

No escritório de engenharia da Uber em Nova York, nossa equipe de Observabilidade mantém uma métrica robusta e escalonável e um pipeline de alertas responsável por detectar, mitigar e notificar os engenheiros de problemas com seus serviços assim que eles ocorrerem.
Monitorar a integridade de nossos milhares de microsserviços nos ajuda a garantir que nossa plataforma funcione de maneira suave e eficiente para nossos milhões de usuários em todo o mundo, desde os passageiros e os motoristas parceiros até comedores e restaurantes parceiros.
Há alguns meses, uma implantação de rotina em um serviço principal do M3, nossa métrica de código aberto e plataforma de monitoramento, causou uma duplicação na latência geral para coleta e persistência de métricas para armazenamento, elevando o P99 das métricas de aproximadamente 10 segundos para mais de 20 segundos.
Essa latência adicional fez com que os painéis da Grafana sobre as métricas relacionadas aos nossos sistemas internos levassem mais tempo para serem carregados, e nossos alertas automáticos para os proprietários do sistema levariam mais tempo para serem disparados.
Mitigar o problema foi simples – nós apenas revertemos para a última boa construção conhecida, mas ainda precisávamos descobrir a causa raiz para que pudéssemos corrigi-la.
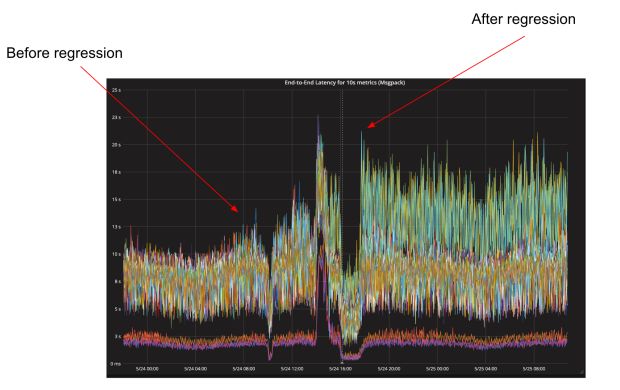
Embora muito tenha sido escrito sobre como analisar o desempenho do software escrito em Go, a maioria das discussões conclui com uma explicação de como visualizar perfis de CPU e heap com o pprof diagnosticou e resolveu o problema.
Nesse caso, nossa jornada começou com perfis de CPU e pprof, mas rapidamente saiu dos trilhos quando essas ferramentas falharam e fomos forçados a recorrer a ferramentas mais primitivas como git bisect, lendo a montagem do Plan 9 e sim, bifurcando o compilador Go .
Observabilidade na Uber
A equipe de observabilidade da Uber é responsável pelo desenvolvimento e manutenção da plataforma de métricas de ponta a ponta da Uber. Dentro da arquitetura da plataforma de ingestão, mostrada na Figura 2 abaixo, os aplicativos em nossos hosts emitem métricas para um daemon local (“collector”) que as agrega em intervalos de um segundo e as emite para nossa camada de agregação, que as agrega aos intervalos de 10 segundos e um minuto.
Finalmente, eles são escritos para o ingestor do M3DB, cuja principal responsabilidade é escrevê-los em nossa camada de armazenamento, o M3DB.
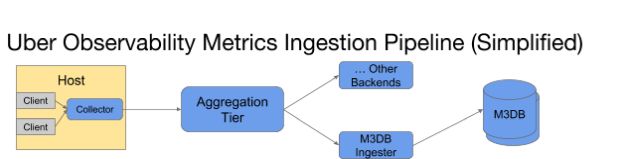
Devido à natureza de como o M3 faz a agregação ao ser ingerida, os ingestores recebem grandes lotes de métricas na forma de blocos pré-agregados em intervalos regulares, conforme mostrado na Figura 3, abaixo:

Como resultado, os ingestores do M3DB se comportam como uma fila improvisada, e a taxa na qual os ingestores podem gravar essas métricas para o M3DB controla nossa latência de ponta a ponta.
Manter a latência de ponta a ponta deste serviço baixo é importante porque a latência controla a rapidez com que as equipes internas da Uber podem exibir suas métricas mais recentes, bem como a rapidez com que nossos alertas automatizados podem detectar falhas.
