

Os dados não servem para nada se não conseguirmos encontrá-los. Pesquisar registros individuais nos mais de 100 petabytes de dados acumulados na Uber nos permite realizar atualizações e coletar insights úteis para ajudar a melhorar nossos serviços, como a entrega de ETAs mais precisos para os passageiros e a exibição de opções de comida favoritas dos usuários.
Consultar dados nessa escala e entregar resultados em tempo hábil não é uma tarefa simples, mas é essencial para que as equipes da Uber possam obter os insights de que precisam para oferecer experiências perfeitas e mágicas aos nossos clientes.
Para dar suporte a esses insights, criamos a plataforma Big Data da Uber ao separar as camadas de armazenamento e consulta para que cada uma pudesse ser dimensionada de forma independente.
Armazenamos conjuntos de dados analíticos no HDFS, os registramos como tabelas externas e os servimos usando mecanismos de consulta, como Apache Hive, Presto e Apache Spark.
Essa plataforma de Big Data permite análises confiáveis e escaláveis para as equipes que supervisionam a precisão e a melhoria contínua de nossos serviços.
Durante a vida útil de uma viagem na Uber, novas informações são atualizadas para um dado de viagem durante eventos como a criação de viagens, atualização da duração da viagem e atualizações de revisão do passageiro.
O suporte a uma atualização exige que você procure a localização dos dados antes de modificá-los e mantê-los.
À medida que a escala dessas pesquisas aumentou para milhões de operações por segundo, descobrimos que os repositórios de valor-chave de código aberto não conseguiam atender aos nossos requisitos de escalabilidade prontos para o uso – eles comprometem o rendimento ou a correção.
Para encontrar de forma confiável e consistente a localização dos dados, desenvolvemos um componente chamado Índice Global.
Esse componente executa a contabilidade e consulta da localização dos dados nas tabelas do Hadoop.
Ele fornece alto rendimento, consistência forte e escalabilidade horizontal, além de facilitar nossa capacidade de atualizar petabytes de dados nas tabelas do Hadoop.
Neste artigo, expandimos nossa série Big Data existente explicando os desafios envolvidos na solução desse problema em grande escala e compartilhamos como alavancamos o software de código aberto no processo.
Tipos de carga de trabalho de ingestão
Os dados Hadoop da Uber podem ser classificados em dois tipos: somente anexados e anexados-mais-atualizados. Os dados somente anexados/de acréscimo representam eventos imutáveis. Nos termos da Uber, os eventos imutáveis podem consistir no histórico de pagamentos de uma viagem.
Os dados anexados/de acréscimo-mais-atualizados mostram o estado mais recente de uma entidade em qualquer momento específico.
Por exemplo, na instância do tempo final de uma viagem, em que viagem é a entidade e a hora/o momento final é uma atualização para a entidade, a hora/o momento final é uma estimativa que pode mudar até que a viagem seja concluída.
A ingestão de dados somente de anexação não requer contexto em nenhum valor anterior, pois cada evento é independente.
No entanto, a ingestão de dados anexados/com acréscimo-mais-atualizados nos conjuntos de dados é diferente. Embora recebamos atualizações apenas de parte dos dados realmente modificados, ainda precisamos apresentar o instantâneo mais recente e completo da viagem.
Cargas de trabalho anexado-mais-atualizado
Construir conjuntos de dados geralmente consiste em duas fases: bootstrap e incremental/suplementar. Durante a fase de bootstrap, grandes quantidades de dados históricos do upstream são ingeridos em um curto período de tempo.
Essa fase geralmente ocorre quando nos conectamos a um conjunto de dados ou quando um conjunto de dados precisa ser reapresentado para manutenção.
A fase incremental/suplementar envolve o consumo de alterações de upstream incrementais recentes e sua aplicação ao conjunto de dados.
Essa fase geralmente domina o ciclo de vida restante de um conjunto de dados e garante que os dados estejam atualizados à medida que a origem upstream evolui.
Em sua forma básica, a ingestão de dados envolve a organização de dados para equilibrar a leitura e a gravação eficientes de dados mais recentes.
A organização de dados para leitura eficiente envolve padrões de consulta de fatoração para particionar dados de forma que dados mínimos sejam lidos.
Como os conjuntos de dados analíticos tendem a ser lidos várias vezes, os conjuntos de dados são particionados para evitar a varredura de todo o conjunto de dados.
