

Oferecer um canal de comunicação rápido e eficiente no aplicativo para pessoas que dirigem com Uber é fundamental para o nosso negócio. Se não conseguirmos efetivamente entregar mensagens no aplicativo, ele pode impedir que os motoristas recebam informações importantes. Em 2015, a equipe de Experiência do Motorista da Uber apresentou um novo aplicativo do motorista para melhorar a experiência do usuário, incluindo a implantação de um ecossistema de entrega de conteúdo novo e mais eficaz.
Neste artigo, discutimos os desafios técnicos que encontramos – e soluções que desenvolvemos – ao criar um novo canal de conteúdo e o ecossistema de backend correspondente para o aplicativo.
Entregar ou não entregar?
Ao projetar um novo aplicativo, o desafio mais imediato é determinar a melhor maneira de estruturar o conteúdo para os usuários. Em geral, Uber reconhece três modelos de interação usados para agrupar conteúdo de usuário:
- Urgente: Conteúdo que requer uma ação imediata do usuário, como notificações sobre a expiração de documento.
- Não urgente: Conteúdo que pode ser reconhecido ou descartado. Este modelo funciona de forma semelhante a uma caixa de entrada de e-mails, no sentido de que as mensagens recebidas são acessíveis por algum período de tempo e podem esperar para que os usuários as leiam e processem de acordo com sua conveniência. A maioria dessas notificações são confirmações de pagamentos, avaliações recentes e promoções de recursos.
- Permanente: Material educativo ou dados estatísticos atuais sobre o perfil de um usuário, como classificação total e ganhos semanais. Os usuários podem visualizar esse conteúdo a qualquer momento em uma seção dedicada da interface de usuário (IU) do aplicativo.
Combinar esses três paradigmas em uma única solução segue objetivos ortogonais. Em nossa busca por uma solução, percebemos que ter um conceito de entrega de conteúdo como o conhecemos das redes sociais, com algumas modificações, nos permitiria atingir nosso objetivo. Na próxima seção, veremos como cada um desses modelos de interação é refletido no comportamento do novo feed.
Categorias de Modelos de Interação
Conteúdo urgente
Ao colocar um feed de mensagens na parte inferior da tela principal e deixar essas mensagens aparecerem sobrepostas na tela quando o usuário desliza para cima, todos os updates no novo aplicativo de motorista assumem a forma de pop-ups. Embora isso funcione bem com confirmações, promoções e solicitações de ação (RFA – Request For Action) têm um ciclo de vida mais complexo.
Uma confirmação desaparece uma vez que o conteúdo é reconhecido, porque seu único propósito é informar o usuário sobre algo que eles podem querer agir sobre. Uma promoção permanece na tela por mais tempo do que uma confirmação, permitindo ao usuário mais tempo para digerir seu conteúdo, apenas desaparecendo do feed se for reconhecido pelo usuário com um toque; pode até haver uma conexão com o conteúdo permanente, que está disponível para o usuário em uma seção separada e estática do aplicativo. Os RFAs seguem um padrão ainda mais complexo ao aparecerem, desaparecerem e ressurgirem até que os usuários concluam uma ação.
Conteúdo Não Urgente
Se o conteúdo exibido não for urgente, ele é colocado no feed, em ordem de relevância para o usuário, do mais novo para o mais antigo. Esta estratégia é um bom sinal para uma variedade de atualizações, como informações sobre eventos futuros em sua cidade ou feedback de clientes anteriores.
Conteúdo permanente
Para o novo aplicativo, o conteúdo permanente é basicamente um conjunto estático de links que leva a outros conteúdos. Ao testar essa nova interface, descobrimos que poderíamos modelar esse conteúdo como um feed separado, classificado estaticamente, apresentado em abas separadas do aplicativo. Por exemplo, as informações relacionadas aos ganhos, como incentivos, referências e estatísticas financeiras, podem ser apresentadas como uma lista estática de itens em uma aba separada servida por um sistema de feed.
Implicações do modelo de interação
Ao projetar o novo feed, nós avaliamos quais requisitos esses modelos de interação colocam em todo o sistema e suas implicações arquitetônicas resultantes. Ao equipar o aplicativo com vários tipos de feeds, fomos capazes de construir cada um deles separadamente. Isso é gerenciado dando a cada tipo de feed sua própria estratégia de classificação configurável e cada pedaço de conteúdo dentro de um determinado feed sua própria política de ciclo de vida.
