

Um dos componentes do Azure Synapse Analytics é o recurso conhecido como SQL Pool, que funciona, em linhas gerais, como um grande servidor SQL.
O Synapse SQL Pool usa uma arquitetura de Processamento Paralelo Massivo (ou MPP, na sigla em inglês), que lhe permite oferecer uma capacidade de processamento extremamente alta.
Mas é importante lembrar que ele funciona de modo semelhante e não idêntico a um banco de dados relacional. São necessárias, por exemplo, algumas definições extras na criação de cada tabela para o bom aproveitamento desta arquitetura.
Este artigo apresenta o caso ocorrido em um cliente que reclamava de lentidão de consultas que rodavam neste ambiente.
Synapse SQL Pool e MPP
A arquitetura MPP é voltada basicamente para ambientes de Data Warehouse. Não é uma tecnologia nova e atualmente existem vários serviços disponíveis no mercado, seja on-premises ou na nuvem. O Synapse SQL Pool é o serviço MPP disponível no Azure.
O objetivo dessa arquitetura, como sugere o próprio nome, é paralelizar a operação de cada consulta individual. No Synapse SQL Pool, os recursos de armazenamento e processamento são independentes, como mostra a Figura 01.
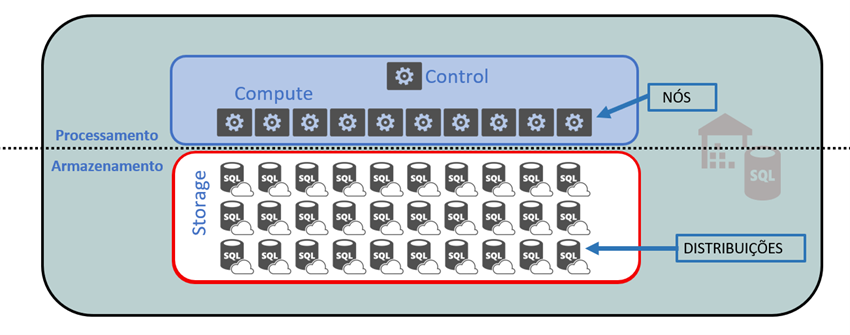
Figura 01: arquitetura do Synapse SQL Pool
Os dados de cada tabela são divididos e armazenados em 60 “bases de dados” menores, chamadas distribuições. As unidades de processamento são chamadas nós. Sempre haverá um nó de controle (que coordena as operações paralelizadas) e entre um e 60 nós de computação, conforme a sua necessidade.
O cliente paga separadamente pelo volume armazenado e a capacidade computacional requerida, referida como DWU. O número de DWUs escolhido é, de longe, o maior componente de custo do serviço.
Esta capacidade de processamento expressa em DWUs é obtida através de uma combinação de número de nós de processamento reservados para sua operação e quantidade de memória alocada. Pode variar entre DWU100c, com um nó de computação e 60 GB de RAM, até DWU30000c, que oferece 60 nós de computação e 18000 GB de RAM (mais detalhes neste link). Sempre que necessário, o cliente pode ampliar ou reduzir a capacidade de processamento, ou até mesmo pausar o serviço como um todo.
Para ter uma visualização melhor do que acontece com o processamento conforme o número de nós de computação escolhidos, veja a Figura 02. As 60 distribuições podem ser processadas todas no mesmo nó, mas se houver mais de um, elas serão distribuídas uniformemente. (Não por acaso, todas as opções de DWUs envolvem números que são divisores de 60, como se observa no link anterior).
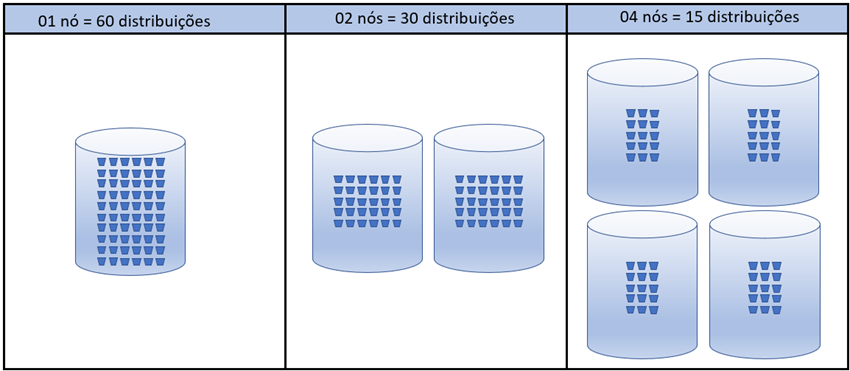
Figura 02: Distribuições vs quantidade de nós de computação disponíveis
Uma diferença fundamental entre um serviço normal de banco de dados relacional e um serviço de MPP é que o primeiro se destina a execução de operações simples em ambiente de alta concorrência, enquanto o outro tem o objetivo é inverso: atender a execução de operações pesadas e com baixa concorrência, ou seja, poucos usuários conectados.
Distribuição Uniforme dos Dados
A ideia de segmentar os dados de cada tabela em 60 “bancos de dados” menores chamados de distribuição é de fato muito boa. Ela permite paralelizar o processamento de consultas, mas esconde um requisito importante: é esperado que seus dados estejam uniformemente distribuídos (estatisticamente falando) entre as 60 distribuições em que são armazenados.