Para uma escrita eficiente, o layout de dados é distribuído em vários arquivos nas partições para aproveitar o alto paralelismo durante gravações e, no caso de futuras atualizações de dados, limitar os registros de gravação apenas aos arquivos que contêm essas atualizações.
Outro aspecto de melhorar a eficiência de gravação com atualizações é desenvolver um componente para a pesquisa eficiente da localização dos dados existentes em nosso ecossistema Big Data. O índice global, um componente de ingestão, mantém informações contábeis do layout de dados.
Esse componente requer consistência forte para categorizar corretamente os dados recebidos como inserções ou atualizações.
Na categorização, inserções, como nossa nova viagem, são agrupadas e gravadas em novos arquivos, enquanto atualizações, como a hora de término de uma viagem, são gravadas nos arquivos pré-existentes correspondentes identificados pelo índice global, conforme ilustrado na Figura. 1, abaixo:
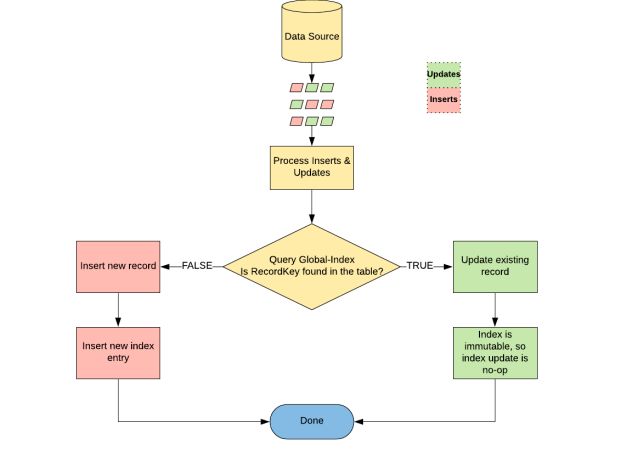
A seguir, uma visão geral da arquitetura de como o Índice Global contribui para o nosso sistema de ingestão.
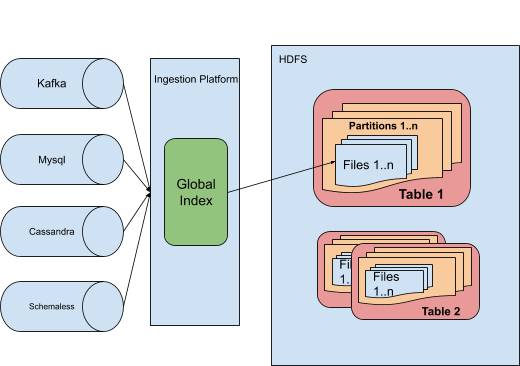
Uma solução simples para a indexação global seria usar um armazenamento de valor-chave comprovado, como o HBase ou o Cassandra. Esses armazenamentos de valor-chave podem suportar centenas de milhares de solicitações por segundo para leituras/gravações fortemente consistentes.
Para grandes conjuntos de dados, os requisitos de rendimento são muito altos durante a fase de bootstrap (na ordem de milhões de solicitações por segundo por conjunto de dados), pois grandes quantidades de dados precisam ser ingeridas em um período de tempo relativamente curto.
Os requisitos de rendimento durante a fase de bootstrap para um grande conjunto de dados na Uber são da ordem de milhões de solicitações por segundo.
Durante a fase incremental, no entanto, os requisitos de rendimento são muito menores (na ordem de milhares de solicitações por segundo por conjunto de dados), com exceção de picos ocasionais que podem ser controlados pela aceleração/estrangulamento da taxa de solicitação.
Leituras/gravações de índice de alta escala, consistência forte e amplificações de leitura/gravação de índice razoáveis são requisitos adicionais de um índice global.
Se dividirmos o problema lidando com a fase de bootstrap e a indexação de fase incremental separadamente, poderíamos usar um armazenamento de valor-chave que escala para endereçar a indexação de fase incremental, mas não necessariamente para a indexação da fase de bootstrap.
Para entender por que isso ocorre, vamos considerar como as fases incremental e de bootstrap diferem em termos de cargas de trabalho.
Indexação durante a ingestão de bootstrap
Se durante a fase de bootstrap os dados de origem foram organizados de forma que os dados de entrada tenham garantia de serem todos inserções (como mostrado na Figura 1), não há necessidade de indexação global. Na fase incremental.
