



Resolvendo desafios de Big Data com Ciência de Dados na Uber
Neste artigo da Uber Engineering, dois membros da equipe mostra como a gigante norte-americana resolve seus desafios de Big Data usando Ciência de Dados.


Os dados envolvidos no fornecimento de milhões de viagens e entregas de alimentos na plataforma da Uber não apenas facilitam as transações, mas também ajudam as equipes da Uber a analisar e melhorar continuamente nossos serviços.
Quando lançamos novos serviços, podemos medir rapidamente o sucesso e, quando vemos anomalias nos dados, podemos procurar rapidamente as causas raiz.
Encarregada de fornecer esses dados para análise operacional diária, nossa equipe de Data Warehouse mantém um banco de dados massivamente paralelo rodando o Vertica, uma popular plataforma de análise de dados interativa.
Todos os dias nosso sistema lida com milhões de consultas, com 95% delas levando menos de 15 segundos para retornar uma resposta.
Enfrentar esse desafio não foi fácil, especialmente considerando o crescimento exponencial do volume de corridas e entregas da Uber ao longo dos anos.
Os crescentes requisitos de armazenamento para esse sistema fizeram com que nossa estratégia inicial de adicionar clusters Vertica totalmente duplicados aumentasse o volume de consultas com custo proibitivo.
Uma solução surgiu através das forças combinadas de nossas equipes de Data Warehouse e Data Science/Ciência de Dados. Analisando o problema por meio da análise de custos, nossos cientistas de dados ajudaram nossos engenheiros de Data Warehouse a criar um meio de replicar parcialmente os clusters da Vertica para melhor dimensionar nosso volume de dados.
Otimizar nossos recursos de computação dessa maneira significou que poderíamos escalar para nosso ritmo atual de servir mais de um bilhão de viagens em nossa plataforma, levando a experiências de usuário aprimoradas em todo o mundo.
Dimensionamento para o volume de consultas
Durante o período inicial de crescimento rápido da Uber, adotamos uma abordagem bastante comum de instalar vários clusters Vertica isolados para atender às milhões de consultas analíticas feitas todos os dias.
Esses clusters eram imagens espelhadas completamente isoladas entre si, fornecendo duas vantagens principais.
Primeiro, elas ofereceram tolerância a falhas de cluster, por exemplo, se um cluster falhar, o negócio poderá ser executado como de costume, já que o cluster de backup contém uma cópia de todos os dados necessários.
Segundo, poderíamos distribuir as consultas recebidas para clusters diferentes, conforme ilustrado na Figura 1, abaixo, ajudando assim a aumentar o volume de consultas que podem ser processadas simultaneamente:
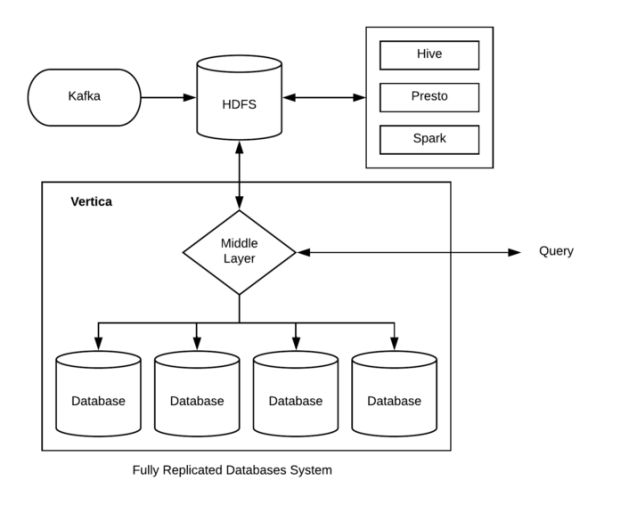
Com os dados armazenados em vários clusters isolados, investigamos estratégias para equilibrar a carga da consulta. Algumas estratégias comuns que encontramos incluem:
- 1. Atribuição aleatória: Atribua aleatoriamente uma consulta recebida a um cluster, com a suposição de que a aleatorização resultará automaticamente em uma carga balanceada.