Usando essa abordagem, as abas do aplicativo que oferecem conteúdo estático são atendidas por um feed único e estaticamente classificado. Nesse cenário, a classificação raramente varia de acordo com o tempo, mas pode ser afetada por condições como a região atual do motorista ou o nível de experiência. Cada item desses feeds estáticos tem uma duração quase permanente, pelo menos até que haja uma solicitação para alterá-lo ou removê-lo.
Por outro lado, os feeds dinâmicos têm uma estratégia de classificação configurável e complexa capaz de enviar itens para o topo do feed com base na urgência, relevância e outros critérios.
Agora, depois de analisar os requisitos do produto do lado do motorista do feed, vamos dar uma olhada no maior panorama de requisitos de comunicação para o sistema de entrega de conteúdo.
O ecossistema de entrega de conteúdo mais amplo
Um sistema de entrega de conteúdo como o da Uber não existe isoladamente e é fortemente influenciado pela criação de conteúdo e mecanismos de ingestão. A fim de proporcionar uma experiência de usuário suave e funcional, um ecossistema inteiro precisa ser construído a partir do zero. Nesta seção, discutimos como abordamos esse processo na Uber.
À primeira vista, este feed pode assemelhar-se àquele de uma rede social, mas há uma diferença chave: o conteúdo é proveniente exclusivamente da Uber e não de motoristas. Ao invés de enviar seu conteúdo para o centro de dados para ser indexado, classificado de forma independente e esquecido, os autores controlam ativamente o direcionamento, a personalização e gerenciamento de seu conteúdo. Nesse sentido, o sistema de entrega de conteúdo da Uber tem mais semelhanças com uma plataforma de entrega de conteúdo publicitário do que com uma rede social, porque as interações são unilaterais e podem exigir ou incitar uma resposta do usuário. Esta diferença, por sua vez, afeta a forma como o conteúdo deve ser ingerido e selecionado pelo ecossistema de alimentação.
Direcionamento
Atualmente, utilizamos três estratégias principais de direcionamento no aplicativo de motorista da Uber: direcionamento baseado em evento, correspondência em tempo real e mensagens em massa. Para mensagens em massa, inventamos todo um novo conjunto de ferramentas e serviços adaptados às necessidades da Uber. Cada um dos serviços de backend neste sistema mais amplo trata especificamente do direcionamento; no entanto, o conteúdo é oferecido aos nossos usuários através de uma experiência de frontend coesa.
O conteúdo direcionado é produzido de duas maneiras: a primeira e mais simples é usar ferramentas internas de interface do usuário para definir manualmente um conjunto de regras ou campanhas, e a segunda e mais complexa abordagem é gerar conteúdo com um serviço separado. Os serviços que fornecem conteúdo geralmente monitoram métricas ou eventos dentro do nosso sistema e usam alguma lógica de negócios para executar etapas de avaliação adicionais. Em ambos os casos, a infraestrutura mostrada no diagrama a seguir é utilizada:
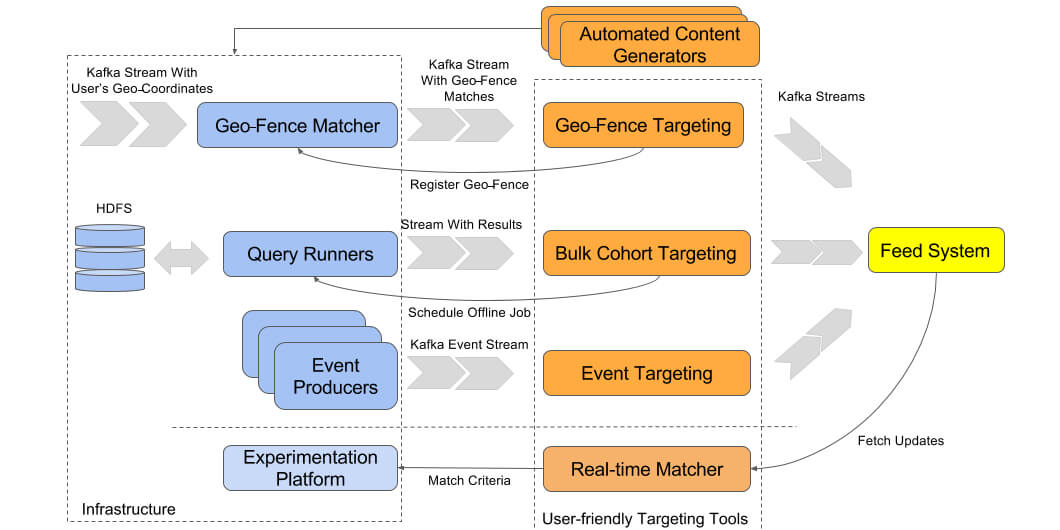
Direcionamento baseado em eventos