Produção Bisecting
Quando uma implantação de rotina dos ingestores do M3DB dobrou a latência de ponta a ponta desse serviço, começamos com o básico. Pegamos um perfil da CPU do serviço executando em produção e visualizamos como um gráfico de chama usando o pprof.
Infelizmente, nada neste gráfico de chama se destacou como uma causa.
Como não vimos nada óbvio nos perfis de CPU, decidimos que nossa próxima etapa deveria ser identificar o commit que introduziu a regressão e, em seguida, poderíamos revisar as alterações de código específicas. Isso acabou sendo mais difícil do que o esperado por alguns motivos:
- 1. Os ingestores do M3DB não foram implantados por alguns meses, período em que algumas poucas alterações no código foram feitas. Identificar exatamente qual alteração causou o problema seria difícil, pois o código do serviço de ingestor (e de todos os outros serviços de nossa equipe) é armazenado em um monorepo, tornando o histórico de commits muito barulhento, com muitos commits não relacionados ao serviço. No entanto, esses commits não relacionados podem afetar dependências ou causar problemas indiretamente.
- 2. A regressão só se manifesta em cargas de trabalho de produção, onde o tráfego tende a ser espinhoso e sob carga pesada. Como resultado, não conseguimos reproduzi-lo localmente com micro-benchmarks/referências ou em nossos ambientes de encenação/teste.
Como resultado, decidimos que a melhor maneira de identificar o commit incorreto era executar um git bisect, uma busca binária de nosso histórico de commits, em produção.
Enquanto nós eventualmente identificamos o commit errado, mesmo o git bisect acabou se tornando muito mais difícil do que esperávamos, já que o commit errado acabou por depender de uma dependência, o que significa que tivemos que executar um git bisect de três níveis.
Em outras palavras, nós restringimos a questão a um commit em nosso monorepo interno que mudou a versão de uma dependência de software livre (M3DB), então reduzimos a um commit naquele repositório que mudou a versão de uma de suas dependências (M3X), o que significa que tivemos que git bisect/dividir esse repositório também.
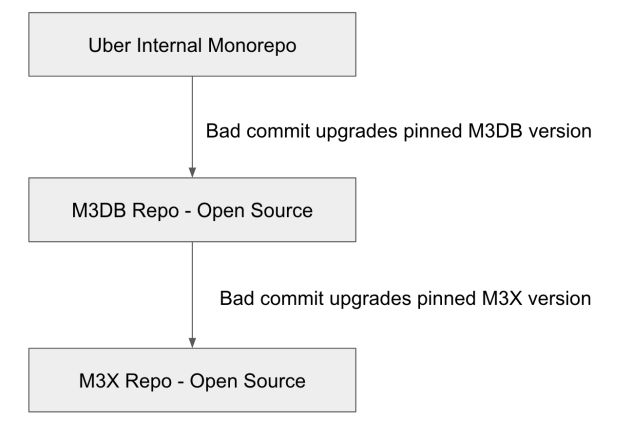
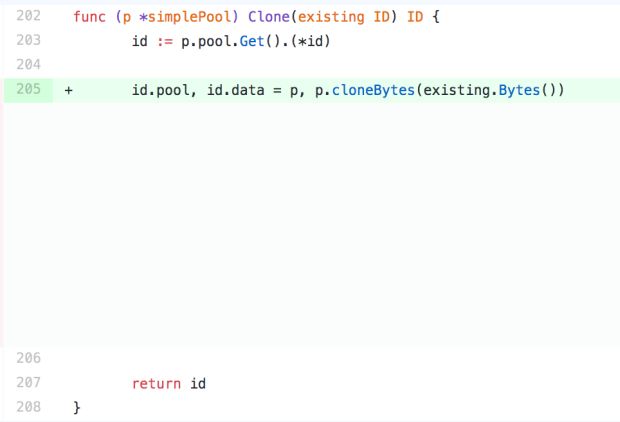
Quando tudo foi dito e feito, tivemos que implantar nosso serviço 81 vezes para encontrar o commit errado e diminuir a regressão de desempenho para uma pequena mudança que fizemos no método Clone, mostrado na Figura 5, abaixo:
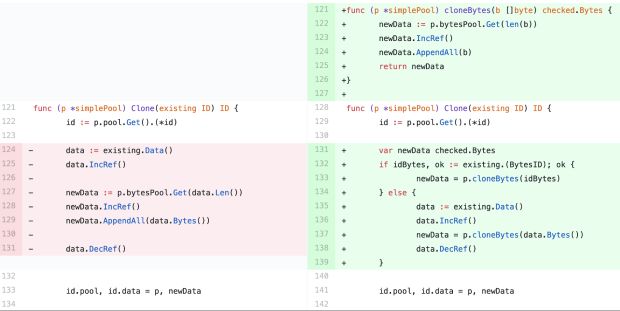
Foi difícil para nós acreditar que essa mudança aparentemente inócua poderia ter dobrado nossa latência de ponta a ponta, mas não poderíamos ignorar as evidências. Se implantássemos nosso serviço com o código à esquerda (Figura 5), a regressão de desempenho desapareceria e, se o implantássemos com o código à direita (também na Figura 5), ela retornaria.
