



Teste inteligente, não árduo – Parte 02
Na primeira parte, o autor falou as abordagens amostragem aleatória e testes emparelhados. Nesta parte, saiba mais sobre o teste N-wise.

Na primeira parte, o autor falou sobre a importância dos testes e apresentou as abordagens amostragem aleatória e testes emparelhados. Nesta parte, saiba mais sobre o teste N-wise.
Teste N-wise
O conceito de teste emparelhado pode ser estendido para cada combinação de N entradas possíveis para o futuro teste N-wise. Essa é uma simples extensão da ideia por trás do pair-wise. Bons desenvolvedores irão pegar os erros causados pela combinação de duas variáveis. Mesmo os melhores desenvolvedores irão ignorar três variáveis (ou quatro ou mais combinações de variáveis).
A tabela a seguir mostra quantos testes são necessários para obter uma cobertura completa de cada combinação N-wise de entradas dos configuradores de laptop, tanto para o low-end quanto para o high-end.
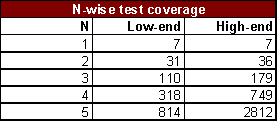
Essa é uma situação muito mais gerenciável. A cobertura exaustiva nos obrigou a usar 2,3 milhões de testes, onde o uso de testes N-wise com N=3 resultou em apenas 179 testes! Os estudos existentes têm consistentemente mostrado que N=3 cria a ordem de cobertura de código de 90% com conjuntos de testes, embora o número irá variar de aplicação para aplicação. Usaremos N=3, com base na experiência prática que testes N=4 raramente descobrem erros que foram perdidas com N=3.
Essa abordagem só funciona quando os usuários são forçados a entrar valores em uma sequência proibida e nos casos em que a sequência de entrada é irrelevante. Esse conjunto de testes não nos dará cobertura representativa do que os usuários vão fazer quando eles estiverem autorizados a fazer seleções em ordem arbitrária, mas relevante. Se a ordem não importa para nós (por exemplo, a maioria das assinaturas de API tem uma ordem fixa, e muitos sites irão processar múltiplas entradas em um lote), então temos a nossa metodologia desejada.
Relevância na ordem e testes estatísticos
Houve um pressuposto implícito em todos os nossos cálculos até agora: que a ordem de seleção nos controles é irrelevante. As ferramentas de cálculo de teste N-wise disponíveis não incorporam a ordem de seleção em suas permutações explicitamente, elas assumem uma ordem fixa das operações. Quando testamos uma API, temos controle sobre a ordem de processamento, há um número fixo de argumentos, em uma ordem fixa. As pessoas, no entanto, nem sempre interagem com os controles em uma ordem fixa. E arquiteturas de serviços web podem não ser capazes de depender de uma sequência predeterminada de eventos.
Com cinco controles em uma interface, temos 5! (fatorial) ou 120 possíveis sequências em que as seleções podem ser feitas por uma pessoa. Embora a interface do usuário possa incorporar a filtragem dinâmica que impede que alguns subconjuntos de seleção fiquem fora de sequência, o teste N-wise é um teste do tipo caixa-preta e, assim, não terá acesso a essas informações.
Para uma interface com M controles possíveis, cada script criado por um gerador de teste N-wise terá que ser testado em M! sequências para obter uma cobertura exaustiva. Se os controles são divididos em várias telas, então podemos reduzir o número de sequências. Por exemplo, se há cinco controles na primeira tela, e cinco controles na tela seguinte, em vez de considerar 10! (3,6 milhões de sequências), podemos considerar todas as da primeira tela em combinação com todas as sequências da segunda tela (5! * 5! = 120 * 120 = 14.400 sequências de script).
Em nosso exemplo de configuradores de laptop, há 11 e 13 controles (todos na mesma página) para o laptop low-end e o high-end, respectivamente. Isso implicaria 11! e 13! possíveis sequências de (40 milhões e 6 bilhões).
Nós não precisamos fazer uma cobertura exaustiva das permutações de sequenciamento. Um teste N-wise analisa especificamente a interdependência de qualquer combinação de controles N. Como um limite inferior, nós só precisamos de sequências N! para cada script gerado. Portanto, a nossa suíte 179-script para o laptop high-end (com N=3) precisaria de 3! (6) * 179 = 1.074 scripts para cobrir o produto.
Aqui está a tabela para o limite inferior de scripts necessários para ter em conta diferentes valores de N para ambos configuradores de laptop.
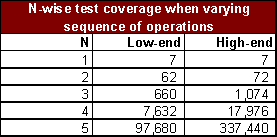
Esse é um limite inferior, porque ele assume uma perfeita eficiência na combinação de sequências únicas de cada grupo de controles N. Ferramentas existentes de teste N-wise não (ao conhecimento do autor) tomam ordem de operações em conta. Para N=2, isso é trivial, apenas duplique o conjunto de testes, na ordem inversa exata.
Podemos tomar a ordem das operações em conta tratando a sequência como uma entrada adicional. Nós usamos a fórmula matemática “X escolhe Y”, que nos diz o número de combinações diferentes de valores de Y a partir de um conjunto de valores de X. A fórmula para calcular “X escolhe Y” é X!/ (Y!*(X-Y)!), em que X é o número de entradas e o símbolo Y representa a dimensão do teste N-wise desejado.
Aqui está a tabela do número de combinações para cada N, tanto para a tela de configuração do laptop low-end e o high-end que estamos discutindo.

