



Estudo de caso da Uber: escolhendo o formato de arquivo HDFS correto para seus trabalhos do Apache Spark
Neste artigo, Scott Short, da Uber Engineering, apresenta o processo de escolha do formato de arquivo HDFS correto para os trabalhos do Apache Spark na Uber.


Como parte de nossos esforços para criar melhores experiências de usuário em nossa plataforma, os membros de nossa equipe de Coleta de Dados do Mapa usam um aplicativo móvel dedicado para coletar imagens e seus metadados associados para aprimorar nossos mapas.
Por exemplo, nossa equipe captura imagens de placas de rua para melhorar a eficiência e a qualidade de nossos dados de mapas, a fim de facilitar uma experiência de viagem mais tranquila para os passageiros e os motoristas parceiros, bem como tirar fotos de itens alimentares para ser exibido dentro do aplicativo Uber Eats.
Em seguida, processamos imagens e metadados por meio de uma série de trabalhos do Apache Spark e armazenamos os resultados em nossa instância do Hadoop Distributed File System/Sistema de arquivos distribuídos do Hadoop (HDFS).
Um dos maiores projetos da equipe da Coleta de Dados do Mapa exigiu a ingestão e o processamento de mais de oito bilhões de imagens.
As imagens precisavam ser acessadas com eficiência pelos trabalhos do Apache Spark de downstream, bem como acessados aleatoriamente pelos operadores responsáveis pelas edições de mapas.
Embora as escolhas de design feitas para nossa arquitetura Apache Spark tenham exigido que lidássemos com bilhões de imagens, o padrão resultante também foi aplicado a projetos com uma escala significativamente menor de milhares de imagens.
O Apache Spark suporta vários formatos de arquivo que permitem que vários registros sejam armazenados em um único arquivo. Cada formato de arquivo tem suas próprias vantagens e desvantagens.
Neste artigo, descrevemos os formatos de arquivo que a equipe de Coleta de Dados do Mapa usa para processar grandes volumes de imagens e metadados a fim de otimizar a experiência dos consumidores de downstream. Esperamos que você ache essas dicas úteis para suas próprias necessidades de análise de dados.
Usando o Apache Spark com o HDFS
Imagens e metadados são coletados com um aplicativo móvel dedicado desenvolvido pela Uber. Depois que os dados são capturados, o aplicativo móvel faz o upload dos dados para o armazenamento em nuvem. As imagens e os metadados são ingeridos do armazenamento em nuvem nos centros de dados da Uber e, em seguida, são processados:
- 1. Ingerir: Organiza os dados brutos no centro de dados para que possam ser processados em paralelo.
- 2. Processar/transformar: Uma série de etapas que descompacta os dados brutos e executa o processamento para refinar os dados em informações úteis para os consumidores de downstream.
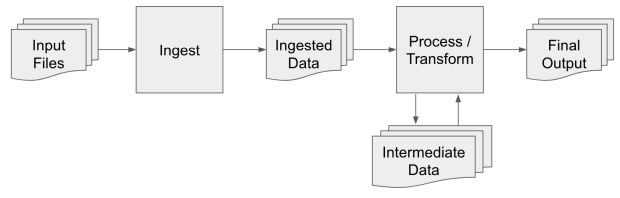
Os seguintes formatos de arquivo são usados para cada tipo de saída/resultado:
- Dados ingeridos: SequenceFiles fornece gravações eficientes para dados de blob.
- Dados intermediários: Avro oferece suporte a esquemas avançados e gravações mais eficientes do que o Parquet, especialmente para dados de blob.
- Saída/Resultado final: Combinação de arquivos Parquet, Avro e JSON
- Metadados de imagens: Parquet é otimizado para consultas e filtragem eficientes.
- Imagens: Avro é melhor otimizado para dados binários do que o Parquet e suporta acesso aleatório para junções eficientes.
- Metadados agregados: JSON é eficiente para pequenas contagens de registros distribuídas em um grande número de arquivos e é mais fácil de depurar que os formatos de arquivos binários.
Cada formato de arquivo tem vantagens e desvantagens e cada tipo de saída/resultado precisa suportar um conjunto exclusivo de casos de uso.
Para cada tipo de saída/resultado, escolhemos o formato de arquivo que maximiza as vantagens e minimiza as desvantagens.