De determinar o que a perguntar por que
Depois de descobrir o que causou essa mudança, decidimos determinar por que essa mudança teve um impacto tão dramático no desempenho.
Primeiro, avaliamos se alguns dos aspectos mais óbvios da mudança poderiam ser o problema, como o fato de que a conversão de tipos estava introduzindo uma alocação adicional ou talvez a declaração condicional extra estivesse interrompendo a previsão de ramificação da CPU.
Infelizmente, nós refutamos essas duas teorias muito rapidamente com microbenchmarks. De fato, não houve diferença perceptível no desempenho entre essas duas funções em nossos benchmarks, o que também pareceu excluir a sobrecarga de chamadas de função como um problema em potencial.
Além disso, mesmo após simplificar ainda mais o novo código, conforme mostrado na Figura 6, abaixo, ainda estávamos vendo a regressão em nossas implantações de produção:
Não tínhamos certeza do que fazer a seguir porque já comparamos os perfis de CPU para os dois commits e eles não mostraram nenhuma diferença na quantidade de tempo gasto no método Clone.
Como último esforço, decidimos comparar a montagem Go para cada uma das duas implementações.
Usamos o objdump para inspecionar nossos binários de produção executando o seguinte comando:
go tool objdump -S <PATH_TO_BINARY_WITH_REGRESSION> | grep /ident/identifier_pool.go -A 500A saída resultante ficou assim:
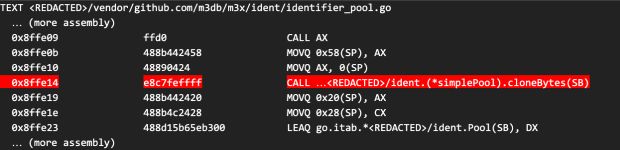
A montagem gerada para as duas funções teve diferenças sutis, como alocação de registros, mas não notamos nada que pudesse ter um grande impacto no desempenho, exceto pelo fato de que a função auxiliar cloneBytes não estava sendo embutida.
Não estávamos dispostos a acreditar que a sobrecarga da chamada de função era a fonte do problema, especialmente porque ela não parecia afetar os microbenchmarks, mas era a única diferença significativa entre as duas implementações que parecia ter algum impacto.
