

Em sistemas distribuídos, tentativas sucessivas são inevitáveis. De erros de rede, até problemas de replicação e inclusive interrupções nas dependências de downstream, os serviços que operam em uma escala maciça devem estar preparados para encontrar, identificar e lidar com falhas tão graciosamente quanto possível.
Dado o escopo e o ritmo em que a Uber opera, nossos sistemas devem ser tolerantes a falhas e intransigentes quando se trata de falhar de forma inteligente. Para conseguir isso, alavancamos o Apache Kafka, uma plataforma open source de mensagens distribuídas que foi testada no setor para oferecer alto desempenho em escala.
Utilizando essas propriedades, a equipe de Engenharia de Seguros da Uber ampliou o papel do Kafka em nossa arquitetura baseada em eventos, usando o reprocessamento de solicitação sem bloqueio e as dead letter queues (DLQ) para conseguir um tratamento de erros desacoplado e observável sem interromper o tráfego em tempo real. Essa estratégia ajuda o nosso programa Driver Injury Protection a funcionar de forma confiável em mais de 200 cidades, deduzindo prêmios por viagem e por milhas para motoristas inscritos.
Neste artigo, destacamos nossa abordagem para os pedidos de reprocessamento em grandes sistemas com SLA em tempo real e compartilhamos as lições aprendidas.
Trabalhando em uma arquitetura baseada em eventos
O backend do Driver Injury Protection se baseia em uma arquitetura de mensagens do Kafka que é executada por um serviço Java englobado em múltiplas dependências dentro do ecossistema maior de microsserviços da Uber. Para os propósitos deste artigo, no entanto, nos concentramos mais especificamente em nossa estratégia de tentar e dead-lettering, seguindo-a através de uma aplicação teórica que gerencia o pré-pedido de diferentes produtos para um negócio online em expansão.
Neste modelo, queremos: a) fazer um pagamento e b) criar um registro separado de captura dados para cada pré-pedido de produto por usuário para gerar análises de produtos em tempo real. Isso é análogo ao modo como uma única viagem premium de Driver Injury Protection processada pela arquitetura de back-end do nosso programa possui um componente de carga real e um registro separado, criado para fins de relatório.
No nosso exemplo, cada função é disponibilizada através da API de seu respectivo serviço. A Figura 1, abaixo, os modela dentro de dois grupos de consumidores correspondentes, ambos inscritos no mesmo canal de eventos de pré-pedido (nesse caso, o tópico Kafka PreOrder):
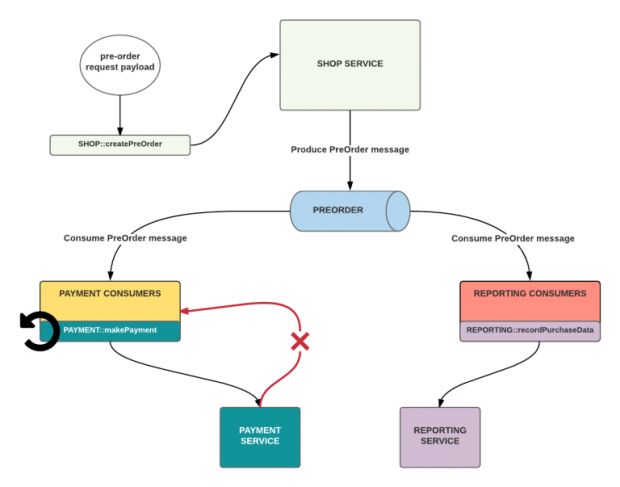
Uma solução rápida e simples para implementar tentativas é usar um ciclo de feedback no ponto da chamada do cliente. Por exemplo, se o Payment Service na Figura 1 tiver uma latência prolongada e começar a lançar exceções de tempo limite, o serviço da loja continuaria a chamar o makePayment sob algum limite de repetição prescrito – talvez com alguma estratégia de backoff – até que ele seja bem-sucedido ou outra condição de parada seja atingida.
O problema com tentativas simples
Enquanto tentar novamente no nível do cliente com um ciclo de feedback pode ser útil, tentativas em sistemas de larga escala ainda podem estar sujeitas a:
- Processamento de lote obstruído. Quando somos obrigados a processar um grande número de mensagens em tempo real, as mensagens com falhas repetidas podem obstruir o processamento em lote. Os piores infratores sempre excedem o limite de tentativas, o que também significa que eles demoram mais e usam a maioria dos recursos. Sem uma resposta de sucesso, o consumidor do Kafka não fará commit de um novo offset e os lotes com essas mensagens ruins serão bloqueados, pois são novamente consumidos, como na figura 2, abaixo.
- Dificuldade em recuperar metadados. Pode ser complicado obter metadados nas tentativas, como timestamps e retry nth.
