

Para facilitar a melhor experiência de ponta a ponta possível para os usuários, a Uber compromete-se a tornar o suporte ao cliente mais fácil e acessível. Trabalhando em direção a esse objetivo, a equipe de Obsessão do Cliente da Uber alavanca cinco canais diferentes de comunicação cliente-agente, impulsionados por uma plataforma interna que integra o contexto do ticket de suporte ao cliente para facilitar a resolução de problemas.
Com centenas de milhares de tickets que aparecem diariamente na plataforma em mais de 400 cidades em todo o mundo, essa equipe deve garantir que os agentes estejam empoderados para resolvê-los com a maior precisão e rapidez possível.
Acesse COTA, nosso Assistente do Ticket de Obsessão do Cliente, uma ferramenta que usa técnicas de aprendizado de máquina e processamento de linguagem natural (NLP) para ajudar os agentes a oferecer melhor atendimento ao cliente. Aproveitando a nossa plataforma de aprendizagem de máquina-como-serviço, Michelangelo, no topo da nossa plataforma de suporte ao cliente, COTA permite a resolução de problemas de forma rápida e eficiente para mais de 90% dos nossos tickets de suporte de entrada.
Neste artigo, discutimos nossas motivações por trás da criação de COTA, descrevemos a sua arquitetura de backend e mostramos como a poderosa ferramenta levou a uma maior satisfação do cliente.
Suporte ao cliente antes de COTA
Quando os clientes contatam a Uber para obter suporte, é importante que os direcionemos para a melhor resolução possível em tempo hábil. Uma maneira de facilitar isso é fazer com que os usuários cliquem sobre uma hierarquia de tipos de problemas quando eles relatam um problema; isso fornece aos nossos agentes um contexto adicional em torno do problema, permitindo-lhes assim, resolvê-lo mais rapidamente, conforme detalhado na Figura 1 abaixo:
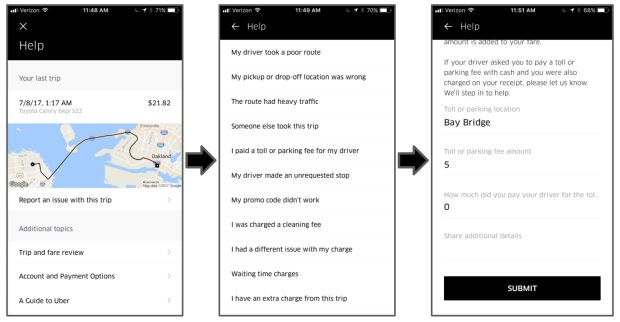
Embora isso forneça contextos importantes, nem todas as informações necessárias para solucionar um problema podem ser obtidas através deste processo, especialmente devido à grande variedade de possíveis soluções disponíveis. Além disso, a diversidade de maneiras pelas quais um cliente pode descrever um problema associado a um ticket complica ainda mais o processo de resolução do ticket.
Como a Uber continua a crescer em escala, os agentes de suporte devem ser capazes de lidar com um volume cada vez maior e diversidade de tickets de suporte, desde erros técnicos até ajustes de tarifas. Na verdade, quando um agente abre um ticket, a primeira coisa que eles precisam fazer é determinar o tipo de problema de milhares de possibilidades – nenhuma tarefa fácil! Reduzir a quantidade de tempo que os agentes gastam ao identificar os tickets é importante porque também diminui o tempo necessário para resolver problemas para os usuários.
Uma vez escolhido o tipo de problema, o próximo passo é identificar a resolução certa, com cada tipo de ticket possuindo um conjunto diferente de protocolos e soluções. Com milhares de resoluções possíveis para escolher, identificar a correção adequada para cada problema também é um processo que exige muito tempo.
Apresentando COTA: Assistente do Ticket de Obsessão do Cliente
Criamos COTA para ajudar nossos representantes de suporte ao cliente a melhorar sua velocidade e precisão, resultando em uma melhor experiência do cliente.
Em suma, COTA alavanca Michelangelo para simplificar, acelerar e padronizar o fluxo de trabalho de resolução de tickets. Embora a versão atual de COTA seja composta por um conjunto de modelos que recomendam soluções para agentes para tickets de suporte de língua inglesa, estamos no processo de construção de modelos que também processem tickets em espanhol e em língua portuguesa.