(Ok, concordo que é confuso usar o termo “distribuição” para dois conceitos tão diferentes, mas isso não é culpa minha).
Não é difícil de entender isso. Lembre-se que toda consulta será dividida em 60 processos menores, cada um associado a uma distribuição. Se os dados da tabela estiverem uniformemente distribuídos em cada “segmento” da tabela (as 60 distribuições), cada processo que vai rodar em paralelo terá (mais ou menos) a mesma carga, melhorando a performance da consulta.
Quando isso não acontece, alguns processos serão sobrecarregados e o tempo total de execução da consulta vai ser afetado.
Acontece que nem sempre será possível encontrar colunas da tabela que garantam a distribuição uniforme que se espera obter.
Por conta disso, o Synapse SQL Pool oferece três tipos diferentes de distribuição a se considerar no momento da criação da tabela. São eles:
- Replicação: destinada a tabelas pequenas (com até 2Gb); ao invés de segmentar dados, na distribuição replicada é feita uma cópia completa da tabela para cada uma das 60 distribuições.
- Round Robin: é a distribuição default; os dados são distribuídos aleatoriamente entre as distribuições, exatamente como a distribuição de cartas de um baralho. Isso garante que cada distribuição terá praticamente o mesmo número de registros, mas não há nenhuma lógica nesta distribuição. Um exemplo: digamos que minha consulta use um filtro para buscar dados do Estado do Ceará; o otimizador de consultas precisará vasculhar as 60 distribuições para encontrar todos os registros desejados. E essa movimentação de dados seguramente afetará a performance.
- Hash: esta é, teoricamente, a distribuição desejável no modelo MPP, mas exige certos requisitos que não são facilmente encontrados. A ideia é segmentar os dados com base no “hash” calculado sobre o valor de uma ou mais colunas-chave (clique aqui mais detalhes sobre o assunto). Portanto, a(s) coluna(s) usada(s) para hash deve(m) ter uma distribuição razoavelmente uniforme e oferecer 60 ou mais valores distintos. A ideia aqui é distribuir dados igualmente entre distribuições e, ao mesmo tempo, reduzir a movimentação de dados durante a execução das consultas. Obviamente, a redução da movimentação de dados é esperada em função do armazenamento dentro da mesma distribuição dos registros que tiverem o mesmo valor de hash.
A escolha do tipo de distribuição usada em cada tabela não é uma operação elementar. Além disso, esta definição não pode ser alterada depois de criada a tabela. Para mais informações sobre a escolha do tipo de distribuição, consulte este link.
Modelo de Dados
Em geral, recomenda-se usar o modelo dimensional para os bancos de dados que usam o Synapse SQL Pool.
Normalmente as tabelas de dimensões usam o tipo de distribuição com Replicação e as tabelas fato, se possível, usam tipo Hash. Do contrário, se adota a distribuição default, Round Robin.
Também por default, toda tabela é criada com índice columnstore clusterizado. Dependendo do volume de dados da tabela, isso pode ser inadequado. Nestes casos, será necessário especificar outro tipo de indexação no momento da criação da tabela (link).
As Consultas Lentas do Cliente
Conhecendo os conceitos básicos da operação do Synapse SQL Pool, podemos agora avaliar o que aconteceu com as consultas lentas do cliente.
O problema foi observado inicialmente na operação de painéis do Power BI. Havia a suspeita de que o problema fosse relacionado ao volume de dados consumido. Mas a lentidão persistia independente de se consumir dados através de importação de datasets ou mesmo com Direct Query, opção do Power Query para consulta direta na fonte de dados, que no caso era o Synapse SQL Pool.
Verificando a volumetria (menos de 200 milhões de registros) e a capacidade do serviço contratado (DWU300c), ficou claro que o problema não era nem volumetria e nem capacidade de processamento.
A questão se resolveu quando se checou a definição do objeto consultado. Não era uma tabela, mas sim uma visão que envolvia uma consulta complexa com várias regras de negócio envolvendo por volta de 10 tabelas, três delas tabelas grandes.
E por que isso não funcionaria bem numa arquitetura de MPP? Ora, esta consulta não sumarizava nada. Os dados de múltiplas tabelas grandes eram lidos (das 60 distribuições de cada tabela), filtrados… e milhões de registros de cada tabela eram passados para o nó de controle executar os múltiplos JOINs envolvidos.
Um simples consulta, retornando os primeiros 1000 registros dessa visão, levava mais de 4 minutos para ser executada.
A Solução
A simples conversão dessa visão numa tabela física resolveu o problema.
Mesmo usando apenas opções default do SQL Pool, sem nenhuma otimização em particular (ou seja, a tabela final foi criada com índice columnstore clusterizado e distribuição do tipo Round Robin), esta consulta passou a rodar em menos de 3 segundos quando usamos a tabela física. Grosso modo, o tempo de execução foi reduzido em 99%.
Comentários Finais
Esse é um caso clássico de aplicar o conhecimento sem se adequar às ferramentas que se escolhe.
Num servidor relacional puro, o uso de uma visão seria perfeitamente viável. Mas se a ferramenta escolhida usa uma arquitetura diferente, no caso um MPP, é necessário avaliar como o otimizador de consultas vai executar a operação e então providenciar as devidas adaptações.
Informações Adicionais
*O conteúdo deste artigo é de responsabilidade do(a) autor(a) e não reflete necessariamente a opinião do iMasters.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?