No entanto, não podemos garantir que os dados recebidos sejam compostos apenas de inserções, pois temos que ingerir dados em intervalos regulares e as atualizações nas linhas podem chegar a qualquer intervalo.
Assim, um armazenamento de valor-chave precisa ser atualizado com índices antes de iniciarmos a fase incremental
Usamos essa propriedade para projetar nossa ingestão de bootstrap. Devido ao rendimento/processamento limitado de solicitações de armazenamentos de valores-chave, geramos índices do conjunto de dados e os carregamos em massa em um armazenamento de valor-chave sem emitir solicitações de gravação individuais, evitando assim o caminho de gravação típico.
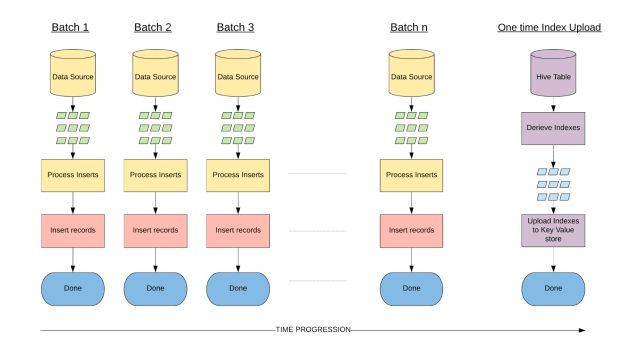
Escolhendo um armazenamento de valor-chave adequado
Com base nas simplificações acima, os requisitos de um armazenamento de valor-chave para fins de indexação durante a fase incremental são leituras/gravações fortemente consistentes, a capacidade de escalar para milhares de solicitações por segundo por conjunto de dados e uma maneira confiável de fazer upload em massa índices (isto é, evitando a taxa de transferência/o rendimento limitada/o no caminho de gravação).
O HBase e o Cassandra são dois importantes armazenamentos de valores amplamente usados na Uber. Para nossa solução de indexação global, optamos por usar o HBase pelos seguintes motivos:
- 1. Ao contrário do Cassandra, o HBase permite somente leituras e gravações consistentes, portanto não há necessidade de ajustar os parâmetros de consistência.
- 2. O HBase fornece rebalanceamento automático de tabelas do HBase dentro de um cluster. A arquitetura mestre-escravo permite obter uma visão global da disseminação de um conjunto de dados no cluster, que utilizamos na personalização de taxas de transferência/redimento específicas do conjunto de dados para o cluster do HBase.
Gerando e fazendo upload de índices com o HFiles
Geramos índices no formato de arquivo de armazenamento interno do HBase, conhecido como HFile, e os enviamos para o cluster HBase. Dados de partições do HBase com base em intervalos de chaves ordenados e não sobrepostos em servidores regionais no formato de arquivo HFile.
Dentro de cada HFile, os dados são classificados com base no valor da chave e no nome da coluna. Para gerar HFiles no formato esperado pelo HBase, usamos o Apache Spark para executar operações grandes e distribuídas em um cluster de máquinas.
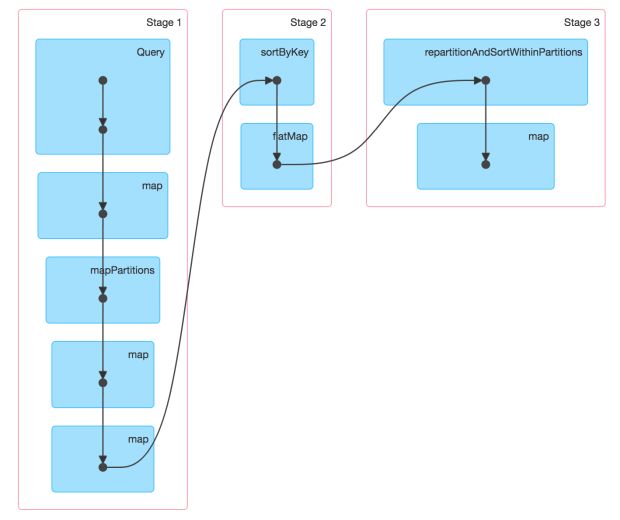
As informações de índice são extraídas primeiro como um conjunto de dados distribuído resiliente (RDD), mostrado na Figura 4, abaixo, do conjunto de dados inicializado/de bootstrapp e, em seguida, classificado globalmente com base no valor da chave usando RDD.sort().