Construídos no topo de nossa plataforma de suporte, nossos modelos alimentados por Michelangelo sugerem os três tipos de problemas e de soluções mais prováveis, baseadas no conteúdo do ticket e no contexto da viagem, representados abaixo:
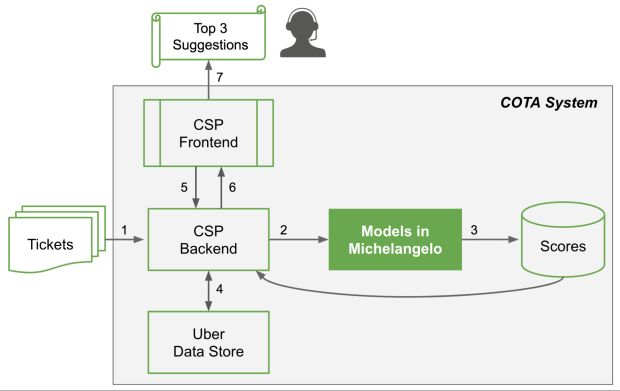
Conforme representado na Figura 2, a arquitetura COTA geral segue um fluxo de sete etapas:
- Uma vez que um novo ticket entra na plataforma de suporte ao cliente (CSP), o serviço back-end coleta todos os recursos relevantes do ticket.
- O serviço back-end, então, envia esses recursos ao modelo de aprendizado de máquina em Michelangelo.
- O modelo prediz pontuações para cada solução possível.
- O serviço back-end recebe as previsões e as pontuações, e as salva, então, em nosso armazenamento de dados Schemaless.
- Uma vez que um agente abre um determinado ticket, o serviço de front-end aciona o serviço de back-end para verificar se há atualizações para o ticket. Se não houver atualizações, o serviço de back-end irá recuperar as previsões salvas; se houver atualizações, ele buscará os recursos atualizados e passará as etapas 2-4 novamente.
- O serviço back-end retorna a lista de soluções classificadas pela pontuação prevista para o frontend.
- As três principais soluções classificadas são sugeridas aos agentes; a partir daí, os agentes fazem uma seleção e resolvem o ticket de suporte.
Os resultados são promissores; COTA pode reduzir o tempo de resolução de tickets em mais de 10%, ao mesmo tempo em que entrega serviços com níveis semelhantes ou superiores de satisfação do cliente, conforme medido por pesquisas de atendimento ao cliente. Ao capacitar os agentes de suporte ao cliente para entregar soluções mais rápidas e precisas, os poderosos modelos ML de COTA tornam a experiência de suporte Uber mais agradável.
Construindo o backend de COTA com NLP e ML
Olhando do lado de fora, COTA considera informações contextuais sobre questões de suporte e retorna soluções possíveis, mas há muito mais acontecendo nos bastidores. No seu núcleo, o backend de COTA é responsável por realizar duas tarefas: identificar o tipo de problema do ticket e determinar as soluções mais sensíveis para eles.
Para conseguir isso, nosso modelo de aprendizado de máquina alavanca recursos extraídos de mensagens de suporte ao cliente, informações de viagem e seleções de clientes na hierarquia de submissão de problema de ticket descrita anteriormente.
De acordo com as pontuações de importância do recurso geradas pelo nosso modelo (e sem surpresa), o recurso mais valioso para identificar o tipo de problema é a mensagem que os clientes enviam aos agentes sobre seu problema antes de enviar oficialmente seu ticket através da hierarquia. Uma vez que as mensagens enviadas pelos usuários são úteis para entender com qual problema estão lidando, construímos um pipeline PNL para transformar texto de várias linguagens diferentes em recursos úteis para os nossos modelos de machine learning posteriores.
Os modelos de NLP podem ser construídos para traduzir e interpretar diferentes elementos de texto, incluindo fonologia, morfologia, gramática, sintaxe e semântica. Dependendo das unidades de construção, a NLP também pode registrar modelos de linguagem em nível de personagem, palavra, frase ou sentença/documento. Os modelos tradicionais de NLP são construídos alavancando conhecimentos humanos em linguística para engenharia de recursos feitos a mão.
Com o recente surgimento do treinamento de ponta a ponta para modelos de aprendizado profundo, os pesquisadores começaram a desenvolver modelos que podem decifrar pedaços grandes de texto sem ter que analisar explicitamente as relações entre palavras diferentes dentro de uma sentença, em vez disso, usar diretamente um texto bruto.
Para o nosso caso de uso, decidimos primeiro criar um modelo NLP que analise o texto em nível de palavra para entender melhor a semântica de dados do texto. Uma abordagem popular da NLP é a modelagem de tópicos, que visa compreender o significado das sentenças usando as estatísticas de contagem das palavras. Embora a modelagem de tópicos não leve em consideração a ordenação das palavras, ele foi comprovado como muito poderoso para tarefas como recuperação de informações e classificação de documentos.
