



Teste inteligente, não árduo – Parte 01
O autor fala sobre a importância dos testes e apresenta as abordagens amostragem aleatória e testes emparelhados.

Introdução: Complexidade leva à futilidade
Imagine que estamos desenvolvendo uma página web para personalizar uma compra de laptop.
Se você nunca configurou um laptop online antes, dê uma olhada na página da Dell “customize it” para um laptop de nível de entrada. O site apresenta 11 perguntas ao usuário que têm de duas a sete respostas cada. O usuário tem que escolher entre duas opções no primeiro controle, dois no segundo, e por aí vai. O usuário tem sete opções possíveis para o último controle.
Quando olhamos para todos os controles combinados, o usuário tem que fazer (2,2,2,2,2,3,2,2,3,4,7) escolhas. Esse é um simples problema de configuração. O número possível de configurações do laptop que pode ser solicitado pelo usuário é o produto de todas as escolhas. Nessa página muito simples, existem 32.256 possibilidades. No momento em que escrevo este artigo, a página para personalizar um laptop high-end da Dell tem um conjunto não muito diferente dos controles, com mais opções em cada controle: (3,3,3,2,4,2,4,2,2, 3,7,4,4). O usuário dessa página pode solicitar qualquer uma das 2.322.432 diferentes configurações de laptop! Se a Dell tivesse que adicionar mais um controle apresentando cinco opções diferentes, haveria mais de 10 milhões de combinações possíveis!
Criar um conjunto de testes que tenta todas as dois milhões de combinações de um laptop high-end poderia ser automatizado, mas mesmo se cada um dos testes levasse um décimo de segundo para executar, isso levaria mais de 64 horas! A Dell muda suas ofertas de produtos em menos tempo do que isso.
Então, novamente, se usarmos um farm de servidores para distribuir o conjunto de testes em 10 máquinas, isso poderia ser executado em cerca de seis horas. Ignorando o fato de que estaríamos executando esse tipo de teste para cada página de personalização que a Dell tem, seis horas é algo totalmente fora da curva.
Validar os dois milhões de resultados é onde o problema realmente grande está esperando por nós. Nós não podemos confiar nas pessoas para validar manualmente todas as saídas, porque isso é muito caro. Poderíamos escrever um outro programa, que inspeciona essas saídas e as avalia usando um sistema baseado em regras (“se o usuário seleciona 1GB de RAM, a configuração deve incluir 1GB de RAM” e “O preço para o sistema final deve ser ajustado pelo impacto do 1GB de RAM em relação ao preço do sistema base para esse modelo”).
Existem algumas boas ferramentas de validação baseadas em regras por aí, mas ou elas são software personalizado ou tão geral que exigiriam um grande investimento para torná-las aplicáveis a um determinado cliente. Com um sistema de controle baseado em regras, temos o custo de manter as regras. As regras de validação teriam que ser atualizadas regularmente, já que a Dell muda a maneira como elas se posicionam, configurações e preço de seus laptops.
Como não somos a Dell, não temos a escala (bilhões de dólares de receita) para justificar esse nível de investimento. A nossa realidade é que não podemos nos dar ao luxo de testar exaustivamente todas as combinações. Acionistas da Dell obrigam a empresa a crescer o negócio, e essas páginas de configuração são o veículo pelo qual a Dell gera bilhões de dólares em receita. Eles têm que testar. O custo dos erros (falhas, perda de vendas, itens com valores errados, combinações inválidas de recursos) é muito alto. Com esse nível de risco, o custo de não testar (o custo de má qualidade) é extremamente elevado.
Nós não temos recursos para testar
Eu fui capaz de assistir a uma sessão de treinamento com Kent Beck, há alguns anos. Eu também tive a honra de ser capaz de desfrutar grande bife e um pouco de cerveja gelada com ele naquela noite após o treinamento. Quando perguntado como ele responde a pessoas que reclamam sobre o custo da qualidade, Kent nos disse que ele tem uma resposta muito simples: “Se o teste custa mais do que não testar, então não faça”.
Eu concordo. Há poucas situações em que o custo da qualidade excede o custo da má qualidade. Essas são situações em que a infraestrutura necessária, o tempo de teste para o desenvolvimento e os custos de manutenção superam o custo esperado de ter um bug (o “custo esperado” é a probabilidade (em percentagem) do bug manifestando em produção, multiplicado pelo custo de lidar com o erro).
As técnicas descritas neste artigo são projetadas para reduzir o custo da qualidade, para tornar ainda menos provável que “não testar” é a melhor resposta.
Apenas teste tudo, é automatizado!
Duas “soluções” que temos que considerar são testar nada e testar tudo. Gostaríamos de considerar testar nada se não pudemos tivermos condições de testar o software. Quando as pessoas não apreciam as complexidades de testes ou as limitações de testes automatizados, elas estão dispostas a querer “testar tudo.” Testar tudo é muito mais fácil de falar do que de fazer.
