muito baixos, abaixo de 0,40.
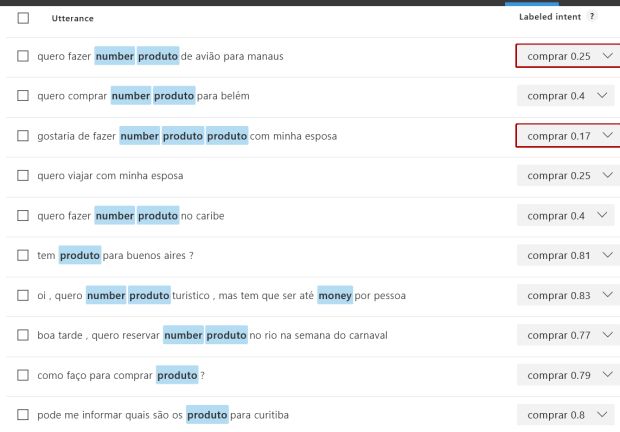
Apesar destes scores abaixo, estou seguro que estas frases são válidas para caracterizar minha intenção COMPRAR e por isso decido refazer o treinamento do modelo. A intenção obviamente é tornar o treinamento mais abrangente, reconhecendo um leque maior de frases relacionadas à intenção que desejo identificar.
A nova bateria de testes mostra que o objetivo foi alcançado. Mesmo usando cinco novas frases de teste bastante diferentes daquelas 10 que usadas para o treinamento, os resultados agora são muito melhores que na primeira bateria de testes: 100% de acerto, com todos scores acima de 0,48!
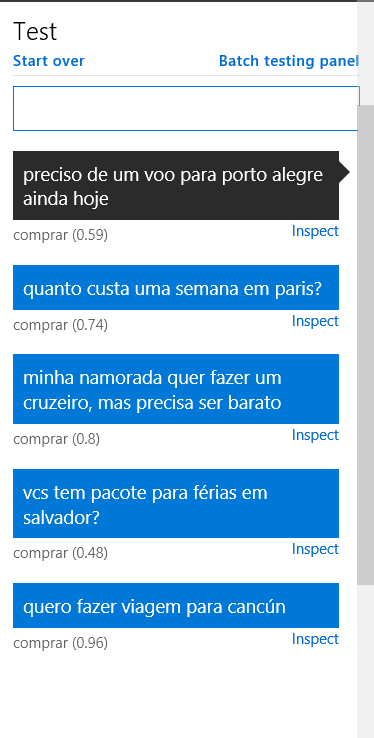
No mundo real, os testes precisam ser bem mais rigorosos do que os que eu apresentei aqui. Eu diria que seria necessário testar cada intenção com dezenas de sentenças antes de publicá-lo em produção. É claro que o rigor destes testes será tanto maior quanto maior for a importância da aplicação.
De qualquer modo, quando se entender que os resultados dos testes estão suficientemente bons, a aplicação pode ser finalmente publicada.
Mas isso é assunto para o próximo artigo desta série.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?