Sempre que um motorista produz um evento no aplicativo mobile, como atravessar uma geofence (área geográfica pré-determinada) ou terminar uma viagem, talvez seja necessário enviar uma mensagem em tempo real ao feed. Isso entra em jogo ao lidar com os casos de uso de confirmação e notificação que já descrevemos. Para enviar esta notificação, criamos um filtro de direcionamento que aguarda a ocorrência de um evento específico; se acionado, este evento faz com que uma mensagem seja enviada para o feed do motorista. Um evento pode ser acionado por qualquer ação, como a solicitação de viagem, tocando um botão no aplicativo, conclusão de um cálculo de pagamento em segundo plano ou até mesmo um motorista que cruza uma geofence específica.
Na Uber, usamos uma plataforma rica em dados para lidar com eventos. Quase tudo o que acontece no dispositivo móvel, incluindo alterações geocoordenadas e interações do usuário, é relatado ao serviço de gateway e enviado ao nosso fluxo Kafka pronto para ser consumido por serviços downstream. A infraestrutura de direcionamento utiliza principalmente mecanismos de regras baseados em Samza, configuráveis por ferramentas de IU, que permitem aos criadores de conteúdo filtrarem eventos por determinadas regras, como a penetração de localidade, para produzir uma mensagem e entregá-la aos usuários.
Mensagens em massa
As mensagens em massa (bulk messages) são uma boa correspondência para campanhas direcionadas, como promoções e anúncios específicos de coorte. Neste modelo, as mensagens podem ser enviadas em massa executando as tarefas offline em Hive, Hadoop ou Spark para selecionar coortes e, em seguida, enviar mensagens personalizadas para feeds do usuário.
Na Uber, quase todos os eventos produzidos por dispositivos móveis são extraídos, transformados e carregados em um Sistema de Arquivos Distribuídos Hadoop (Hadoop Distributed File System – HDFS) e agregados. Isso permite que os dados sejam acessados offline através de consultas Hive ou trabalhos Spark para seleção de coorte mais complexa. Usando esta tecnologia, os criadores de conteúdo podem enviar mensagens para usuários com base em critérios que exigem a agregação de eventos, como a ultrapassagem de um limiar de atividade em declínio, um aumento de reclamações de motoristas ou simplesmente o anúncio de uma nova iniciativa para um grupo particular de motoristas baseado em sua história de condução. Na maioria dos casos, um mecanismo baseado em Hive é usado para consultar tabelas HDFS e exportar os resultados para um sistema de enfileiramento como Cherami ou Kafka. Após os resultados serem enfileirados, eles podem ser consumidos pelo sistema de alimentação e enviados para dispositivos móveis.
Correspondência em tempo real
Em alguns casos de direcionamento, certos critérios devem ser avaliados quando o motorista ativa o aplicativo e começa a aceitar corridas. Estes são casos em que o conteúdo dependerá de parâmetros dinâmicos, como localização e a versão do aplicativo instalada. Situações como estas são bastante raras, uma vez que a maioria das informações de um usuário pode ser enviada proativamente pelo aplicativo e processada offline para consumo posterior por mecanismos de direcionamento em massa. No entanto, há exceções nas quais uma alteração em um usuário ou estado do aplicativo precisa ser reconhecida por uma mensagem em tempo real, por exemplo, no caso de novas implantações de recursos.