Aqui estão os valores, em geral, para diferentes números de entradas.
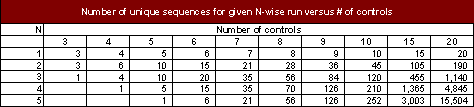
Nós, então, iremos calcular o teste N-wise usando um valor de N+1 como uma entrada para a ferramenta de test-generation, e incluir o número de sequências únicas como se fosse uma entrada de controle.
Infelizmente, não temos um solucionador capaz de lidar com dimensões individuais maiores do que 52. Isso limita a nossa capacidade de criar um conjunto de testes para N=3 com um máximo de 7 controles.
Para mostrar o impacto do sequenciamento no conjunto de testes, considere uma interface com sete controles, cada uma com cinco valores possíveis. N=3 exigiria 236 testes se a ordem fosse irrelevante. Em seguida, incluímos a sequência de seleção como um parâmetro (adicionando um oitavo controle com 35 valores possíveis, e testando para N=4). Nesse caso, N=3 (com o sequenciamento) requer 8.442 scripts. Nosso limite inferior teórico seria 236 * 35 = 8260.
Como tornar isso ainda melhor
Quando não sabemos nada, ou não aplicamos qualquer conhecimento sobre a nossa aplicação para a nossa estratégia de testes, vamos acabar com testes demais. Ao aplicar o conhecimento da aplicação para o nosso projeto de testes, podemos reduzir significativamente o tamanho do nosso conjunto de testes. Testes que incorporam conhecimento da aplicação que está sendo testada são conhecidos como testes de caixa branca.
Mapear as dependências de controle
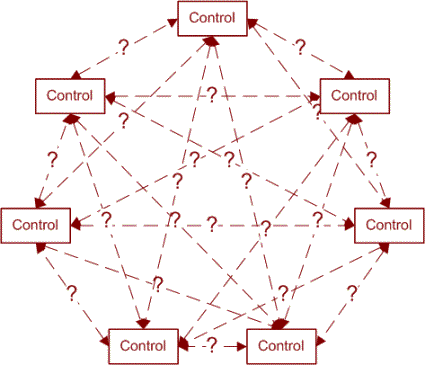
Em nossos exemplos anteriores, não aplicamos nenhum conhecimento das interações dos controles, ou as interações dentro do programa de ter seleções feitas nos controles. Se considerarmos um mapa visual dos controles e suas possíveis relações, seria parecido com o diagrama a seguir.
Há uma conexão possivelmente relevante entre as seleções em cada par de controles. Nós projetamos nossos testes em torno da falta de conhecimento que é claramente visível no diagrama.
É provável que possamos excluir algumas das dependências, mas possivelmente não todas elas. A nossa abordagem deve ser conservadora; só removemos as dependências que sabemos que não existem. Esse conhecimento vem de uma compreensão da aplicação subjacente. Uma vez que removemos essas ligações do diagrama, ele ficará parecido com isto:
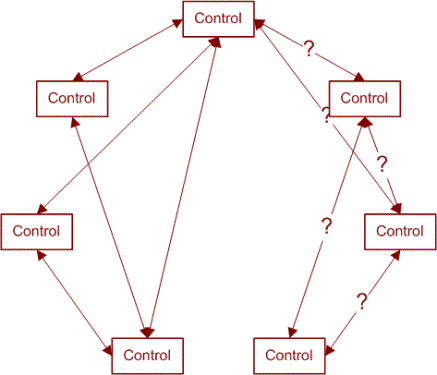
Esse mapeamento mais claro nos permite reduzir o tamanho da nossa suíte de testes dramaticamente, porque nós identificamos a independência de muitos controles. Em um caso ideal, o resultado será dois ou mais gráficos completamente desconectados, e nós podemos construir um conjunto de testes para a nossa suíte em torno de cada gráfico separado. Como o diagrama acima mostra, não temos dois gráficos completamente independentes. Nós podemos ter uma abordagem de teste como mostrado no diagrama a seguir:
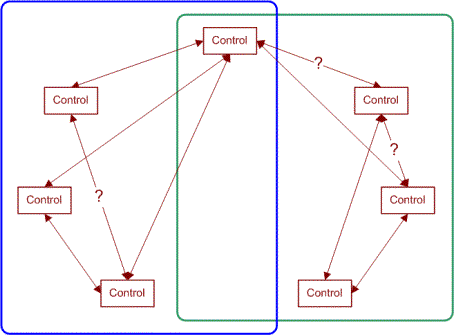
Nós agrupamos todos os controles do lado esquerdo em uma caixa azul. Esses controles serão usados com a ferramenta de geração N-wise para criar um conjunto de testes. O agrupamento de controles à direita também será usado para gerar um conjunto de testes.
Neste exemplo, nós reduzimos o número de testes necessários para uma quantidade significativa quando questões de ordem importam.

