

Continuando a série “Desconstruindo a Web”, onde estamos desvendando, entendendo e tendo ideias sobre como as coisas funcionam por debaixo dos panos (under the hood). Caso não tenha visto os artigos anteriores:
- Desconstruindo a Web: pilha de execução do JavaScript
- Desconstruindo a Web: arquitetura de multi processos do Chromium
Neste artigo explicarei como é o processo de renderização do browser (navegador).
O que é um navegador?
Muitas vezes você deve ter ouvido falar em “navegador”, “navegadores”, “navegadores web”, “browser”, “browsers”, “web browsers”, etc.
Se alguém te falar “Ei, fulano, abre o navegador aí”, com certeza você deve abrir o Chrome, Firefox, Safari, Opera, Brave, IE, Edge, etc.
É certo que pelo menos um desses na lista você vai abrir. Mas, afinal, um navegador é o Chrome? Não, o Chrome é um navegador, mas a definição de um navegador não refere-se ao Google Chrome.
Sabendo disso, então, o que é um navegador? Um navegador é um software que carrega arquivos de um servidor remoto ou do disco local e o disponibiliza para visualização (permitindo também que exista uma interação com o mesmo).
- Do que um navegador é feito?
Dentro de um navegador (sabemos que é um software), podem haver outros pequenos softwares, onde cada um possui sua responsabilidade. Um desses “pequenos” softwares é o motor do navegador (browser engine).
Browser engine
Dentro de cada navegador (Chrome, Firefox, Opera, etc.) existe uma implementação do motor (engine). Ele é o responsável por descobrir quais são e como renderizar as informações dos arquivos que ele recebeu para que você visualize ou interaja com os mesmos.
Exemplos de motores:
- Gecko
- Blink
- Webkit
Enviando e recebendo informações
A Internet envia e recebe informações através de pacotes em bytes. Nós escrevemos códigos HTML, CSS e JS e abrimos no navegador, que por sua vez, lê os bytes de HTML do nosso disco ou através da rede.
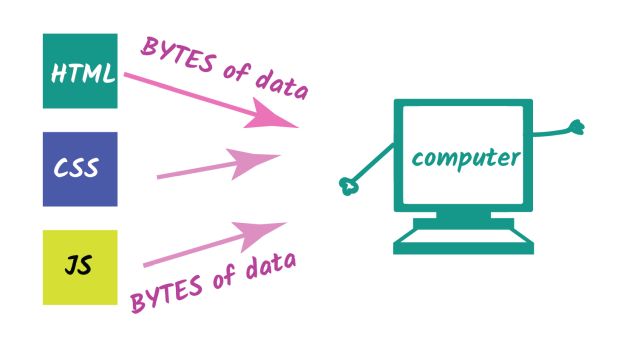
O navegador lê dados em bytes e não os caracteres e dados que nós escrevemos. A questão, é que ele não sabe o que fazer com esses bytes, eles precisam ser convertidos para algo que ele entenda.
Esse é o segundo passo no processo de renderização (o primeiro é ler e receber os bytes).
De bytes para o DOM
Vimos que o navegador vai ler e receber informações em bytes, porém, ele não sabe o que fazer com eles. O navegador sabe trabalhar com DOM (Document Object Model), mas o que é DOM?
Antes de vermos o que é DOM, vamos entender como ele é criado.
Primeiro, as informações em bytes são convertidas para caracteres:
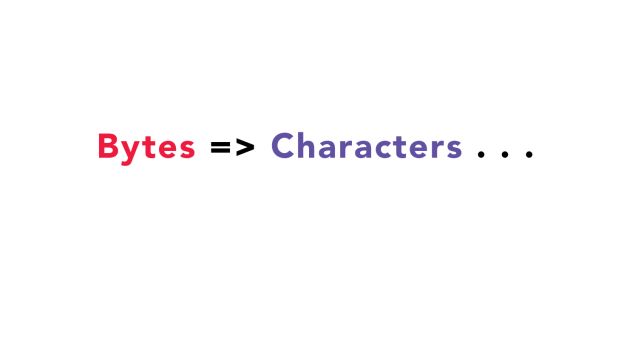
Esses caracteres para os quais a conversão é feita, são os caracteres que nós escrevemos. Essa conversão é feita baseada na codificação (encoding) do nosso arquivo .html. Basicamente, nessa etapa o browser (navegador) recebe bytes e os converte para o código que nós escrevemos.
Mas os caracteres não são o resultado final – ainda existe um processo de análise onde os caracteres passarão para tokens (esse será o terceiro passo).
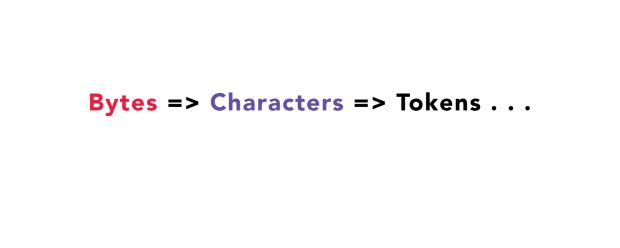
O que são esses “tokens”?
Sem esse processo de tokenização, teríamos um monte de caracteres sem significado. Basicamente teríamos nosso código HTML sendo exibido pela janela do navegador, o que não reproduz um site real.
Quando salvamos um arquivo com a extensão .html, estamos dizendo para o motor do navegador interpretá-lo como um documento HTML. A maneira como o navegador vai interpretar esse arquivo é começando a realizar o parseamento dele.
Nesse processo de parseamento e particularmente no de tokerização, todo inicio e fim das tags HTML são contabilizadas. O parseador entende cada string entre colchete angulares. Por exemplo: html, p, a, button, etc, e entende o conjunto de regras que aplicam-se para cada uma delas.
Por exemplo: um token que representa uma tag a terá propriedades diferentes de um token que representa uma tag p, e assim por diante.
Conceitualmente, podemos entender um token como um tipo de estrutura de dados que contém informações sobre determinadas tags HTML.
Um arquivo .html é quebrado em pequenas unidades de parseamento chamadas de tokens.
Essa é a maneira como o browser (navegador) começa a entender os códigos que nós escrevemos.