Nós planejamos o RDD de forma que cada partição do Apache Spark seja responsável por gravar um HFile independentemente. Dentro de cada HFile, o HBase espera que o conteúdo seja apresentado conforme mostrado na Figura 5, abaixo, de forma que eles sejam classificados com base em um valor de chave e nome de coluna.
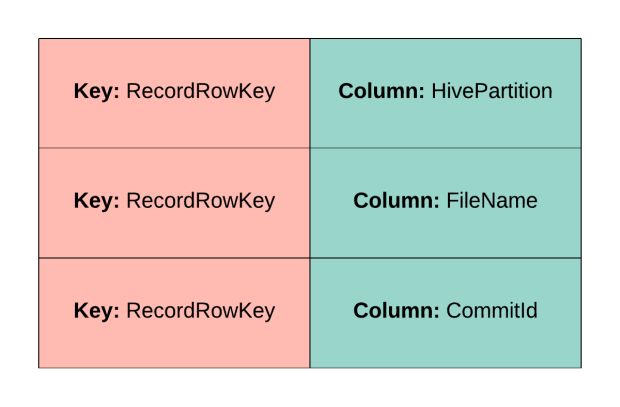
A transformação RDD.flatMapToPair() é, então, aplicada ao RDD para organizar dados no layout mostrado na Figura 5. Essa transformação, no entanto, não preserva a ordenação de entradas no RDD.
Portanto, executamos uma classificação de partição isolada usando o RDD.repartitionAndSortWithinPartitions() sem qualquer alteração no particionamento.
É importante não alterar o particionamento, pois cada partição foi escolhida para representar o conteúdo de um HFile. O RDD resultante é salvo usando HFileOutputFormat2.
Usando essa abordagem, a geração HFile de alguns dos nossos maiores conjuntos de dados, com tamanhos de índice nas dezenas de terabytes, leva menos de duas horas.
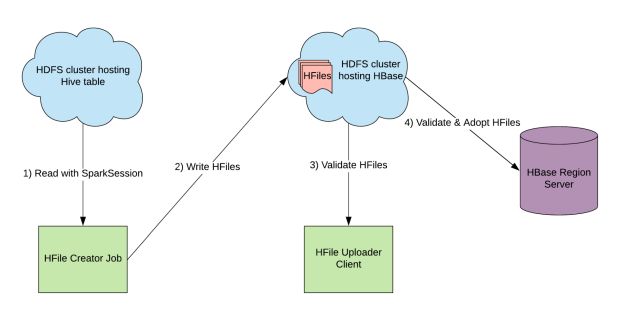
HFiles agora são enviados para o HBase usando um utilitário chamado LoadIncrementalHFiles. Um processo chamado HFile-splitting é acionado durante o upload pelo HBase, se não houver uma região pré-existente que contenha completamente o intervalo de chaves em um HFile ou se o tamanho do HFile for maior que um limite definido.
A latência do upload do HFile pode ser severamente afetada pela divisão, já que esse processo requer a regravação de todo o HFile. Evitamos a divisão do HFile lendo os intervalos de chaves do HFile e pré-dividindo a tabela do HBase em tantas regiões quanto HFiles, de modo que cada HFile possa se encaixar em uma região.
Ler apenas o intervalo de chave do HFile é mais barato em ordens de grandeza do que reescrever/regravar todo o arquivo, já que os intervalos de chaves do HFile são armazenados dentro dos blocos de cabeçalho.
Para alguns dos nossos maiores conjuntos de dados, com tamanho de índice nas dezenas de terabytes, o upload do HFile leva menos de uma hora.
Indexação durante ingestão incremental
Depois que um índice é gerado, o mapeamento entre cada chave de linha e o ID de arquivo não é alterado. Em vez de gravar o índice para todos os registros em nosso lote de ingestão, gravamos o índice apenas para inserções.
Isso nos ajuda a manter as solicitações de gravação para o HBase dentro dos limites e atender ao nosso rendimento necessário.