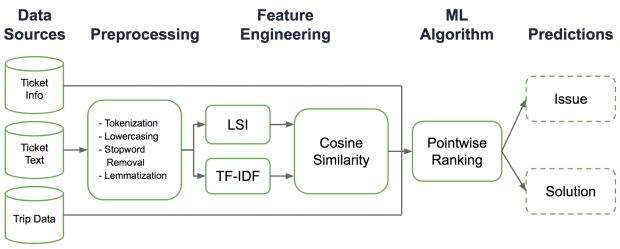
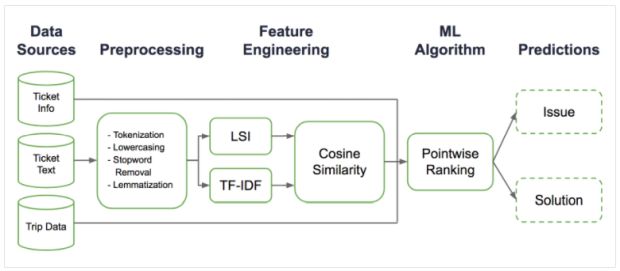
Em COTA, usamos o seguinte pipeline NLP baseado em modelagem de tópicos para lidar com mensagens de texto, conforme descrito na Figura 3.
Pré-processamento
Primeiro, limpamos o texto removendo as tags de HTML. Em seguida, tokenizamos as sentenças da mensagem e removemos as stopwords. E então realizamos a lemmatização para converter palavras em diferentes formas infletidas na mesma forma base. Finalmente, convertemos os documentos em uma coleção de palavras (chamada mala de palavras) e construímos um dicionário dessas palavras.
Modelagem de tópicos
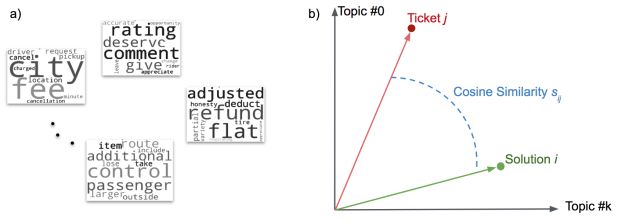
Para entender a intenção de nosso usuário, então, realizamos modelagem de tópicos na mala de palavras após o pré-processamento. Especificamente, usamos TF-IDF (frequência de documento frequência-inversa de termo) e LSA (análise semântica latente) para extrair tópicos. A Figura 4, abaixo, mostra alguns exemplos dos tipos de tópicos que podemos obter da modelagem de tópicos:
Engenharia de recursos
A modelagem de tópicos nos permite usar diretamente os vetores de tópicos como recursos para executar classificações a jusante para identificação de tipo de problema e seleção de solução. No entanto, essa abordagem direta sofre de uma escassez de vetores tópicos; para formar uma representação significativa desses tópicos, normalmente precisamos manter centenas ou mesmo milhares de dimensões de vetores tópicos com muitas dimensões com valores próximos de zero. Com um espaço de recursos de grande dimensão e uma grande quantidade de dados para processar, o treinamento desses modelos torna-se bastante desafiador.
Com essas considerações em mente, decidimos usar a modelagem de tópicos de forma indireta: realizando mais engenharia de recursos ao computar características de similaridade de cosseno, como ilustrado na Figura 4b. Usando a seleção da solução como exemplo, nós coletamos os tickets históricos de cada solução e formamos a representação da mala de palavra dessa solução.
Neste cenário, uma transformação de modelagem de tópicos é realizada na representação de mala de palavra, o que nos dá um vetor Ti para a solução i. Realizamos essa transformação em todas as nossas soluções. Podemos mapear qualquer novo ticket recebido, j, para o espaço vetorial do tópico da solução, T1, T2 … Tm, onde m é o número total de possíveis soluções a serem usadas.
Isso resulta em um vetor tj para o ticket j. A pontuação de similaridade de coseno sij pode ser calculada entre Ti e tj para representar a semelhança entre a solução i e o ticket j, o que reduz o espaço de recursos de centenas ou milhares de dimensões para um punhado.
Algoritmo de classificação em Pointwise
Novamente, ilustramos como nosso algoritmo ML funciona usando a seleção de solução como um exemplo. Para projetar este algoritmo, combinamos os recursos de similaridade de cosseno juntamente com outros recursos de ticket e viagem que combinam os tickets com as soluções. Com mais de 1.000 possíveis soluções para centenas de tipos de tickets, o grande espaço de soluções de COTA oferece um desafio para o nosso algoritmo de distinguir as boas diferenças entre essas soluções.