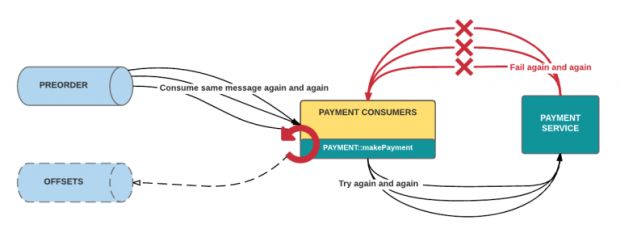
Se os pedidos continuarem a falhar, tentativas após tentativas, queremos colecionar essas falhas em um DLQ para visibilidade e diagnóstico. Um DLQ deve permitir listar para visualizar o conteúdo da fila, purgar para limpar esses conteúdos e mesclar para reprocessar as mensagens dead-lettered, permitindo uma resolução abrangente para todas as falhas afetadas por um problema compartilhado. Na Uber, precisávamos de uma estratégia de tentativa que nos proporcionasse essas capacidades de forma confiável e escalável.
Processando em filas separadas
Para resolver o problema dos lotes bloqueados, configuramos uma fila de tentativa diferente, usando um tópico Kafka definido separadamente. Sob esse paradigma, quando um manipulador de consumidor retorna uma resposta falha para uma determinada mensagem após um certo número de tentativas, o consumidor publica essa mensagem em seu tópico de tentativa correspondente. O manipulador, então, retorna verdadeiro ao consumidor original, o que compromete seu offset.
O sucesso do consumidor é redefinido a partir de uma resposta bem-sucedida do manipulador, o que significa falha zero para o estabelecimento de um resultado conclusivo para a mensagem consumada, que é a resposta esperada ou a colocação em outro lugar para ser tratada separadamente.
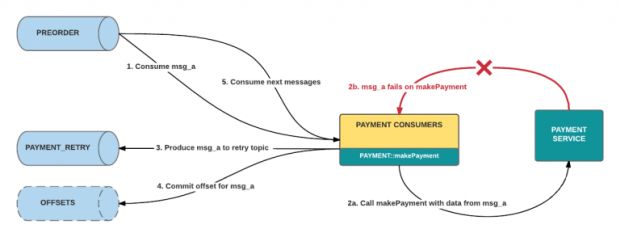
Tentativas de repetir solicitações nesse tipo de sistema são muito diretas. Tal como acontece com o fluxo de processamento principal, um grupo separado de tentativa de consumidores irá ler sua fila de tentativa correspondente. Esses consumidores se comportam como aqueles na arquitetura original, exceto que eles consomem de um tópico diferente do Kafka.
Enquanto isso, a execução de tentativas múltiplas é realizada criando multiplos tópicos, com um conjunto diferente de ouvintes inscritos em cada tópico de tentativa. Quando o manipulador de um determinado tópico retorna uma resposta de erro para uma determinada mensagem, ele publicará essa mensagem para o próximo tópico de tentativa abaixo dele, conforme descrito nas Figuras 3 e 4.
Finalmente, o DLQ é definido como o tópico Kafka de fim-de-linha nesse design. Se um consumidor do último tópico de tentativa ainda não retornar sucesso, ele publicará essa mensagem para o tópico de dead letter. A partir daí, uma série de técnicas podem ser empregadas para listar, purgar e mesclar a partir do tópico, como criar uma ferramenta de linha de comando apoiada por seu próprio consumidor que usa o rastreamento de offset.
Mensagens de dead letters são mescladas para reentrar o processamento ao serem publicadas de volta no primeiro tópico de tentativa. Dessa forma, elas permanecem separadas e são incapazes de impedir o tráfego ao vivo.
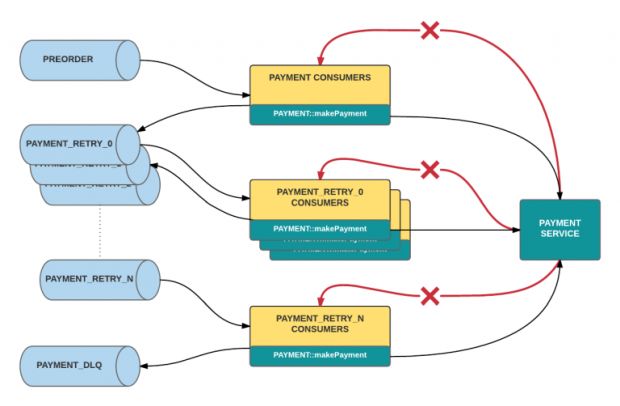
É importante não simplesmente tentar novamente com pedidos falhados imediatamente um após o outro; isso amplificará o número de chamadas, essencialmente enviando pedidos incorretos de spam. Em vez disso, cada nível subsequente de consumidores de tentativa pode impor um atraso de processamento – em outras palavras, um tempo limite que aumenta à medida em que uma mensagem passa por cada tópico de tentativa.