Nas seções a seguir, explicamos porque cada formato de arquivo foi escolhido para cada tipo de formato.
Dados ingeridos
Ingestão é o processo pelo qual os dados gravados por um aplicativo de celular desenvolvido pela Uber são movidos com eficiência para o centro de dados para processamento posterior.
A ingestão lê de uma fonte externa e grava os dados no HDFS para que os arquivos possam ser processados com eficiência por meio dos trabalhos do Spark.
O armazenamento de um pequeno número de arquivos grandes é preferível a um grande número de arquivos pequenos no HDFS, pois consome menos recursos de memória no NameNodes e aumenta a eficiência dos trabalhos do Spark responsáveis pelo processamento dos arquivos.
Se você estiver interessado em aprender mais sobre este artigo, recomendamos verificar este artigo no Blog Cloudera Engineering.
Durante a ingestão, o conteúdo dos arquivos não é alterado, de modo que o processamento e as transformações adicionais podem ser feitos em paralelo por meio do Spark.
Os trabalhos do Spark, que são responsáveis pelo processamento e pelas transformações, leem os dados em sua totalidade e fazem pouca ou nenhuma filtragem.
Portanto, um formato de arquivo simples é usado para fornecer um ótimo desempenho de gravação e não possui a sobrecarga de formatos de arquivo centrados em esquema, como Apache Avro e Apache Parquet.
Cada instância de processamento grava os arquivos em um único SequenceFile do HDFS, resultando em alguns arquivos grandes que são ideais para o HDFS. Um SequenceFile é um arquivo simples que consiste em pares de chave/valor binários.
A API permite que os dados sejam armazenados em uma chave binária ou em outro tipo de dados, como string ou inteiro.
No caso de ingestão, a chave é uma cadeia que contém o caminho completo para o arquivo e o valor é uma matriz binária que contém o conteúdo do arquivo ingerido.
Dados intermediários
Depois que os dados são ingeridos, uma série de trabalhos do Spark transforma e executa processamento adicional nos dados. Cada trabalho do Spark dentro da série grava dados intermediários.
Os dados intermediários gerados por uma tarefa anterior são geralmente lidos na sua totalidade e são filtrados por colunas ou linhas. Para este tipo de dados intermediários, geralmente usamos o formato de arquivo Avro.
O formato de arquivo padrão do Spark é Parquet. Parquet tem várias vantagens que melhoram o desempenho de consultar e filtrar os dados. No entanto, essas vantagens vêm com um custo inicial quando os arquivos são gravados.
Parquet é um formato de arquivo baseado em colunas, o que significa que todos os valores de uma determinada coluna em todas as linhas armazenadas em um arquivo físico (também conhecido como um bloco) são agrupados antes de serem gravados no disco.
Assim, todos os registros precisam ser armazenados e rearranjados na memória antes que o bloco seja gravado.
Por outro lado, um arquivo Avro é um formato de arquivo baseado em registro que permite que os registros sejam transmitidos com mais eficiência para o disco.
O web site do Parquet tem uma série de apresentações gravadas que fornecem explicações mais abrangentes dos formatos de arquivo baseados em colunas.
Devido à menor sobrecarga de gravação, os arquivos Avro geralmente são usados para armazenar dados intermediários quando:
- Os dados são gravados uma vez e lidos uma vez.
- O leitor não filtra os dados.
- O leitor lê os dados sequencialmente.
Resultado/saída final
A saída final é os dados processados e é acessada por vários consumidores downstream. Cada consumidor possui requisitos exclusivos que são frequentemente abordados consultando e filtrando os dados.
Por exemplo, um consumidor pode executar uma consulta geoespacial em imagens de um tipo específico. O resultado/saída final cai em três categorias:
- 1. Metadados de imagens: Dados sobre as imagens, como o local no qual foram tiradas.
- 2. Imagens: As imagens capturadas pelo sensor.
- 3. Dados agregados: Dados de alto nível sobre um conjunto de imagens, como a versão do software usado para processar as imagens ou as métricas agregadas sobre os dados de saída.