Para identificar as melhores recomendações possíveis para agentes de suporte, aplicamos uma abordagem de aprendizagem para classificação e criamos um algoritmo de classificação pointwise com base em recuperação. Especificamente, rotulamos a correspondência correta entre a solução e o par de tickets como positivo (1), e amostramos um subconjunto aleatório de soluções que não combinam com o ticket e rotulamos os pares como negativos (0).
Usando a semelhança de cosseno, bem como os recursos de ticket e viagem, podemos construir um algoritmo de classificação binária que alavanca a técnica da floresta aleatória para classificar se cada combinação solução-ticket corresponde. Uma vez que o algoritmo pontue cada possível correspondência, podemos classificar as pontuações e sugerir as três melhores soluções.
A Figura 5, a seguir, compara o desempenho de um algoritmo clássico de classificação multi-classe usando recursos de vetores de tópicos diretamente contra o algoritmo de classificação pointwise usando recursos de similaridade de cosseno projetados:
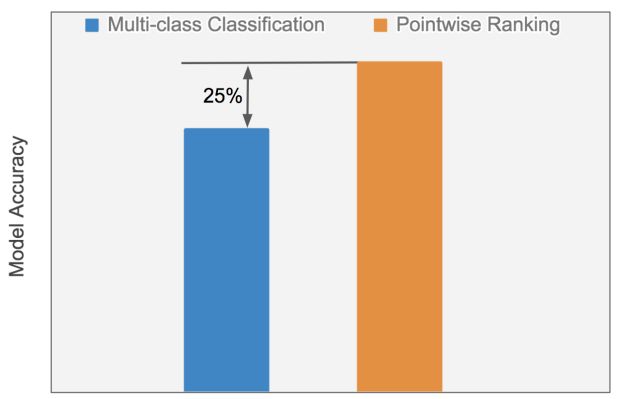
O algoritmo de classificação pointwise baseado em similaridade de cosseno supera o algoritmo de classificação multi-classe com vetores tópicos diretos, com uma melhoria relativa de 25% na precisão. Esta comparação, conduzida no mesmo conjunto de dados usando o mesmo tipo de algoritmo (floresta aleatória) com os mesmos hiper parâmetros, destaca o benefício de usar recursos de similaridade de cosseno de engenharia em uma estrutura de classificação. Como evidenciado na Figura 5, o uso do algoritmo de classificação pointwise não só acelera o processo de treinamento em 70%, mas também melhora significativamente o desempenho do modelo.
Solução de tickets mais fácil e rápida = melhor atendimento ao cliente
Os resultados promissores de COTA só foram significativos se eles se traduziram em uma configuração real. Para medir o impacto de COTA em nossa experiência de suporte ao cliente, realizamos várias experiências de teste A/B controladas online em tickets de língua inglesa. Nesses experimentos, incluímos milhares de agentes e os atribuímos aleatoriamente em grupos controle ou de tratamento.
Os agentes do grupo controle foram expostos ao fluxo de trabalho original, enquanto os agentes do grupo de tratamento apresentaram uma interface de usuário modificada, contendo sugestões sobre tipos e soluções de problemas. Nós colecionamos os tickets resolvidos unicamente por qualquer agente no grupo controle ou de tratamento, e medimos algumas métricas chave, incluindo precisão do modelo, tempo de manuseio médio e pontuação de satisfação do cliente.
O teste procedeu da seguinte forma:
Primeiro, medimos o desempenho do modelo online para ambos os grupos e os comparamos com o desempenho off-line. Descobrimos que o desempenho do modelo é consistente de offline para on-line.
Então, medimos as pontuações de satisfação do cliente e as comparamos em grupos controle e de tratamento. Em geral, descobrimos que a satisfação do cliente muitas vezes aumentou em alguns pontos percentuais. Esta descoberta indica que COTA oferece a mesma ou um pouco mais de qualidade de serviço ao cliente.
Finalmente, para determinar o quanto COTA afetou a velocidade da resolução de ticket, comparamos o tempo médio de manuseio de ticket entre os grupos controle e de tratamento. Determinamos que, em média, esse novo recurso reduziu o tempo de manuseio de tickets em cerca de 10%.
Ao melhorar o desempenho do agente e acelerar os tempos de resolução de ticket, COTA ajuda nossa equipe de Obsessão do Cliente a atender melhor nossos usuários, levando ao aumento da satisfação do cliente. Além disso, a capacidade de COTA para acelerar a resolução de ticket economiza para a Uber dezenas de milhões de dólares por ano.