- 2. Segmentação do usuário: Atribua usuários a diferentes clusters para que todas as consultas de um determinado usuário sejam direcionadas apenas ao cluster designado.
- 3. Balanceamento de CPU: Controle o uso da CPU em diferentes clusters e atribua consultas a clusters com o menor uso de CPU.
Confiar em vários clusters totalmente isolados com uma camada de roteamento para impor a segmentação do usuário em um nível de cluster surgiu com o desafio de gerenciar esses clusters de banco de dados, juntamente com a ineficiência de armazenamento associada à replicação de cada parte dos dados em cada cluster.
Por exemplo, se temos 100 petabytes de dados replicados seis vezes, o requisito total de armazenamento de dados é de 600 petabytes.
Outros desafios de replicação, como o custo de computação associado à gravação de dados e a criação de projeções e índices necessários associados a atualizações de dados incrementais, também se tornaram aparentes.
Esses desafios foram ainda mais agravados pelo nosso rápido crescimento global e incursão em novos empreendimentos, como entrega de alimentos, frete e compartilhamento de bicicletas.
À medida que começamos a ingerir quantidades crescentes de dados no Data Warehouse da Uber para suportar as necessidades de nossos negócios em crescimento, o fato de a Vertica combinar computação e armazenamento em máquinas individuais significou um aumento correspondente na quantidade de hardware necessária para suportar os negócios.
Essencialmente, estaríamos pagando os custos de hardware para aumentar o armazenamento sem qualquer ganho no volume de consultas.
Se optarmos por adicionar mais clusters, o desperdício de recursos implícito no processo de replicação significaria que o volume de consulta real não cresceu linearmente.
A absoluta falta de eficiência em termos de alocação de capital, bem como desempenho, significava que precisávamos pensar fora da caixa para encontrar uma solução que fosse escalável.
Aplicando ciência de dados à infraestrutura de dados
Dada a experiência da Uber em ciência de dados, decidimos aplicar princípios desse campo para otimizar nossa infraestrutura de dados. Trabalhando de perto com a equipe de Data Science, planejamos aumentar a escalabilidade de volume de consultas e dados para nossos mecanismos analíticos rápidos.
Uma estratégia natural para superar o desafio do armazenamento era passar de bancos de dados totalmente replicados para bancos de dados parcialmente replicados.
Conforme mostrado na Figura 2, em comparação a um sistema de banco de dados totalmente replicado em que todos os dados são copiados para todos os clusters de banco de dados isolados, um sistema de banco de dados parcialmente replicado segmenta dados em diferentes conjuntos sobrepostos de elementos de dados, igual ao número de clusters:
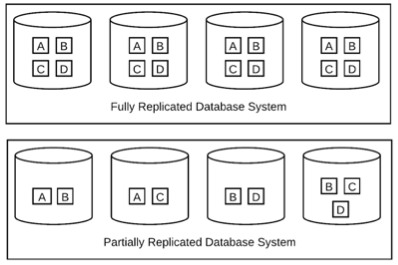
Devido à grande escala do problema, envolvendo milhares de consultas e centenas de tabelas, construir esses diferentes conjuntos sobrepostos de elementos de dados não é trivial.
Além disso, as estratégias de replicação parcial são geralmente de curta duração à medida que os elementos de dados crescem em taxas diferentes, e esses elementos de dados mudam à medida que o negócio evolui.
Além de considerar a disponibilidade do banco de dados, juntamente com a escalabilidade de computação e armazenamento, também tivemos que considerar os custos de migração de replicar parcialmente nossos bancos de dados.
