

Este artigo é baseado na palestra “Chaves Primárias versus Índices Cluster?” que apresentei no 7Masters de Bancos de Dados em março/2012.
Introdução
Os desenvolvedores que têm mais experiência com SQL Server sabem que ele possui uma característica importante e ao mesmo tempo controversa: por default, o SGBD assume que a(s) coluna(s) que forma(m) a chave primária de uma tabela (que chamarei de PK daqui por diante) é também usada para definir seu índice clusterizado (que vou chamar de IC por simplificação).
Em outras palavras, se o arquiteto do banco de dados não definir detalhes ao criar a PK da tabela, ele está automaticamente estará criando também um IC sobre a(s) mesma(s) coluna(s).
Esse vínculo entre PK e IC é bastante nebuloso, porque a Microsoft não apresenta nenhuma justificativa formal que explique esse comportamento.
Neste artigo, eu comento alguns aspectos e conceitos envolvidos e apresento alguns prós e contras sobre sua existência.
Chave Primária (PK)
A definição de modelagem relacional, por si só, não especifica o que chamamos de PK. Apenas exige que exista ao menos um identificador de registros em cada tabela.
Em última análise, as PKs são uma abstração dos SGBDs que facilitam a implementação do modelo da base de dados. Elas formalizam quem é o identificador principal de cada tabela. E, junto com as chaves estrangeiras, permitem a definição de relações entre as tabelas de um banco de dados.
Observe que o uso de PKs e chaves estrangeiras não é obrigatório nos bancos de dados relacionais, mas elas facilitam muito a visualização do relacionamento entre tabelas e garantem integridade dos dados.
Por exemplo: uma tabela pode conter diversos identificadores de registros, sejam eles naturais ou artificiais (campos IDENTITY ou SEQUENCE, por exemplo). Cada um desses identificadores é chamado de chave candidata: um nome, um CPF, um campo IDENTITY com o código do cliente.
Tecnicamente, nada impede que eu use qualquer um desses identificadores para estabelecer (informalmente) uma relação entre duas tabelas. Poderia até mesmo usar identificadores diferentes em cada uma das relações que a tabela tem com as demais tabelas. Porém, isso ficaria muito confuso num modelo de dados mais complexo. Além disso, poderia causar problemas de normalização da base, caso eu escolhesse repetir o nome do cliente na tabela de pedidos, por exemplo.
Definindo uma PK, eu me obrigo a usar o mesmo identificador em todas as relações da tabela pai com as tabelas que dependem dela. Posso inclusive formalizar essas relações, definindo também chaves estrangeiras nessas tabelas dependentes. Com isso, eu tenho um modelo de dados muito mais claro, além de ser normalizado conforme a minha necessidade.
Índice clusterizado (IC)
Todo mundo sabe que só se tem boa performance nas consultas a dados se tivermos bons índices para usar.
Os bancos de dados atuais normalmente trabalham com índices do tipo B-tree. A estrutura desses índices representa uma árvore de decisão que, partindo de uma página inicial com informações sumarizadas (chamada “raiz”), indica para que grupo de “páginas intermediárias” a pesquisa deve seguir até que se encontre a página de destino (chamada “folha”). Veja a Figura 01.
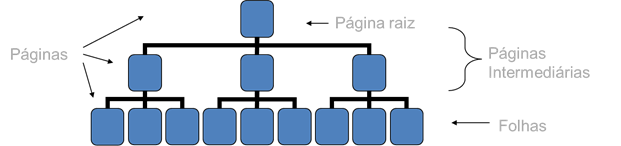
Ok. Então, pensando bem, se as tabelas precisam de índices e estes costumam usar uma estrutura física do tipo B-tree, seria uma boa ideia se eu já gravasse meus dados de uma forma que, fisicamente, a própria tabela tivesse uma estrutura B-tree. Certo?
Pois é. Bem-vindo à ideia do IC! As páginas do nível folha do IC são, ao final de contas, as próprias páginas de dados da tabela.
Todos os índices adicionais que forem criados nessa tabela (os índices não-clusterizados) são definidos a partir do nível folha do IC. Veja Figura 02.
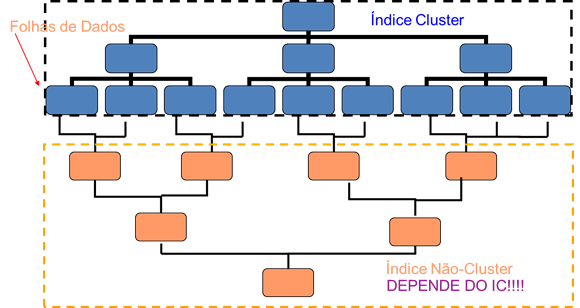
Uma característica fundamental dos índices clusterizados é que sua estrutura B-tree acaba forçando o SGBD a gravar os registros em página de dados específicas, a fim de manter a ordenação do(s) campo(s) que define(m) esse índice.
