

Recentemente li um artigo muito interessante e didático publicado por Simon Liew no site SQL Server Central com o título “How efficient is your covered index?”.
O autor mostra um exemplo onde um índice com várias colunas não se comporta da forma esperada, o que afeta sua eficiência. Isso ocorre porque o uso dos índices varia de acordo com ‘n’ fatores, tais como a forma como se escreve as consultas, a estruturas de índices e de tabelas, etc.
Por exemplo, quando se usa critérios de pesquisa com funções (ISNULL, DATEADD, etc) ou operadores especiais (LIKE..), o otimizador de consultas não consegue usar os índices. Costuma-se classificar estes critérios de “SARGable” ou “non-SARGable”, conforme eles permitam ou não o uso dos índices. SARG é uma abreviatura pra Search Argument, que, neste caso, se refere a “argumento de pesquisa” de índices; eu não encontrei uma tradução adequada para este termo, por isso uso a palavra em inglês.
Exemplo:
- WHERE date >= ’01-01-2012′ AND date < ’01-01-2013′ permite uso de indices (SARGable)
- WHERE Year(date) = 2012 usa uma função e é non-SARGable
(Para mais informações sobre critérios SARGable, clique aqui).
Eu pretendo estender este estudo com algumas adaptações, mas recomendo ao leitor que antes leia o artigo original (clique aqui).
No meu ambiente eu uso o SQL Server 2008 R2, que é atualmente a versão padrão usada na empresa onde trabalho. E base demo ADVENTUREWORKS, que uso aqui também, é idêntica à original.
Meus testes visam observar a influência e a interação de três fatores:
- estrutura da tabela, com campos que aceitam nulos (1) ou não (2);
- sequência de campos do índice: original (A) ou com campo nulo na última posição(B);
- critério da consulta SARGable (SARG) ou non-SARGable (NSARG).
Os links para os scripts destes objetos são mostrados a seguir:
- Tabela 1
- Tabela 2
- Índice A
- Índice B
- Consulta NSARG
- Consulta SARG
Clique aqui para fazer o download dos arquivos zipados.
Com base nestas definições, os testes são feitos para oito cenários:
- Tabela 1 com Índice A e Consulta NSARG, configuração idêntica à usada no artigo do Simon Liew;
- Tabela 1 com Índice A e Consulta SARG;
- Tabela 1 com Índice B e Consulta NSARG;
- Tabela 1 com Índice B e Consulta SARG;
- Tabela 2 com Índice A e Consulta NSARG;
- Tabela 2 com Índice A e Consulta SARG;
- Tabela 2 com Índice B e Consulta NSARG;
- Tabela 2 com Índice B e Consulta SARG.
A opção por tabelas físicas, em teoria, não influencia os resultados dos testes.
OBS: neste mundo dos SGBDs, é preciso sempre ter cuidado com as afirmações que fazemos J.
A ideia é consultar os planos de execução das consultas, avaliando o Custo Total de Execução e se a pesquisa dos índices (Index Seek) usa todos os critérios de pesquisa.
Vamos aos resultados:
|
Cenário |
Custo Total de Execução |
Diferença sobre Mínimo % |
Plano de Execução |
Pesquisa Todos Critérios |
|
1 |
0,0034007 |
3,6% |
./cenario1.png |
não |
|
2 |
0,0032836 |
0,0% |
./cenario2.png |
sim |
|
3 |
0,0032870 |
0,1% |
./cenario3.png |
não |
|
4 |
0,0032836 |
0,0% |
./cenario4.png |
sim |
|
5 |
0,0034007 |
3,6% |
./cenario5.png |
não |
|
6 |
0,0032836 |
0,0% |
./cenario6.png |
sim |
|
7 |
0,0032870 |
0,1% |
./cenario7.png |
não |
|
8 |
0,0032836 |
0,0% |
./cenario8.png |
sim |
{kind=link}
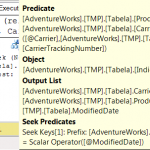
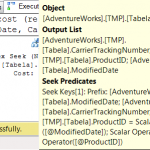