Com esse desafio de infraestrutura de dados em mente, nossas equipes de Data Warehouse e Data Science/Ciência de Dados apresentaram três requisitos básicos para nossa solução ideal:
- 1. Minimize o requisito geral de espaço em disco: nosso rápido crescimento significa que nossa estratégia existente de adicionar clusters totalmente replicados não foi eficiente, conforme descrito acima. Qualquer nova solução deve nos permitir densificar nosso armazenamento e fazer uso eficiente dos recursos.
- 2. Equilibre o uso do disco em clusters: Idealmente, queremos que o espaço em disco preenchido em cada cluster seja quase o mesmo. Supondo que os dados estejam crescendo no mesmo ritmo em todos os clusters, isso é desejável, pois garante que nenhum cluster único fique sem espaço em disco antes dos outros.
- 3. Equilibre o volume de consultas nos clusters: Ao otimizar o espaço em disco, também queremos garantir que estamos distribuindo o volume de consultas de maneira uniforme entre os clusters. Se negligenciada, podemos acabar com uma situação em que todas as consultas são roteadas para um único cluster.
Nossa equipe de ciência de dados formalizou esses requisitos em uma função de custo que pode ser descrita como:
- Custo (Configuração Parcial) = S + L + M
Uma breve descrição das três variáveis na equação acima é explicada abaixo, e uma discussão mais detalhada pode ser encontrada em nosso artigo, Ephemeral Partially Replicated Databases/Bancos de dados efêmeros parcialmente replicados.
- S é descrito como a utilização máxima de armazenamento nos clusters N Vertica. A utilização de armazenamento é a proporção de elementos de dados armazenados em um único cluster para o tamanho total dos elementos de dados. Por exemplo, se o tamanho total do elemento de dados armazenado em um cluster Vertica for 60 petabytes e o tamanho total de todos os elementos de dados for 100 petabytes para um determinado candidato a configuração parcial, então a utilização do armazenamento será 0,6.
- L é descrito como a utilização máxima de computação nos clusters N Vertica. A utilização de computação, por sua vez, é descrita como o volume de consulta de porcentagem que pode ser manipulado por um determinado cluster.
- M é descrito como o custo máximo de migração nos clusters N Vertica. Como descrito acima, um dos desafios de usar bancos de dados parcialmente replicados é que uma configuração parcial ideal eventualmente se torna sub-ótima devido às diferentes taxas nas quais diferentes elementos de dados crescem, bem como devido à natureza mutável dos serviços e produtos oferecidos por uma empresa. Como resultado, os bancos de dados replicados geralmente precisam ser reconfigurados. Essa reconfiguração requer a movimentação de elementos de dados de um banco de dados para outro e, portanto, consome recursos de computação. Idealmente, preferimos uma configuração que minimize o custo da migração. O custo de migração pertencente a um cluster de banco de dados é descrito como a quantidade de novos elementos de dados que serão copiados do estado determinado do banco de dados para o novo estado do mesmo banco de dados.
Minimizar a função de custo acima para milhares de tabelas e milhões de consultas é uma tarefa difícil. Com base em observações empíricas, nossa equipe de Data Science identificou que 10% das maiores tabelas representam cerca de 90% da utilização do disco. Assim, a maior parte da eficiência do espaço em disco será obtida com uma configuração ideal de apenas 10% de nossas tabelas.
O foco nessas tabelas reduziu significativamente o número de parâmetros de decisão necessários para a otimização. Além disso, nossa equipe de Data Science desenvolveu um algoritmo que gera soluções propositadamente sub-ótimas, atribuindo avidamente tabelas e consultas a clusters com o menor custo.
Esse algoritmo ganancioso, que, comparado a uma solução ideal reduz a economia de disco em 5%, é significativamente mais rápido e é concluído em poucos minutos. Decidimos produzir este algoritmo para favorecer a velocidade sobre o uso do disco.
Depois que descobrimos os problemas da ciência de dados, o próximo passo foi enfrentar os desafios da engenharia. Para dar suporte à replicação parcial, tivemos que aprimorar significativamente dois componentes, nosso gerenciador de proxy e nosso gerenciador de dados, destacados abaixo.