Por que vincular PK e IC?
PK é um conceito lógico que se destina a melhorar a implementação do modelo do banco de dados. IC é um conceito físico e é voltado para organizar as páginas de dados de uma tabela. Nenhum desses dois conceitos precisa ser obrigatoriamente implementado no seu banco de dados. Mas ambos fazem parte das melhores práticas de criação de bancos de dados.
Como eu disse anteriormente, quando o arquiteto do banco define a criação de a PK da tabela, automaticamente será criado um IC. Veja por exemplo a instrução a seguir.
ALTER TABLE XXX ADD CONSTRAINT PKXXX PRIMARY KEY (CAMPO);
Não há nada que especifique qualquer informação sobre o IC. Mas ele será criado. Você pode verificar isso usando a seguinte consulta:
select name, type_desc from sys.indexes where object_name(object_id) = 'XXX';
Esse é o vínculo entre PKs e ICs. É verdade que existem algumas semelhanças entre os dois conceitos, o que de certo modo poderia justificar a existência desse vínculo. Por exemplo:
- Tanto a PK como o IC precisam ser definidos sobre campo(s) que seja(m) identificador(es);
- Por conveniência, recomenda-se que os campos escolhidos tenham o menor tamanho possível; isso é bom para a PK porque facilita a implementação das chaves estrangeiras; e também é bom para o IC por facilitar a pesquisa de um campo tamanho reduzido;
- Também se recomenda que os campos escolhidos nunca sejam alterados; isso é importante para a PK para evitar problemas com a replicação da mudança nas chaves estrangeiras; e é importante para o IC para evitar que o registro precise ser reescrito em outra página de dados, o que poderia causar impacto importante em páginas de dados que estivessem cheias.
Por outro lado, existem diferenças fundamentais entre os campos que são indicados para serem PKs e os que são indicados para serem ICs. Por exemplo: um campo IDENTITY ou SEQUENCE é um ótimo candidato para PK. Ele geralmente é um número inteiro, pequeno, que nunca é alterado.
Porém, raramente o campo IDENTITY ou SEQUENCE é um bom candidato para IC. Primeiro porque ele não tem nenhum vínculo com o mundo real e raramente alguém fará uma pesquisa sobre um campo desses. Consequentemente, ICs “ruins” obrigarão o DBA a criar mais índices não-clusterizados para tentar minimizar as operações de “INDEX SCAN”.
Aí voltamos à pergunta original. Então por que vincular PKs e ICs?
Parece que a Microsoft força esse vínculo porque é muito importante que exista um IC na tabela, especialmente quando tratamos de tabelas grandes (milhões de registros). Mas são poucos os arquitetos que se dão ao trabalho de planejar a criação de o IC da tabela.
A criação de PKs é muito mais comum. Sendo assim, acho que a ideia da Microsoft é a de que mais vale uma tabela com IC ruim do que trabalhar com pilhas de páginas de dados (ou heaps, se preferir o nome em inglês).
Minha opinião é que o vínculo entre PKs e ICs é útil para o banco de dados. Eu entendo que toda tabela física deve ter uma PK, independentemente do tamanho que tenha. E toda tabela média ou grande (a partir de 1.000 registros) precisa de um IC.
Desse modo, garantimos que toda tabela no SQL Server terá um IC, caso ela tenha uma PK (a menos que o arquiteto diga o contrário). Em situações normais, isso ajuda na boa performance do banco de dados.
Mas temos que ter em mente que esse vínculo é útil, mas não é ótimo. Isso quer dizer que nem sempre o campo usado na PK é a melhor opção para definição de um IC.
Quando se trabalha com tabelas muitos grandes e/ou casos em que a performance é fator crítico, deve ser feito um estudo de otimização para identificar qual é o melhor campo para criação do IC. E então serão definidos separadamente o IC e depois uma PK não-clusterizada (e, nesse caso, é obrigatório usar essa palavra reservada na criação da PK).
De qualquer modo, o arquiteto do banco e o DBA devem estar atentos à PK e o IC de cada tabela. E conhecendo as vantagens e desvantagens das PKs vinculadas a ICs, fica mais fácil otimizar a performance do seu banco de dados.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?