Mas os tokens também não são o resultado e nem a etapa final – ainda existe um quarto passo.
Criação de nós
Após finalizar a tokenização, os tokens são convertidos para nós (nodes). Vamos imaginar os nós como objetos distintos com propriedades específicas. Vamos pensar que nós são entidades separadas dentro da nossa árvore de objetos, e como você deve imaginar, os nós ainda não são o resultado final – temos mais um e último quinto passo.
DOM
Após a criação dos nós, eles são linkados em uma estrutura de árvore conhecida como DOM (Document Object Model). O DOM estabelece os relacionamentos de pais e filhos, irmãos adjacentes e outros graus parentescos.
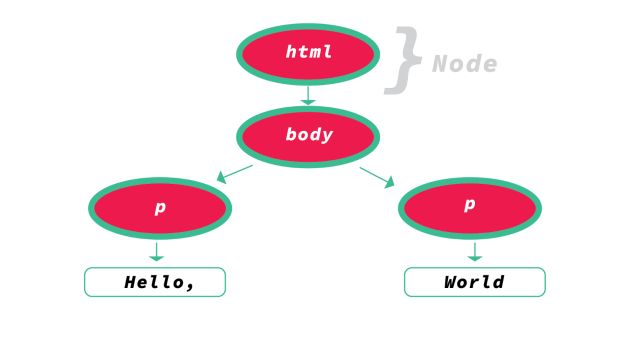
O browser (navegador) vai através da transformação de informações de bytes crus até a criação e renderização do DOM antes que qualquer coisa possa acontecer.
Dependendo do tamanho de seus arquivos .html, o processo da construção do DOM pode levar algum tempo.
Assim, temos os passos para a renderização de uma página finalizados, sendo eles:

Conclusão
Nesse artigo expliquei um pouco sobre como funciona o processo de renderização dos navegadores (browsers). Passamos por todos os cinco passos e entendemos quando e porque cada um deles acontecem.
E aí, você já conhecia o processo de renderização das páginas pelos navegadores? Não deixe de comentar!
Caso tenha gostado deste artigo e queira receber novidades por e-mail, fique à vontade para assinar a nossa newsletter no final da página!
Abraços, até a próxima!
Referência

De 0 a 10, o quanto você recomendaria este artigo para um amigo?