Observe também que aumentamos o número de testes necessários quando a ordem não importa, se tivermos quaisquer controles sobrepostos (se os gráficos não puderem ser separados). Quando os gráficos podem ser separados, isso reduz a quantidade de testes, mesmo se a ordem é irrelevante.
A chave para separar os gráficos é certificar-se de que todos os controles apenas se conectam a outros controles dentro de sua região (incluindo a região de sobreposição).
Eliminar valores equivalentes das entradas
Quando sabemos como o código é implementado, ou temos insights sobre os requisitos, podemos reduzir ainda mais o escopo dos testes, eliminando valores equivalentes. Considere os seguintes requisitos de exemplo para uma aplicação:

A próxima tabela mostra duas variáveis que estamos avaliando em nossos testes imaginários, que são os controles em uma interface de usuário (ou valores importados de um sistema externo).

Se fizéssemos um conjunto de testes emparelhados sem o conhecimento dos requisitos, teríamos 18 testes para avaliar. Ficamos com 18 testes por encontrar todas as combinações únicas dos dois controles (6 valores * 3 valores de conta de status = 18 combinações). No entanto, com o conhecimento dos requerimentos, podemos identificar que alguns dos valores são equivalentes. As regiões destacadas representam valores equivalentes (com respeito aos requisitos).

Que podemos reduzir para fins de teste para:

Essa consolidação dos valores equivalentes reduz o número de testes que precisam ser executados. Para o nosso teste de pares simples, podemos reduzir o número 18 para 12. O número é reduzido porque agora temos 4 valores de quantidade de ordem * 3 valores de status de contas = 12 combinações. Quando existem mais controles envolvidos, e quando estamos fazendo testes N-wise com N=3, o impacto é muito mais significativo.
Conclusão
Quando estamos testando qualquer software, somos confrontados com o tradeoff entre o custo e o benefício do teste. Com software complexo, os custos dos testes podem crescer mais rápido do que os benefícios. Se aplicarmos técnicas como as deste artigo, podemos reduzir drasticamente o custo de testar o nosso software. Isso é o que queremos dizer quando dizemos teste inteligente, não árduo.
Resumindo as técnicas abordadas neste artigo:
- Podemos testar qualquer software muito complexo sem fazer testes exaustivos.
- A amostragem aleatória é uma técnica comum, mas fica aquém das metas de alta qualidade; muito boa qualidade requer quantidade muito elevada de testes.
- Teste emparelhado permite testar software muito complexo, com um pequeno número de testes, e razoável (da ordem de 90%) cobertura de código. Isso também fica aquém das metas de alta qualidade, mas é muito eficaz para as expectativas mais baixas.
- Teste N-wise com N=3 fornece conjuntos de teste capazes de alta qualidade, mas à custa de maiores suítes. Quando a ordem das entradas no software importam, as abordagens N-wise tornam-se limitadas no número de variáveis que podem suportar (menos de 10), devido a limitações de ferramentas de geração de teste disponíveis hoje.
- Podemos aplicar o conhecimento do software e os requisitos para melhorar a nossa estratégia de teste. Nenhuma das técnicas anteriores requer conhecimento da aplicação e, portanto, confia na força bruta para garantir a cobertura. Esta abordagem resulta em testes conceitualmente redundantes na suíte. Mapear a rede de interdependência entre as entradas e subdividir os testes em várias áreas reduzem o número de testes em nossa suíte. Ao eliminar valores redundantes ou equivalentes do conjunto de teste, nós também reduzimos o número de testes necessários para atingir alta qualidade.
Teste inteligente, não árduo.
***
Scott Sehlhorst faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://www.developerdotstar.com/mag/articles/test_smarter_not_harder.html
É gerente de produto e consultor de estratégia que tem atuado na área de alta tecnologia desde 1997 - primeiro como um programador, depois como analista, e por fim como fundador da Tyner Blain, em 2005. Tem ajudado empresas desde startups até as de grande porte em todo o mundo com atividades como o lançamento de uma plataforma móvel até sistemas globais de comércio eletrônico. Scott muitas vezes ajuda as empresas a evoluir à medida que suas equipes de desenvolvimento se tornam ágeis. Está sempre auxiliando as empresas a descobrirem e definirem os produtos certos para seus mercados e estratégias. Antes de entrar no mundo do software, Scott era um engenheiro de projeto eletromecânico, com um BSME da Carnegie Mellon University, em Pittsburgh, EUA.