Hoje em dia, muitas empresas de software hospedam algum tipo de plataforma de experimentação (XP) que lhes permite implantar novos recursos para uma porcentagem configurável de usuários que são selecionados por determinados critérios, como país, cidade, localidade e versão do dispositivo. A disponibilidade de tal recurso é anunciada ao usuário na forma de uma mensagem enviada através do sistema de alimentação. Nesses casos, é fundamental que a coorte enviada por mensagem sobre esse novo recurso seja exatamente a mesma que recebe o recurso. Da mesma forma, o mesmo XP deve ser capaz de produzir uma resposta a ambas as perguntas: “deve o recurso ser habilitado para o usuário?” e “deve uma mensagem sobre esse novo recurso ser mostrada para o usuário?” Na Uber, nós construímos nosso próprio correspondente de tempo real para resolver este caso de uso.
Decisões sobre Tecnologia de Sistemas de Alimentação
Estratégia fan-out
Havia uma série de decisões que precisávamos fazer quando se tratava de determinar a composição tecnológica mais eficaz para o nosso feed.
Existem duas maneiras de armazenar conteúdo no ecossistema padrão de entrega de conteúdo: enviado e pré-avaliado para cada usuário individual (fan-out-on-write) ou indexado, filtrado e classificado a pedido (fan-out-on-read). As opções de direcionamento descritas acima têm uma implicação direta no estilo com o qual o sistema de feed controla o conteúdo. O envio de conteúdo direcionado personalizado tende a forçar o projeto do sistema de alimentação a seguir um padrão de fan-out-on-write. Isto é assim principalmente por duas razões:
- Entrega em tempo real: Para mensagens urgentes, como quando um motorista tem que ser avisado sobre as condições de viagem, uma mensagem é enviada para o seu feed no mesmo momento em que é disparada (por exemplo, quando um usuário atinge uma geofence ou ocorre um evento ).
- Eficiência: Mesmo nos casos em que o conteúdo não precisa ser entregue em tempo real, fan-out-on-read resulta em polling para os mecanismos de direcionamento, uma vez que contêm a lógica de direcionamento. Quando os tamanhos de coorte são pequenos, a maioria das pesquisas resultará em respostas vazias, o que leva a uma utilização ineficiente do hardware.
Devido à existência de direcionamento por correspondência em tempo real, uma estratégia fan-out-on-read tem de ser suportada também. Como resultado, o sistema de alimentação da Uber suporta ambas as estratégias ao mesmo tempo, descritas em detalhes adicionais em nossa próxima seção.
Envio em tempo real versus polling periódico