Esse mecanismo segue um padrão de leaky bucket, no qual a taxa de fluxo é expressada pela natureza de bloqueio do consumo de mensagens atrasadas dentro das filas de tentativa. Consequentemente, nossas filas não são tão filas de tentativa, já que são atrasadas processando filas, onde a reexecução de casos de erro é a nossa entrega de melhor esforço: a invocação do manipulador ocorrerá pelo menos após o tempo limite configurado, mas possivelmente mais tarde.
O que ganhamos com reprocessamento baseado em fila
Agora, discutimos os benefícios da nossa abordagem descrita, já que ela se relaciona para garantir o reprocessamento confiável e escalável:
Processamento em lote não bloqueado
As mensagens com falha inserem seus próprios canais designados, permitindo que os sucessos do mesmo lote continuem em vez de exigir que sejam reprocessados junto com as falhas. Assim, o consumo de pedidos recebidos avança desbloqueado, conseguindo maior rendimento em tempo real.
Dissociação
Fluxos de trabalho independentes que operam no mesmo evento, cada um tem seus próprios fluxos de consumo, com reprocessamento separado e dead letter queues. A falha em uma dependência não requer tentar novamente essa mensagem específica para outros que tiveram sucesso. Por exemplo, na Figura 1, se o relatório faltasse, mas o pagamento tivesse sido bem-sucedido, apenas o primeiro precisaria ser “re-tentado” e potencialmente dead-lettered.
Configuração
Criar novos tópicos causa praticamente nenhuma sobrecarga, e as mensagens produzidas para esses tópicos podem respeitar o mesmo esquema. O processamento original, juntamente com cada um dos canais de tentativa, pode ser gerenciado sob uma classe de consumidor de nível mais alto e facilmente escrita, regida pela config quando se trata de qual tópico ler e publicar (em caso de falha), bem como o comprimento do atraso forçado antes de executar o manipulador de uma instância.
Também podemos diferenciar o tratamento de diferentes tipos de erros, permitindo que casos como a falta de rede sejam “re-tentados”, enquanto as exceções de null pointer, e outros erros de código deveriam ir direto para o DLQ porque as tentativas não as corrigiriam.
Observabilidade
A segmentação do processamento de mensagens em diferentes tópicos facilita o rastreamento fácil do caminho de uma mensagem com erro, quando e quantas vezes a mensagem foi “re-tentada” e as propriedades exatas de sua carga útil. O monitoramento da taxa de produção no tópico de processamento original em comparação com o tópico de reprocessamento e a DLQ, podem informar limiares para alertas automatizados e monitoramento do tempo de atividade do serviço real.
Flexibilidade
Embora o próprio Kafka seja escrito em Scala e Java, ele oferece suporte para bibliotecas de clientes em várias linguagens. Por exemplo, muitos serviços da Uber usam o Go para o seu cliente Kafka.
A formatação da mensagem Kafka com um framework de serialização, como o Avro, suporta esquemas evoluíveis. No caso de o nosso modelo de dados precisar ser atualizado, é necessário uma reorganização mínima para refletir essa alteração.
Desempenho e confiabilidade
O Kafka oferece por padrão pelo menos uma semântica. Essa garantia de durabilidade é altamente valiosa no contexto da tolerância a falhas e falha na mensagem; quando se trata de fornecer dados críticos para o negócio (como no caso da Uber), a perda de mensagens é primordial. Além disso, o modelo de paralelismo do Kafka e o sistema baseado em pull, permitem alta produção e baixa latência.
Outras considerações
Como o Kafka só garante o processamento em ordem dentro das partições e não através delas, deve ser aceitável para um aplicativo lidar com eventos fora da ordem exata em que eles ocorrem. Além disso, pelo menos uma vez a entrega da mensagem necessita de idempotência de dependência do consumidor, uma característica comum de qualquer sistema distribuído.
As vantagens descritas na seção anterior oferecem benefícios significativos, mas a milhagem e a implementação podem variar de acordo com o caso de uso. Por exemplo, dependendo de com quantos tipos de dados um determinado aplicativo lida, um conjunto de tópicos para cada fluxo de trabalho de cada tipo de evento pode resultar em uma grande quantidade de tópicos a serem gerenciados.
Nesse caso, uma alternativa para nossas filas com base em conta pode ser envolver o tipo de evento com campos adicionais, rastreando assim a contagem de repetição e o timestamp de uma maneira mais gerenciável. Essa compensação exigiria alguma reconsideração de como o agendamento é realizado, pois isso foi gerenciado através da escada da fila.
Seguindo em frente
Usar tópicos baseados em conta Kafka como reprocessamento separado e dead lettering queues, nos permitiu tentar novamente solicitações em um sistema baseado em eventos sem bloquear o consumo de lote do tráfego em tempo real. Nesse framework, os engenheiros podem configurar, crescer, atualizar e monitorar conforme necessário, sem penalidade para o tempo de desenvolvimento ou o tempo de atividade da aplicação.
***
Este artigo é do Uber Engineering. Ele foi escrito por Ning Xia. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/reliable-reprocessing/.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?