Deep leraning para a próxima geração de COTA
O sucesso de COTA nos convenceu a continuar experimentando nossa pilha de machine learning para melhorar a precisão do sistema e proporcionar uma experiência ainda melhor para os agentes e usuários finais.
Os avanços recentes na classificação de texto, compactação, tradução automática e muitas tarefas de NLP auxiliares (análise sintática e semântica, reconhecimento de vinculação textual, reconhecimento de entidades intituladas e vinculação) foram obtidos utilizando arquiteturas de deep learning, por isso pareceu ser um ajuste natural para começar experimentando com eles para nossos próprios modelos.
Experiências de deep learning com várias arquiteturas
Com o apoio de pesquisadores da Uber AI Labs, experimentamos a aplicação de deep learning para a próxima geração de modelos para identificação de tipo de problema e sugestão de solução. Implementamos várias arquiteturas baseadas em redes neurais convolutivas (CNNs), redes neurais recorrentes (RNNs) e várias combinações diferentes dos dois, incluindo arquiteturas hierárquicas e baseadas em atenção.
Usando frameworks de deep learning, conseguimos treinar nossos modelos através de de aprendizagem multitarefa, com um único modelo capaz de identificar o tipo de problema e sugerir a melhor solução possível.
Uma vez que os tipos de problemas são organizados em uma hierarquia, determinamos que poderíamos treinar o modelo para prever o caminho na hierarquia com um decodificador recorrente usando busca de feixe, semelhante ao componente de decodificação de um modelo sequência para sequência e permitido para previsões ainda mais precisas.
Otimização do hiperparâmetro para selecionar o melhor modelo
Para adotar a melhor arquitetura de deep learning, realizamos otimização de hiper parâmetros em grande escala para todos os tipos de arquiteturas, treinando-as em paralelo em nosso cluster GPU. Os resultados finais sugerem que a arquitetura mais precisa é aquela que aplica tanto CNNs quanto RNNs, mas, com o objetivo de nossa pesquisa, decidimos buscar uma arquitetura CNN mais simples, que fosse um pouco menos precisa, mas que possuísse propriedades computacionais mais avançadas em termos de treinamento e tempo de inferência. No final, o modelo que estabelecemos fornece cerca de 10% mais precisão em relação ao modelo de floresta aleatória original.
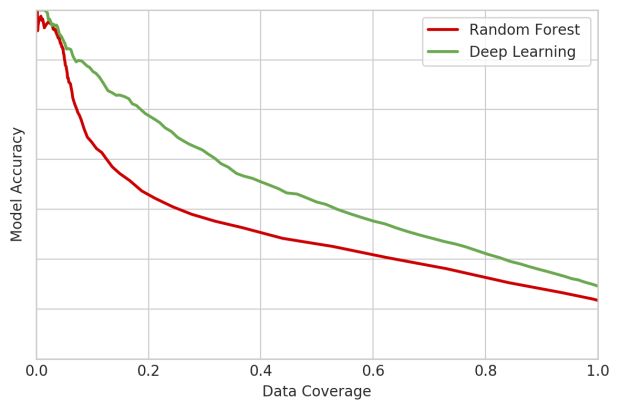
Na Figura 6, abaixo, mostramos o tradeoff entre a cobertura de dados (em outras palavras, a porcentagem de tickets que um modelo está processando, o eixo x) e a precisão (o eixo y) nesse subconjunto de tickets. Conforme ilustrado na Figura 6, abaixo, ambos os modelos tornaram-se mais precisos à medida que a cobertura de dados diminuiu, mas nosso modelo de deep learning apresentou maior precisão para a mesma cobertura e maior cobertura para a mesma precisão.
Em colaboração com a equipe Michelangelo da Uber, estamos na fase final de produção desses modelos de deep learning.
Próximos passos
É claro que estamos entusiasmados com a oportunidade de aproveitar ainda mais essas tecnologias para tornar as experiências de suporte ao cliente de nossos agentes e usuários ainda mais perfeitas. Fique atento às futuras atualizações sobre nossas análises e experiências à medida que continuamos a explorar o mundo do deep learning para NLP!
Se você está interessado em lidar com desafios de engenharia que impulsionam o impacto comercial em escala, considere candidatar-se a um cargo em nossa equipe de Machine Learning Aplicada ou em nossas equipes de Engenharia de Obsessão de Cliente com base em São Francisco e Palo Alto. Se você está interessado na pesquisa machine learning e no processamento de linguagem natural, saiba mais sobre oportunidades de trabalho com a Uber AI Labs.
***
Este artigo é do Uber Engineering. Ele foi escrito por Huaixiu Zheng, Yi-Chia Wang e Piero Molino. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/cota/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?