Metadados de imagens
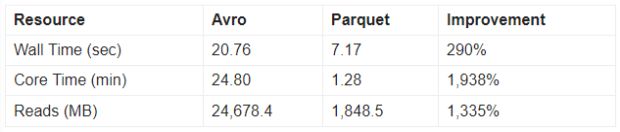
Ao contrário dos dados intermediários, os metadados de imagens são lidos várias vezes e geralmente filtrados e consultados. Os dados são armazenados no Parquet porque os benefícios superam significativamente a sobrecarga adicional de gravação. Abaixo estão os resultados de dois testes de desempenho que consultaram aproximadamente cinco milhões de registros.
A primeira consulta é uma consulta de caixa delimitadora simples na latitude e longitude das imagens que retorna aproximadamente 250.000 registros. Do ponto de vista do consumidor downstream, a consulta Parquet é quase três vezes mais rápida de executar. No entanto, o impacto real está na infraestrutura subjacente.
A maior melhoria é a I/O necessária para as consultas em que o Parquet consome 7,5% da I/O exigida pela consulta Avro. O formato de arquivo Parquet armazena estatísticas que reduzem significativamente a quantidade de dados lidos.
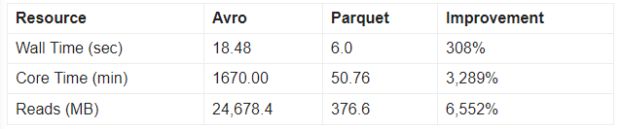
A segunda consulta é uma comparação de string/sequência de caracteres que retorna aproximadamente 40.000 registros. Mais uma vez, a consulta contra arquivos Parquet teve um desempenho significativamente melhor do que com arquivos Avro. A consulta do Parquet é executada duas vezes mais rápido e requer 1,5% da I/O versus a consulta equivalente do Avro.
Imagens
O parquet não é ideal para armazenar dados binários grandes, como imagens, pois é um processo que consome muitos recursos para organizar grandes dados binários em um formato colunar. Por outro lado, o Avro funciona muito bem para armazenar imagens. Conforme discutido na seção anterior, no entanto, o Avro não é ideal para consultas.
Para dar suporte a consultas, duas colunas são adicionadas aos arquivos Parquet de metadados de imagens para servir como uma chave estrangeira para as imagens. Isso permite que os clientes consultem as imagens por meio dos metadados.
Dois detalhes importantes precisam ser abordados para entender como a referência cruzada é implementada:
- Part File/Arquivo de peça: o Spark subdivide os dados em partições e, quando os dados são gravados no Avro, cada partição é gravada em um arquivo de peça separado.
- Deslocamento de Registro: a API do Avro suporta a capacidade de obter o deslocamento em um arquivo no qual um registro específico é armazenado. Dado um deslocamento, a API do Avro pode buscar eficientemente o local do arquivo e ler o registro. Essa funcionalidade está disponível por meio da API do Avro nativa e não por meio da API do wrapper do Spark para o Avro.
As duas colunas anexadas aos metadados de imagens usados como referência cruzada para as imagens são o nome do arquivo de peça no qual o registro de imagem é armazenado e o deslocamento do arquivo do registro dentro do arquivo de peça.
Como a API do wrapper/invólucro do Spark para arquivos Avro não expõe o deslocamento do registro, a API do Avro nativa deve ser usada para gravar as imagens.
As imagens são gravadas em um mapa do Spark. A implementação irá variar dependendo da versão do Spark e se o DataFrame ou APIs do Conjunto de Dados Distribuído Resiliente são usados, mas o conceito é o mesmo.
Execute um método em cada partição por meio de uma chamada do mapa do Spark e use a API do Avro nativa para gravar um arquivo de peça individual que contenha todas as imagens contidas na partição. Os passos gerais são os seguintes:
- 1. Leia o SequenceFile de ingestão
- 2. Mapeie cada partição do SequenceFile de ingestão e passe o ID da partição para a função do mapa. Para um RDD, chame rdd.mapPartitionsWithIndex(). Para um DataFrame, você pode obter o ID da partição via spark_partition_id(), agrupar por ID de partição via df.groupByKey() e, em seguida, chamar df.flatMapGroups().
3. Dentro da função do mapa, faça o seguinte:
- a) Crie um Avro Writer padrão (não o Spark) e inclua o ID da partição no nome do arquivo.
- b) Itere por meio de cada registro do SequenceFile de ingestão e grave registros no arquivo Avro.