Como resultado das estratégias fan-out combinadas da Uber, nosso feed opera tanto em um modo store-and-notify quanto no store-and-push, dependendo da configuração do feed, além de alcançar mecanismos específicos e serviços configurados para comportamento fan-out-on-read, conforme demonstrado abaixo:
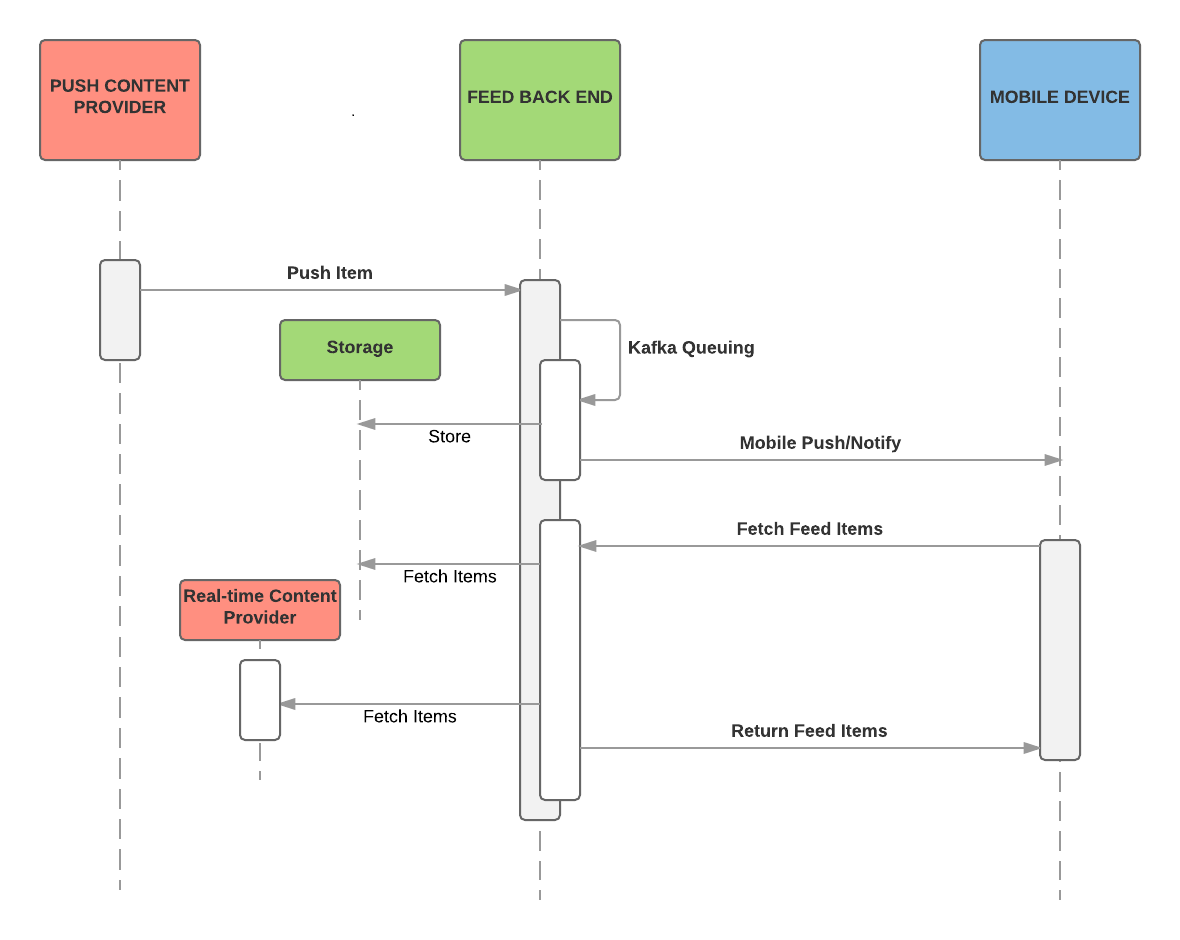
Fluxo de alimentação
O backend do feed determina o fluxo de entrega de conteúdo. Como os dispositivos móveis não têm como pressuposto manter o estado, o serviço backend tem de ser capaz de entregar todo o conteúdo do feed a qualquer momento; conteúdo do feed é chamado pelo aplicativo móvel sempre que um dispositivo precisa obter o estado mais recente.
Uma vez que um novo conteúdo é enviado por um serviço interno, o backend do feed o armazena em um banco de dados por um período de tempo especificado e notifica os dispositivos móveis através de um mecanismo de envio. Acionado pelo envio, um dispositivo solicita uma alimentação nova a partir do backend. Nesse momento, o backend do feed recupera itens armazenados do banco de dados e chama seus serviços fan-out-on-read para obter itens adicionais em tempo real. Após a agregação e classificação, os itens da etapa são retornados para o dispositivo móvel.
Armazenamento de conteúdo
No nosso novo ecossistema de entrega de conteúdo, o backend do feed armazena conteúdo de feed ativo em um banco de dados. Selecionamos esse modelo para aumentar o desempenho de pesquisas de feed subsequentes e remover o conteúdo quando ele não deve mais aparecer. Da mesma forma, escolhemos Cassandra para as nossas necessidades de armazenamento em relação a outras tecnologias, devido à sua capacidade de lidar com a replicação de centro de dados e modelagem de dados.
Replicação do Centro de Dados
Solicitações de aplicativos móveis de motoristas e motoristas-parceiros são encaminhadas para centros de dados em todo o mundo com base na proximidade geográfica. No entanto, alguns de nossos serviços internos de produção de conteúdo estão ativos somente em um desses centros de dados (por exemplo, onde um trabalho Hive está sendo executado) e não têm acesso às localizações dos motoristas. Quando um produtor envia conteúdo para o serviço de feed, o conteúdo deve ser disponibilizado aos usuários hospedados em centros de dados para facilitar sua possível implantação, independentemente da localização do motorista. Para garantir que os usuários possam acessar o conteúdo do feed em todos os momentos – mesmo durante falha de rede – o tráfego do usuário pode ser encaminhado para um centro de dados alternativo. As capacidades de replicação do centro de dados de Cassandra fizeram uma escolha fácil para nós ao projetar nosso novo ecossistema de entrega de conteúdo.