Quando inspecionamos a montagem para a função cloneBytes, notamos que ela fez chamadas para a função runtime.morestack, conforme mostrado abaixo:
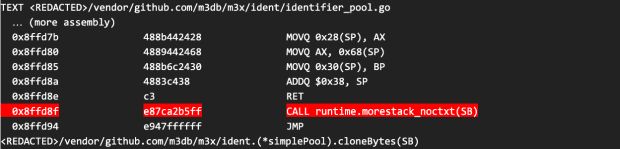
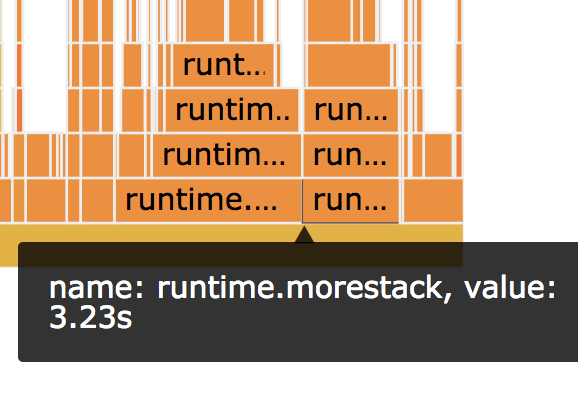
Isso não é surpreendente porque o compilador Go tem que inserir essas chamadas de função para funções que não podem provar que não superarão a pilha (mais sobre isso depois), mas chamou nossa atenção de volta para uma discrepância que observamos anteriormente na quantidade de tempo gasto na função runtime.morestack, conforme mostrado na Figura 7, abaixo:
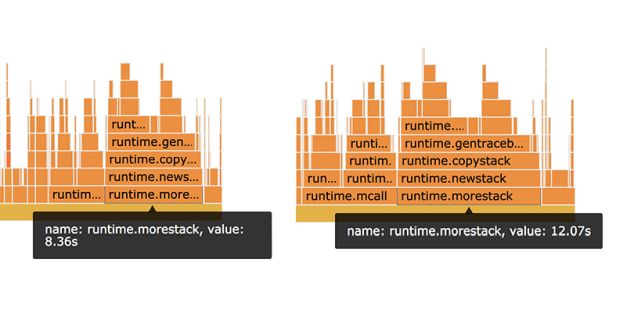
O gráfico de chama à esquerda (Figura 7) mostra quanto tempo foi gasto na função runtime.morestack antes da introdução da regressão, e o da direita mostra quanto ele gasta nessa função depois.
Quando examinamos originalmente os perfis de CPU, negligenciamos essa discrepância porque estava no código de tempo de execução, o qual não controlamos, e porque estávamos obcecados em tentar identificar uma diferença no desempenho do método Clone que controlamos.
Esta é realmente uma diferença enorme; o código com as regressões gasta 50% mais tempo nessa função e quatro segundos de 74 segundos de tempo de execução da CPU são significativos o suficiente para explicar nossa lentidão.
Entendendo o tempo de execução Go
Mas o que esta função está fazendo? Para entender isso, precisávamos entender como o tempo de execução do Go gerencia pilhas de goroutines.
Cada goroutine in Go começa com uma pilha de 2 kibibytes. À medida que mais itens e quadros de empilhamento são alocados e a quantidade de espaço de pilha exigida excede o valor alocado, o tempo de execução aumentará a pilha (em potências de 2) alocando uma nova pilha duas vezes maior que a anterior e copiando tudo, desde a pilha antiga até a nova.
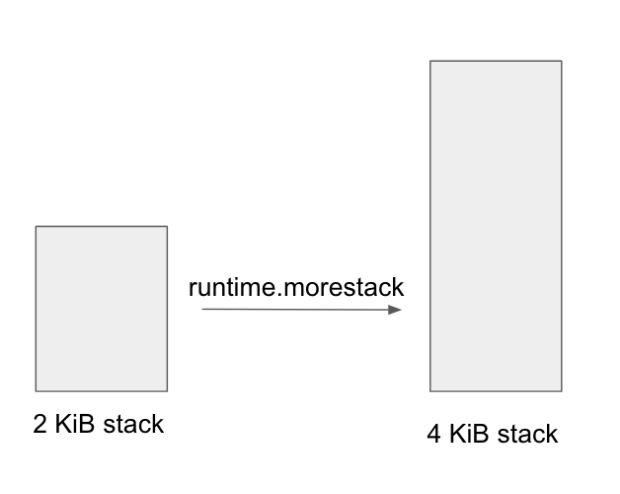
Isso nos deu uma nova teoria: o código existente estava sendo executado muito perto da borda de ter que aumentar sua pilha, e a chamada adicional para o método auxiliar cloneBytes estava empurrando-o sobre a borda e causando um crescimento adicional de pilha para acontecer.
Esse crescimento seria suficiente para causar a regressão que estávamos vendo, alinhado aos nossos perfis de CPU, e também explicou por que não conseguimos reproduzir o problema com nossos microbenchmarks.