- Proxy Manager: com bancos de dados Vertica totalmente replicados, um gerenciador de proxy fornece uma pequena abstração entre o cliente e seus bancos de dados correspondentes, além de atuar como um balanceador de carga. Todas as consultas recebidas são roteadas por essa camada, que tem conhecimento da carga da consulta, do local dos dados e da integridade do cluster para garantir que cada consulta seja roteada para um cluster que possa manipulá-la.
- Data Manager: o segundo componente necessário era um gerenciador de dados. No mundo totalmente replicado, todos os dados são copiados de um lago de dados upstream para todos os bancos de dados Vertica disponíveis.
No entanto, em nosso design proposto, cada elemento de dados é copiado para diferentes bancos de dados, dependendo da configuração parcial. O gerenciador de dados contém informações sobre qual cluster requer quais tabelas a serem carregadas nele e compartilhará essas informações com o gerenciador de proxy.
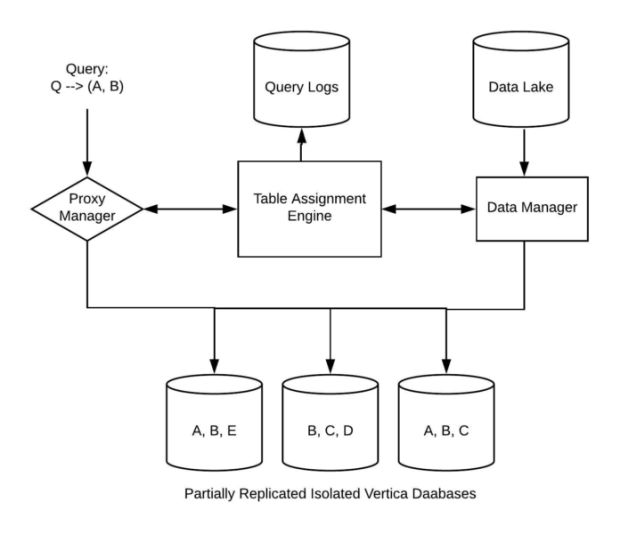
Com todas essas peças implementadas, nossa solução conseguiu reduzir significativamente o consumo geral de disco em mais de 30%, enquanto continuava a fornecer o mesmo nível de escalabilidade de computação e disponibilidade de banco de dados. A economia obtida resultou em menor custo de hardware, apesar do crescimento do volume de consultas e também garantiu que pudéssemos equilibrar a carga uniformemente entre os clusters. Para as equipes internas da Uber que usavam esses dados, esse balanceamento de carga significava um tempo de atividade aprimorado, pois todas as consultas eram sempre direcionadas para os clusters mais saudáveis/íntegros e reduziam as falhas dos ETLs.
Construindo uma infraestrutura inteligente
Trabalhar de perto com a equipe da Data Science neste projeto demonstrou como o poder da aprendizagem de máquina e da ciência de dados pode ser incorporado ao mundo da infraestrutura de dados e ser usado para criar um impacto significativo não apenas nos negócios da Uber, mas também para milhares de usuários, de pesquisadores de a gerentes de operações municipais, dentro da Uber que nos confia potencializar o ajuntamento de insights e a tomada de decisões.
O sucesso deste projeto estimulou uma colaboração mais profunda entre nossas equipes de Infraestrutura e Ciência de Dados e levou ao desenvolvimento de uma nova equipe de Infraestrutura Inteligente para repensar o projeto de infraestrutura para aplicativos de Big Data.
Se você está interessado em trabalhar conosco ao construir uma plataforma voltada para dados que move o mundo, junte-se às nossas equipes!
***
Este artigo é do Uber Engineering. Ele foi escrito por Atul Gupte e Ritesh Agrawal. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/solving-big-data-challenges-with-data-science-at-uber/