Você já esteve em um projeto no qual o gerente disse algo como: “Eu exijo total cobertura de testes do software. Nossa política é de tolerância zero. Não teremos má qualidade enquanto estiver sobre minha supervisão”?
Aqui, lutamos contra a falta de apreço por aquilo que significa ter “cobertura total” ou qualquer outra garantia de uma taxa de defeito particular.
Não há absolutos em um sistema suficientemente complexo, mas tudo bem. Existem estatísticas, níveis de confiança, e planos de gestão de riscos. Como engenheiros e desenvolvedores de software, nossos cérebros estão ligados para lidar com o esperado, desejável e provável futuro. Nós temos que ajudar nossos irmãos menos técnicos a entender esses conceitos, ou pelo menos a colocá-los em perspectiva.
Podemos ficar perguntando: “Por que não podemos simplesmente testar cada combinação de entradas para ter certeza de que temos as saídas certas? Nós temos uma suíte de teste automatizado – apenas configure e execute!”.
Precisamos resistir ao desejo de responder dizendo, “Macacos com máquinas de escrever terão completado as obras de Shakespeare antes de terminarmos uma única execução de nosso pacote de testes!”.
Resolvendo o problema
Há uma grande quantidade de aplicações que têm milhões ou bilhões de combinações de entradas. Elas têm testes automatizados. Elas têm soluções para esse problema. Nós acabamos de discutir como é impraticável testar exaustivamente, então como as empresas testam seu software complexo?
No restante do artigo, vamos explorar as seguintes abordagens para resolver o problema.
- A amostragem aleatória
- Testes emparelhado
- Testes N-wise
Nós também iremos explorar o impacto que a alteração da ordem das operações tem sobre a nossa abordagem de teste e os métodos para o teste quando a sequência importa.
A amostragem aleatória
Logo no início no mundo dos testes de software, alguém percebeu que, verificando aleatoriamente diferentes combinações de entradas, acabaria por encontrar os bugs. Imagine que o software que tem um milhão de combinações possíveis de entradas (metade complexo do nossos exemplos anteriores). Cada amostra aleatória nos daria 0.000001% de cobertura de todas as sessões de usuário possível. Se executarmos 1.000 testes, nós ainda só teríamos 0,001% de cobertura da aplicação.
Felizmente, as estatísticas podem nos ajudar a fazer declarações sobre nossos níveis de qualidade. Mas não podemos usar “cobertura” como nossa principal medição da qualidade. Temos que pensar sobre as coisas de forma um pouco diferente. O que queremos fazer é expressar um nível de confiança sobre o nível de qualidade. Precisamos determinar o tamanho da amostra, ou o número de testes, que temos de executar para fazer um levantamento estatístico sobre a qualidade da aplicação.
Primeiro, definimos uma meta de qualidade – queremos assegurar que o nosso software é 99% livre de erros. Isso significa que até 1% das sessões de usuário podem exibem um bug. Para ser 100% confiante de que essa afirmação é verdadeira, seria necessário testar pelo menos 99% das possíveis sessões de usuários, ou mais de 990.000 testes.
Ao adicionar um nível de confiança para nossa análise, podemos usar amostragem (seleção de um subconjunto do todo, e extrapolando esses resultados como sendo característica do todo) para descrever a qualidade do nosso software. Vamos aproveitar o trabalho matemático que tem sido desenvolvido para determinar como executar pesquisas.
Nós definimos como nosso objetivo ter 99% de confiança de que o software é 99% livre de erros. O nível de 99% de confiança significa que se executarmos a amostra várias vezes, 99% do tempo, os resultados seriam dentro da margem de erro. Como a nossa meta é um código 99% livre de bug, vamos testar para 100% de testes passados, com uma margem de 1% de erro.
De quantas amostras que precisamos, se há um milhão de combinações, para identificar o nível de qualidade com uma confiança de 99%, e uma margem de 1% de erro? A matemática para isso está facilmente disponível, e as calculadoras para determinar o tamanho de amostra estão online e são gratuitas. Usando essa abordagem de pesquisa, descobrimos que o número de amostras que precisamos para determinar o nível de qualidade com um erro de 1% e 99% de confiança é 16.369.
Se testarmos 16.369 sessões do usuário e tivermos 100% de sucesso, nós estabelecemos uma confiança de 99% que a nossa qualidade está, pelo menos, no nível de 99%. Nós só temos qualidade de 99%, porque encontramos 100% de qualidade em nossos testes, com uma margem de 1% de erro.
Essa abordagem funciona para um grande número de combinações. Considere a seguinte tabela, na qual nosso objetivo é estabelecer 99% de confiança em um nível de qualidade de 99%. Cada linha na tabela que se segue representa uma aplicação de software cada vez mais complexa. A complexidade é definida como o número possível de combinações únicas de entradas.