Modelagem de Dados
O conteúdo de feed para um único motorista geralmente vem de vários serviços internos e esses serviços podem enviar conteúdo de qualquer forma e a qualquer momento. Para evitar race condition, precisamos de granularidade no nível de conteúdo ao escrever conteúdo em nosso armazenamento de dados de backend. O serviço de feed deve ter acesso a todo o conteúdo salvo ao servir um feed para um cliente móvel; para conseguir isso, precisamos de granularidade no nível de usuário para a leitura de dados.
O modelo de dados orientado por fileiras particionado de Cassandra atende perfeitamente a esses requisitos. Escolhendo ID de usuário como a chave de partição nos permite buscar todos os itens disponíveis para um usuário em uma única solicitação. Esse tipo de consulta tem uma complexidade de constante de tempo em relação ao número de tipos de item. Ao escolher ID do usuário, tipo de item e ID do item como uma chave primária composta, cada item é essencialmente uma linha no armazenamento de dados. Quando vários provedores de conteúdo em toda a organização enviam conteúdo para um usuário simultaneamente, Cassandra escreve em diferentes linhas para evitar quaisquer condições de corrida.
Criação de Conteúdo e Projeto
Um sistema de feed típico em uma rede social processa o conteúdo de forma diferente na camada de apresentação para fins de personalização. A fim de reduzir a quantidade de presentational code, as empresas geralmente tentam padronizar sua apresentação e usar apenas alguns projetos diferentes. Uma camada de apresentação (por exemplo, frontend ou código móvel), então, converte cada tipo de atualização em um dos projetos de IU.
Na Uber, aprendemos isso no trabalho. Com nosso crescente número de tipos de conteúdo de feed em todos os nossos produtos, estender e manter uma camada de apresentação para cada nova categoria se tornou um fardo significativo para todo o sistema de alimentação por duas razões:
- Código que lida com o desenvolvimento de novos tipos de conteúdo tem de ser adicionado e lançado para dispositivos móveis para cada novo tipo de conteúdo enviado devido a diferenças sutis no projeto, como ocultar algum elemento da interface do usuário ou adicionar um botão extra. Consequentemente, a padronização e consolidação de projetos não foi uma realidade para nós dado o hipercrescimento de nossos serviços.
- Mesmo que o mesmo código do projeto possa ser reutilizado para um novo tipo de conteúdo, ele ainda requer a criação de um novo presentational code para inserir novos dados nesse projeto. O produto acabado mal pode ser reutilizado e, como resultado, novos tipos de conteúdo não podem ser adicionados em tempo real. Esta estratégia também não era viável para o nosso caso de uso.
Além de criar uma série de projetos de conteúdo que podem ser conectados e continuar dependendo do tipo de conteúdo, lançamos uma série de mecanismos de direcionamento com a capacidade de autorar mensagens em um projeto específico. Nós brincamos com a ideia de ter cada mecanismo oferecendo o seu próprio conjunto fixo de projetos, mas não surpreendentemente, alguns projetos não poderiam ser reutilizados através de mecanismos de direcionamento ou tiveram de ser duplicados, o que demorou muito tempo.
Apresentando: ecossistema de entrega de conteúdo da Uber
Ao longo do tempo, percebemos que precisávamos construir uma nova ferramenta para melhor criar e implementar projetos de conteúdo personalizados de forma que o componente de apresentação do nosso sistema de feed pudesse usar uma única abordagem padrão para a execução de conteúdo.
No lado móvel deste modelo, projetos semelhantes podem ser divididos em componentes reutilizáveis que um mecanismo de execução pode, então, dinamicamente, combinar em runtime, permitindo que o criador de conteúdo selecione uma configuração particular de projeto visual durante o processo de criação de conteúdo.