Quando executamos os microbenchmarks, nossa pilha de chamadas era muito superficial, mas na produção o método Clone era chamado de 30 chamadas de função profundas (como mostrado na Figura 9).
Como resultado, a discrepância de desempenho só seria observada dentro do contexto específico que estávamos chamando a função.
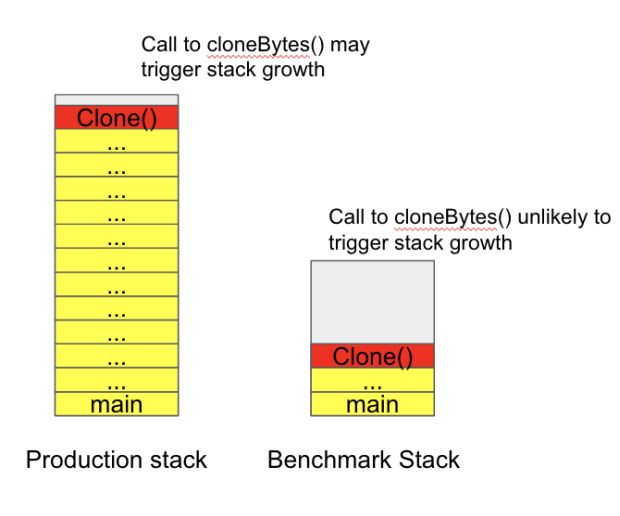
Queríamos uma maneira rápida e fácil de tentar validar essa teoria. A maneira como o ingestor M3DB funciona é que todo o trabalho pesado de escrever as métricas para o M3DB é executado por goroutines criadas por uma única instância desse pool/agrupamento de trabalho.
O código importante é reproduzido na Figura 10, abaixo:

Para cada lote de gravações recebidas, alocamos uma nova goroutine. O canal de trabalho, anotado como a variável workCh, atua como um semáforo, limitando o número máximo de goroutines que podem estar ativas a qualquer momento.
Isso permite que os ingestores se comportem como uma fila e armazenem em buffer nossa carga de trabalho espinhosa, de modo que, embora o número de métricas enviadas para os ingestores do M3DB seja muito complicado, as gravações recebidas pelo M3DB são suavizadas por um período mais longo.
Se a nossa teoria estivesse correta, então poderíamos aliviar a questão reutilizando goroutines em vez de constantemente gerar novos.
Enquanto o tempo de execução Go inicialmente aloca uma pilha de 2 kibibytes para cada nova goroutine e os cresce conforme necessário, ela nunca irá desalocar a pilha expandida até que a goroutine seja coletada como lixo (a verdade por trás de como isso funciona é na verdade um pouco mais complicada.
Existem alguns cenários em que o tempo de execução pode tentar “mover” a rotina para uma pilha menor, mas estatisticamente falando, a probabilidade de uma goroutine precisar aumentar sua pilha para qualquer chamada de função é muito menor).
Para testar nossa teoria, escrevemos um novo pool/agrupamento de trabalho que gera todas as goroutines iniciais e depois usa vários “canais de trabalho” diferentes (para reduzir a contenção de bloqueio) para distribuir o trabalho para os goroutines em vez de criar um novo para cada solicitação.

Nossa hipótese é que essa abordagem evite a quantidade excessiva de crescimento de pilha que estava ocorrendo com nossa implementação existente.
Embora cada goroutine ainda precise aumentar sua pilha na primeira vez que executou o código problemático, em chamadas subsequentes ele deve apenas ser capaz de estender seu quadro de pilha na memória já alocada sem incorrer no custo de uma alocação adicional de heap e cópia de pilha.
Só por segurança, também incluímos uma pequena probabilidade para cada goroutine terminar e gerar um substituto para si toda vez que completasse algum trabalho para evitar goroutines com pilhas excessivamente grandes sendo retidas na memória para sempre.
Essa precaução adicional provavelmente era excessivamente zelosa, mas aprendemos com a experiência que apenas os paranóicos sobrevivem.