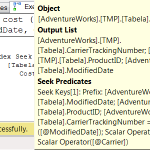
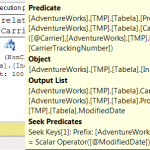
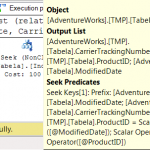

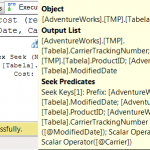
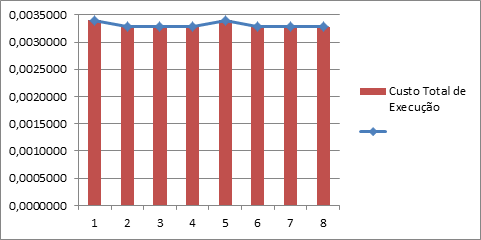
A primeira coisa que se observa é que o custo total é praticamente o mesmo em todos os cenários (variação de apenas 3,6%). Mas isso não é surpresa, já que todos os cenários envolvem consulta com o uso de índices.
(Por curiosidade, eu fiz um teste rodando consultas sem índice algum e o custo total dispara: sobe para 0,871546, ou seja, mais que 250 vezes maior do que o custo de qualquer outro cenário).
A segunda coisa que chama a atenção é que os testes com mudança de estrutura da tabela (usando campo CarrierTrackingNumber como NULL ou NOT NULL) não teve nenhum efeito nos resultados. Todos os testes dão exatamente o mesmo resultado (veja os cenários 1 e 5, 2 e 6, 3 e 7, 4 e 8). Portanto alterar definição de campos não é um fator que possa ajudar significativamente na otimização do uso de índices.
Já a influência da mudança da sequência dos campos do índice tem impacto, mas apenas nos testes que usam consultas non-SARGable. Pode-se notar isso comparando os testes 1 e 3, 2 e 4, 5 e 7 e 6 e 8. Veja que os testes 2, 4, 6 e 8 tiveram exatamente o mesmo o custo de execução das consultas.
Finalmente, chegamos aos critérios de consulta (SARGable e non-SARGable). Este parece ser o fator de maior impacto. Veja os testes 1 e 2, 3 e 4, 5 e 6, 7 e 8. Em todos os casos, houve redução do custo total de execução das consultas, mesmo que a diferença fosse pequena. A diferença quando usamos o índice original chegou a 3,6% e apenas 0,1% para o índice com nova sequência.
O fato é que este rápido estudo nos dá algumas dicas sobre o que podemos fazer para otimizar o uso de um índice:
- Mudar a definição de campos em relação aos valores nulos provavelmente terá pouco ou nenhum impacto;
- Redefinir a sequência de campos do seu índice pode ajudar em algumas situações, mas provavelmente não será efetiva se for uma ação isolada;
- Escrever consultas SQL que usem apenas critérios SARGable parece ser a alternativa que tem melhor resultado quando aplicada isoladamente. Mas os resultados tendem a ser melhores quando usada em conjunto com outras ações.
É difícil extrapolar os resultados deste teste e dizer que eles se aplicam a qualquer cenário. Na realidade, eu não conheço nenhuma bala de prata para ser usada na área de bancos de dados, se é que existe alguma.
É importante destacar também que os três fatores estudados neste artigo não são os únicos possíveis. Mas estes resultados, por mais limitados que sejam, mostram uma tendência que eu acredito que todo mundo previa: o cenário de melhor performance considera uma combinação de fatores. Em outras palavras, a ação de melhor resultado é, na verdade, uma combinação de ações.
Mesmo mostrando um resultado de aplicação limitada, acho que o ponto fundamental deste artigo é mostrar para o leitor um método simples e rápido de definir e testar os cenários que pareçam viáveis para solução de um problema de otimização.
Por hoje é só. Até a próxima!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?