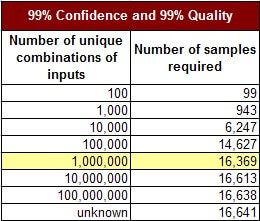
Podemos ver que poucos testes adicionais têm de ser executados para alcançar o mesmo nível de qualidade para o software cada vez mais complexo. Quando temos uma meta de qualidade modesta, tal como 99/99 (99% de confiança e 99% de qualidade), essa aproximação é muito eficaz.
Onde essa abordagem não escala bem é com níveis crescentes de qualidade. Considere a busca por “cinco noves” (99,999% de código livre de bugs). Com cada aumento no nível desejado de qualidade, o número de testes que tem que ser executado cresce. Ele rapidamente se torna um conjunto de testes quase exaustivo.
Cada linha na tabela que se segue representa um requisito de qualidade cada vez mais rigoroso, com a complexidade do software ficando constante a um milhão de combinações possíveis de entrada.
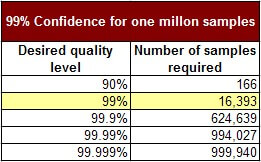
A abordagem de amostragem aleatória não fornece um benefício sobre os testes exaustivos quando as nossas metas de qualidade são elevadas.
Teste emparelhado de variáveis de entrada
Estudos tem mostrado que bugs em software tendem a ser os resultados da combinação de variáveis, não variáveis individuais. Isso passa o nosso “gut-check”, pois sabemos que os desenvolvedores conscientes irão testar seu código. O que escapa através dos cracks são combinações descuidadas de entradas, não entradas individuais.
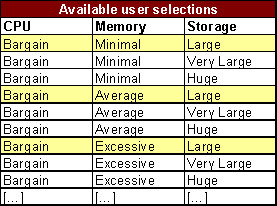
Considere uma página de configuração de laptop muito simples, com três controles selecionáveis: CPU, memória e armazenamento. Cada controle tem três valores possíveis, como mostrado na tabela abaixo.

Nós passamos com sucesso os testes de cada um dos diferentes valores disponíveis no controle da CPU. No entanto, descobrimos que nosso teste irá falhar se o usuário seleciona um valor CPU de “Consumer” e seleciona um valor de armazenamento de “Huge”. Isso destaca uma dependência desconhecida entre a CPU e os controles de armazenamento.
Teste emparelhado é projetado para obter a cobertura de todas as combinações possíveis de duas variáveis, sem testar todas as combinações possíveis de todas as variáveis. Para este exemplo, existem 27 combinações únicas de todas as seleções. A tabela a seguir mostra as primeiras 9 combinações. 9 combinações adicionais são necessárias para cada uma das outras seleções de CPU.
Testes emparelhados exaustivos darão a certeza de que cada combinação única de quaisquer duas variáveis será coberta. A tabela a seguir mostra as combinações para este exemplo.
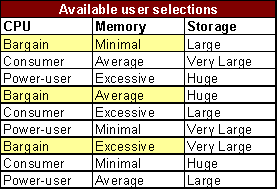
Com apenas 9 testes, somos capazes de cobrir exaustivamente cada par único de CPU e memória, CPU e armazenamento, memória e armazenamento. Teste emparelhado nos permite obter uma cobertura completa das combinações de cada duas variáveis, com um número mínimo de testes.
Teste emparelhado não só nos dá uma cobertura completa de todos os pares de valores, mas também nos dá cobertura (redundante) de cada valor único para cada controle.
Se olharmos para trás em nossos exemplos anteriores de configuração de laptop, podemos calcular o número de testes necessários para obter uma cobertura completa de pares. Para o configurador do laptop de nível de entrada, existem 32.256 possíveis combinações únicas de entradas. Podemos testar cada combinação única de duas variáveis com 31 testes. Para o configurador de laptop high-end, existem 2.322.432 combinações únicas de entradas. Podemos testar cada combinação única de duas variáveis com 36 testes.
***
Na segunda e última parte, o autor vai abordar o teste N-wise, juntamente com sua importância e otimização.
***
Scott Sehlhorst faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://www.developerdotstar.com/mag/articles/test_smarter_not_harder.html
É gerente de produto e consultor de estratégia que tem atuado na área de alta tecnologia desde 1997 - primeiro como um programador, depois como analista, e por fim como fundador da Tyner Blain, em 2005. Tem ajudado empresas desde startups até as de grande porte em todo o mundo com atividades como o lançamento de uma plataforma móvel até sistemas globais de comércio eletrônico. Scott muitas vezes ajuda as empresas a evoluir à medida que suas equipes de desenvolvimento se tornam ágeis. Está sempre auxiliando as empresas a descobrirem e definirem os produtos certos para seus mercados e estratégias. Antes de entrar no mundo do software, Scott era um engenheiro de projeto eletromecânico, com um BSME da Carnegie Mellon University, em Pittsburgh, EUA.