- c) Chame o DataFileWriter.sync() dentro da API do Avro. Isso irá liberar o registro para o disco e retornar o deslocamento do registro.
- d) Passe o nome do arquivo e o deslocamento de registro por meio do valor de retorno da função de mapa junto com quaisquer metadados adicionais que você gostaria de extrair das imagens.
4. Salve o formato DataFrame ou RDD no Parquet resultante.
Os resultados são um Avro e um arquivo Parquet complementar. O arquivo Avro contém as imagens e o arquivo Parquet complementar contém o caminho do arquivo Avro e o deslocamento de registro para executar com eficiência uma busca no arquivo Avro para um determinado registro de imagem. O padrão geral para consultar e ler os registros de imagens é:
- 1. Consulte os arquivos Parquet.
- 2. Inclua o caminho do arquivo e o deslocamento nos resultados.
- 3. Opcionalmente, reparticione os resultados para ajustar o grau de paralelismo para a leitura dos registros de imagem.
- 4. Mapeie cada partição dos resultados da consulta.
- 5. Dentro da função do mapa, faça o seguinte:
1. Crie um leitor Avro padrão para o arquivo de peça Avro que contém o registro de imagem.
2. Chame DataFileReader.seek(long) para ler o registro de imagem no deslocamento especificado.
Dados agregados
Além dos metadados para uma determinada imagem, é útil para nós armazenar metadados agregados sobre todo o conjunto de imagens armazenadas em um determinado par de arquivos do Avro e do Parquet. Para o caso de uso da Uber, exemplos de metadados agregados incluem os dois:
A versão do pipeline usada para processar um determinado conjunto de imagens. Se um bug for encontrado no pipeline, esses dados serão usados para identificar com eficiência as imagens que precisam ser reprocessadas.
A área geográfica na qual as imagens foram coletadas. Isso permite que os clientes identifiquem quais pares de arquivos Avro e Parquet incluem nas pesquisas geoespaciais.
Os dados agregados são armazenados em arquivos JSON pelos seguintes motivos:
- 1. Capacidade de Depuração: Como os arquivos JSON são formatados em texto e geralmente contêm um pequeno número de registros, eles podem ser facilmente exibidos sem código ou ferramentas especiais.
- 2. Leituras “Eficientes o Suficiente”: Em muitos casos, o arquivo JSON conterá um único registro para um par de Avro e Parquet. Tanto o Parquet quanto o Avro têm sobrecarga porque os dois formatos de arquivo contêm informações de cabeçalho. O JSON não tem essa sobrecarga devido à falta de informações de cabeçalho dos formatos.
- 3. Integridade referencial: Uma alternativa seria armazenar os registros agregados em um banco de dados. No entanto, se os arquivos JSON, Avro e Parquet de um determinado conjunto de imagens forem armazenados em um único diretório pai, então as imagens, os metadados de imagens e os metadados agregados poderão ser arquivados movendo o diretório pai com uma única operação HDFS atômica.
Principais tópicos
O formato de arquivo padrão do Spark é Parquet, mas, como discutimos acima, há casos de uso em que outros formatos são mais adequados, incluindo:
- SequenceFiles: Par de chave /valor binário que é uma boa escolha para armazenamento de blob quando a sobrecarga do suporte a esquema rico não é necessária
- Parquet: Suporta consultas eficientes, esquemas fortemente digitados e tem vários outros benefícios não abordados neste artigo.
- Avro: Ideal para grandes dados binários ou quando os consumidores downstream leem registros em sua totalidade e também suporta acesso aleatório a buscas aos registros. Fornece a capacidade de definir um esquema fortemente digitado.
- JSON: Ideal quando os registros são armazenados em vários arquivos pequenos
Ao escolher o formato de arquivo ideal do HDFS para seus trabalhos do Spark, você pode garantir que eles utilizem com eficiência os recursos do centro de dados e atendam melhor às necessidades dos consumidores downstream.
Se você trabalhar em desafios de processamento de dados em grande escala ou tecnologias de visão computacional te interessa, considere a possibilidade de se candidatar a um cargo em nossa equipe.
***
Este artigo é do Uber Engineering. Ele foi escrito por Scott Short. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/hdfs-file-format-apache-spark/