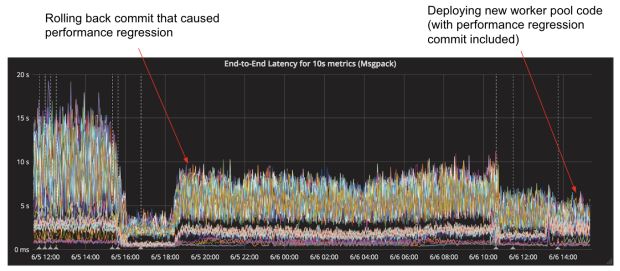
Nós implantamos nosso serviço com o novo pool/agrupamento de trabalho e ficamos felizes em ver que a quantidade de tempo gasto na função runtime.morestack caiu significativamente, conforme mostrado na Figura 12 abaixo:
Além disso, nossa latência de ponta a ponta na verdade diminuiu ainda mais do que era antes de introduzirmos a regressão, conforme mostrado na Figura 13, abaixo:
Curiosamente, uma vez que começamos a usar a nova implementação do pool de trabalho, não importava qual versão do método Clone() usamos quando o desempenho era o mesmo, independentemente de o auxiliar cloneBytes() estar ou não embutido.
Isso foi promissor porque significava que os futuros engenheiros não precisariam se preocupar com suas mudanças reintroduzindo esse problema, e também emprestaram crédito adicional à nossa teoria de crescimento de pilha.
Encontrar a arma fumegante
Mesmo depois de ver esses resultados, percebemos que não comprovamos suficientemente a causa raiz da regressão de desempenho.
Por exemplo, e se nossa economia de desempenho fosse apenas o resultado de não ter que gerar constantemente novas goroutines ou algum outro processo que ainda não entendemos completamente?
Naquela época, nos deparamos com essa questão do GitHub em que um engenheiro da equipe CockroachDB tinha um problema de desempenho semelhante relacionado a tamanhos grandes de pilha e conseguiu provar que o crescimento da pilha era a causa ao bifurcar o compilador Go e adicionar instrumentação adicional (leia: instruções de impressão).
Decidimos fazer o mesmo, mas, como estávamos planejando usar o compilador bifurcado para criar um serviço de produção, introduzimos a amostragem das instruções de impressão para evitar que o excesso de log diminuísse muito o serviço.
Especificamente, modificamos a função newstack, que é chamada toda vez que uma goroutine precisa aumentar sua pilha, de modo que, a cada milésima vez que fosse chamada, ela imprimia um rastreio de pilha para podermos ver quais caminhos de código estavam provocando o crescimento da pilha.
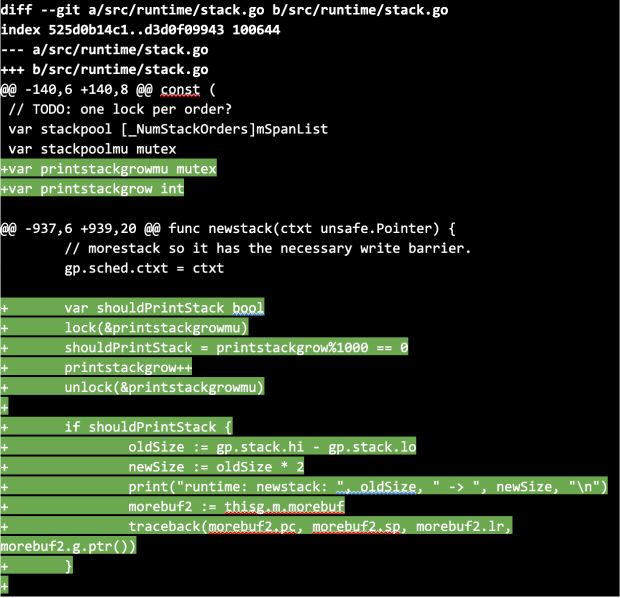
Em seguida, compilamos nosso serviço usando o compilador Go bifurcado e uma confirmação que ainda tinha a regressão de desempenho.