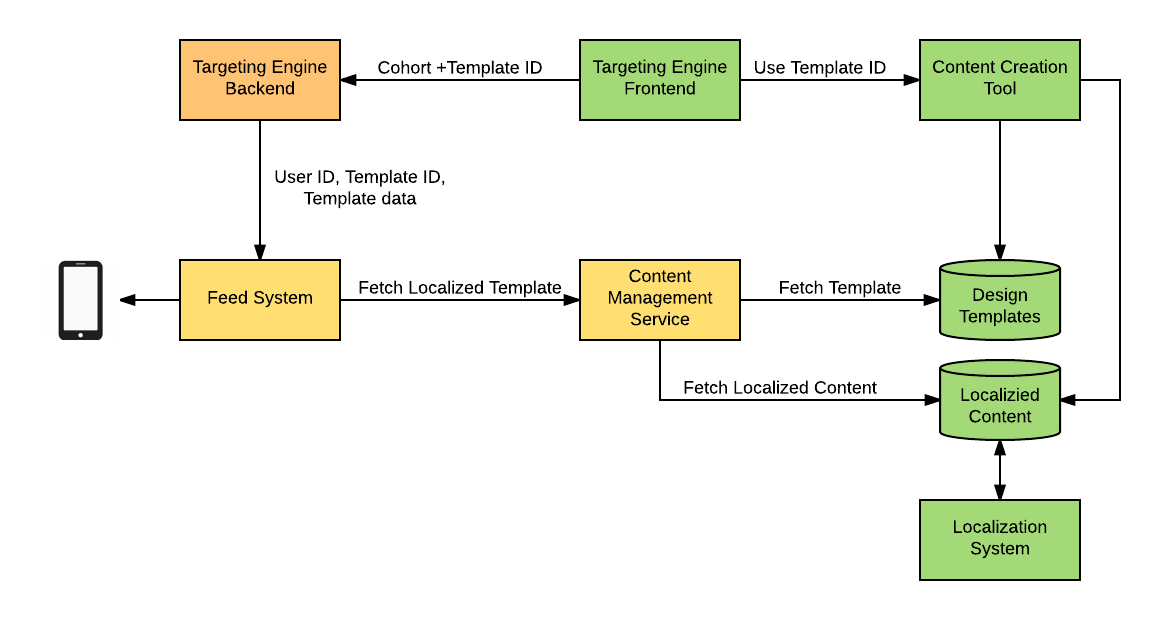
O conteúdo do feed é criado pela ferramenta de interface do usuário, que permite aos criadores de conteúdo reunir um projeto específico para a mensagem de blocos reutilizáveis, como título, imagem, lista ou conjunto de botões, entre outros itens, bem como preencher o idioma real do conteúdo em cada bloco. Esse processo nos permite injetar marcadores de posição de modelo para dados provenientes de mecanismos de direcionamento, perfis de usuário e outras fontes.
A definição de nosso modelo de projeto final é, então, serializada em um formato JSON e executada por um mecanismo no dispositivo móvel. Os modelos de projeto produzidos por esta ferramenta são armazenados em um banco de dados separado e podem ser referenciados por mecanismos de direcionamento. Usando esse sistema, separamos a lógica fornecida pelos mecanismos de direcionamento e outros serviços de uma lógica de apresentação, agora oferecida por uma única ferramenta de projeto de conteúdo.
Ao permitir que os mesmos modelos de projeto sejam usados com vários mecanismos de direcionamento, permitimos recursos de personalização de conteúdo ricos e consistentes em toda a plataforma. Além disso, essa decisão nos permitiu eliminar a necessidade de modificações de códigos móveis para a maioria dos novos projetos e ajudou a conduzir a padronização do aspecto do aplicativo, definindo um conjunto fixo de blocos.
Novos serviços que produzem atualizações para usuários não precisam mais lidar com aspectos de apresentação, como traduções de conteúdo de feed em outros idiomas, e podem se concentrar em direcionar as corretas coortes de motoristas para conteúdo específico. Com esta abordagem de projeto baseada em blocos, a ferramenta de criação de conteúdo móvel da Uber também torna possível criar novos conteúdos e traduzi-los em minutos, processo que anteriormente levava de várias horas até uma questão de dias.
Este novo ecossistema de entrega de conteúdo móvel é fácil de usar e integra-se perfeitamente com muitos dos serviços e ferramentas de direcionamento amplamente utilizados da Uber, permitindo tanto que engenheiros quanto suporte ao cliente criem e forneçam informações relevantes aos motoristas e, por extensão, aos clientes deles.
***
Este artigo é do Uber Engineering. Ele foi escrito por Alex Forsythe, Denis Haenikel e Minjie Zha. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/mobile-content-delivery/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?