Acelerando/estrangulando o acesso do HBase
Como discutido anteriormente, o HBase não escala além de uma certa carga. Durante a fase incremental, há picos de carga ocasionais, portanto, precisamos limitar o acesso ao HBase. A Figura 8, abaixo, mostra como o HBase é acessado simultaneamente por vários trabalhos de ingestão independentes:
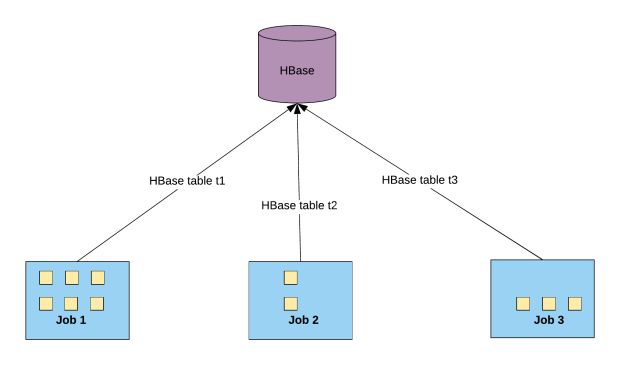
Controlamos gravações cumulativas por segundo para um servidor regional a partir de trabalhos independentes do Apache Spark com base em alguns fatores que afetam o número de solicitações ao Hbase:
- 1. Paralelismo de trabalho: o número de pedidos paralelos ao HBase dentro de um trabalho.
- 2. Número de servidores regionais: o número de servidores que hospedam a tabela específica do índice HBase.
- 3. Input QPSFraction: a fração de QPS cumulativo entre os conjuntos de dados. Normalmente, esse número é uma média ponderada do número de linhas em um conjunto de dados para garantir uma participação/divisão justa do QPS nos conjuntos de dados.
- 4. QPS com referência interna: o QPS que um servidor regional pode manipular.
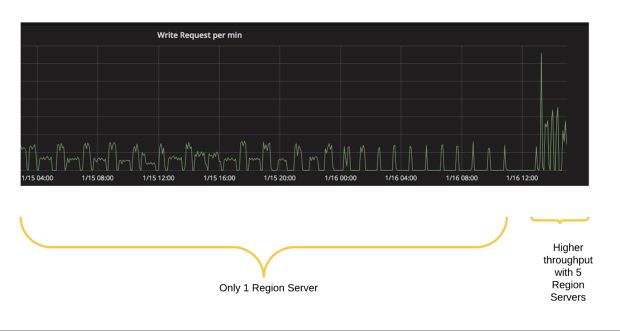
A Figura 9, abaixo, mostra uma experiência sobre como o algoritmo de limitação se ajusta para lidar com mais consultas, à medida em que os servidores da região HBase são adicionados ao cluster HBase.
Limitações do sistema
Embora o nosso sistema de indexação global tenha facilitado a confiabilidade e a consistência dos dados, existem algumas limitações do nosso sistema, conforme descrito abaixo:
- Referindo-se ao teorema CAP, o HBase fornece consistência e tolerância à partição, mas não oferece 100% de disponibilidade. Como os trabalhos de ingestão não são extremamente sensíveis ao tempo, podemos ter um contrato de nível de serviço mais descontraído no raro evento de tempo de inatividade do HBase.
- O processo de limitação pressupõe que a tabela de índices é uniformemente distribuída em todos os servidores regionais. Isso pode não ser verdade para conjuntos de dados que contêm um pequeno número de índices. Como tal, eles acabam recebendo uma parcela menor de QPS, o que compensamos com o aumento de seu QPSFraction.
- Requer um mecanismo de recuperação de desastres se os índices no HBase estiverem corrompidos ou se a tabela ficar indisponível devido a um desastre. Nossa estratégia atual é reutilizar o mesmo processo discutido anteriormente na geração de índices de um conjunto de dados e no upload para um novo cluster HBase.
Próximos passos
Nossa solução de indexação global acompanha os petabytes de dados que passam pela plataforma Big Data da Uber, atendendo aos nossos SLAs e requisitos. No entanto, existem algumas melhorias que estamos considerando:
- Por exemplo, simplificamos o problema da indexação global durante a fase de ingestão do bootstrap, garantindo que os dados consumidos sejam somente anexados, mas isso pode não funcionar para todos os conjuntos de dados. Por isso, precisamos de uma solução que resolva isso em grande escala.
- Gostaríamos de explorar uma solução de indexação que eliminasse a necessidade de uma dependência externa, como um armazenamento de valor-chave, como o HBase.
Por favor, envie seu currículo para hadoop-platform-jobs@uber.com se você estiver interessado em trabalhar conosco!
***
Este artigo é do Uber Engineering. Ele foi escrito por Nishith Agarwal e Kaushik Devarajaiah. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/data-partitioning-global-indexing/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?