Nós enviamos para a produção e quase imediatamente começamos a ver logs que demonstraram que o crescimento da pilha de goroutine estava ocorrendo em torno do código problemático:
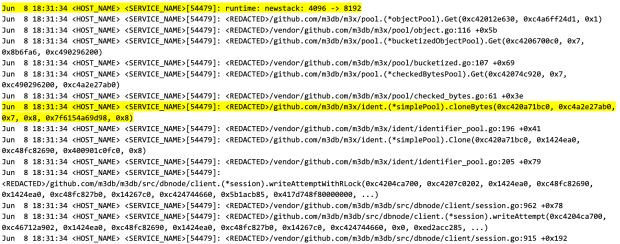
Agora tínhamos evidências de que o crescimento da pilha tendia a ocorrer em torno do código problemático e, nesse caso, parecia que a pilha de goroutines estava crescendo de 4 kibibytes para 8 kibibytes, o que é uma enorme alocação para ser executada por solicitação.
Mas isso ainda não era suficiente. Precisávamos saber com que frequência isso ocorreu e se o código que introduzia a regressão tinha maior probabilidade de acionar um crescimento de pilha.
Construímos nosso serviço com o compilador bifurcado novamente, dessa vez com três diferentes commits, e medimos quantas vezes um crescimento de pilha semelhante ao anterior ocorreu ao longo de dois minutos:
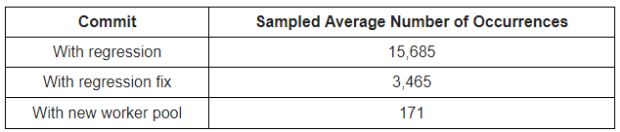
Com essas medições em mãos, nos sentimos muito mais confiantes de que a raiz do problema causou problemas e que o novo pool/agrupamento de trabalho impediria que problemas não autorizados/nocivos como esse surgissem novamente no futuro.
Mais importante, poderíamos finalmente dormir à noite, agora que realmente compreendemos o problema.
Principais tópicos
Toda a investigação de uma regressão de ingestão de latência de ponta a ponta no M3 envolveu dois engenheiros por aproximadamente uma semana, desde a detecção da regressão, a raiz causando isso e o envio da correção para a produção.
Nós aprendemos algumas lições importantes:
- 1. Geralmente, é necessária uma abordagem metódica ao tentar isolar problemas difíceis. Conseguimos restringir o problema a algumas linhas de código, com três níveis de dependência, porque éramos metódicos com nosso git bisect.
- 2. Raiz causando um problema, tanto quanto possível, leva a uma maior compreensão e, no nosso caso, melhor desempenho. Poderíamos ter revertido a mudança e encerrado o dia, mas, nesse caso, ir além nos permitiu reduzir nossa latência de ingestão de ponta a ponta pela metade – antes da regressão. Isso significa que, seguindo em frente, precisaremos de apenas metade do hardware para manter os mesmos SLAs.
- 3. Um profundo entendimento dos componentes internos de sua linguagem de programação é importante para fazer otimizações de desempenho, especialmente quando ferramentas de criação de perfil ficam aquém (o que é mais frequente do que você pensa).
- 4. Em Go, é importante agrupar objetos, mas também agrupar goroutines.
Por fim, tive a sorte de um membro da equipe de engenharia do Google Go me ver dando uma palestra sobre esse problema no meetup da Uber no NYC Go, pedindo que eu arquivasse um problema sobre ele no repositório Go GitHub e melhorasse o perfil de tempo de execução.
O tempo gasto no runtime.morestack agora é atribuído corretamente à chamada de função que acionou o crescimento da pilha, de modo que outros engenheiros terão muito mais facilidade em diagnosticar esse problema no futuro.
Somos muito gratos à equipe do Go e ao compromisso deles em atacar e solucionar agressivamente problemas que afetam os sistemas de produção.
Se você tiver alguma dúvida ou quiser apenas discutir a pilha de métricas do M3 da Uber, participe do canal M3DB Gitter.
Não deixe de visitar a página oficial de código aberto da Uber para obter mais informações sobre o M3 e outros projetos.
Se você estiver interessado em lidar com desafios de infraestrutura em escala, considere a possibilidade de se candidatar a um cargo em nossa equipe.
***
Este artigo é do Uber Engineering. Ele foi escrito por Richard Artoul. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/optimizing-m3/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?