



DBEvents: Framework padronizado para a ingestão eficiente de dados da Uber
Neste artigo, a equipe da Uber Engineering apresenta o DBEvents, um framework padronizado para a Ingestão eficiente de dados no Apache Hadoop da Uber.


Manter a plataforma da Uber confiável e em tempo real nos nossos mercados globais é um negócio de 24 horas por dia, 7 dias por semana.
As pessoas podem ir dormir em São Francisco, mas em Paris elas estão se preparando para o trabalho, solicitando corridas dos motoristas parceiros da Uber.
Neste mesmo instante, do outro lado do mundo, os moradores de Mumbai poderiam estar pedindo um jantar pela Uber Eats.
Facilitamos essas interações na plataforma de Big Data da Uber, usando nosso marketplace para acompanhar os passageiros e os motoristas parceiros; consumidores, restaurantes e parceiros de entrega; e caminhoneiros e transportadoras.
Os insights orientados por dados sobre essas interações nos ajudam a criar produtos que proporcionam experiências gratificantes e significativas a usuários em todo o mundo.
Como os consumidores querem que a comida seja entregue em tempo hábil e os passageiros querem esperar uma quantidade mínima de tempo para o início de uma corrida, nossos dados devem refletir os eventos no local com a maior prontidão possível.
No entanto, à medida que os dados chegam ao nosso lago/banco de dados a partir de várias fontes, mantê-los atualizados nessa escala representa um grande desafio.
Embora as soluções existentes ofereçam trabalho de atualização 24 horas por dia para muitas empresas, são excessivamente obsoletas para as necessidades em tempo real da Uber.
Além disso, o tamanho dos dados e a escala das operações na Uber impedem que tal solução funcione de forma confiável.
Para atender a essas necessidades, desenvolvemos o DBEvents, um sistema de captura de dados alterados projetado para alta qualidade e atualização de dados.
Um sistema de captura de dados alterados (CDC) pode ser usado para determinar quais dados foram alterados de forma incremental para que a ação possa ser executada, como ingestão ou replicação.
O DBEvents facilita o bootstrapping, ingerindo um instantâneo de uma tabela existente e atualizações incrementais de streaming.
Complementando outros softwares construídos na Uber, como Marmaray e Hudi, o DBEvents captura dados de fontes como MySQL, Apache Cassandra e Schemaless, atualizando nosso lago de dados do Hadoop.
Essa solução gerencia petabytes de dados e opera em escala global, ajudando-nos a oferecer aos clientes de dados internos o melhor serviço possível.
Ingestão de dados de instantâneo
Historicamente, a ingestão de dados na Uber começou com a identificação do conjunto de dados a ser ingerido e a execução de um grande trabalho de processamento, com ferramentas como MapReduce e Apache Spark lendo com alto grau de paralelismo de um banco de dados ou tabela de origem.
Em seguida, encaminharíamos a saída/o resultado dessa tarefa para um lago de dados off-line, como o HDFS ou o Apache Hive. Esse processo, chamado de instantâneo, geralmente levava de minutos a horas, dependendo do tamanho do conjunto de dados, que não era rápido o suficiente para as necessidades de nossos clientes internos.
Toda vez que um trabalho começava a ingerir dados, ele distribuía tarefas paralelas, estabelecia conexões paralelas com uma tabela upstream, como o MySQL, e extraía dados.
Ler grandes quantidades de dados do MySQL coloca muita pressão sobre o tráfego de aplicativos em tempo real para o MySQL, diminuindo a velocidade para níveis inaceitáveis.
As estratégias para reduzir essa pressão incluem o uso de servidores dedicados para extrair, transformar e carregar (ETL), mas isso traz outras complicações relacionadas à integridade dos dados, além de adicionar custos extras de hardware para um servidor de banco de dados de backup.
O tempo para tirar um instantâneo de banco de dados ou tabela aumenta com a quantidade de dados e, em algum momento, torna-se impossível satisfazer as demandas do negócio.
Como a maioria dos bancos de dados tem apenas parte de seus dados atualizados com um número limitado de novos registros adicionados diariamente, esse processo de instantâneo também resulta em uma utilização ineficiente dos recursos de computação e armazenamento, lendo e gravando os dados da tabela inteira, incluindo linhas inalteradas, de novo e de novo.
Requisitos de DBEvents
Com a necessidade da Uber de insights mais novos e mais rápidos, precisávamos criar uma maneira melhor de ingerir dados em nosso lago de dados.
Quando começamos a projetar o DBEvents, identificamos três requisitos de negócios para a solução resultante: frescor, qualidade e eficiência.
Frescor
O frescor dos dados refere-se ao quão recentemente eles foram atualizados. Considere uma atualização para uma linha em uma tabela no MySQL no tempo t1. Um trabalho de ingestão começa a ser executado no tempo t1 + 1 e leva N unidades de tempo para ingerir esses dados.
Os dados ficam disponíveis para os usuários no tempo t1 + 1 + N. Aqui, o intervalo de atualização dos dados é igual a N + 1, que é o intervalo entre quando os dados foram realmente atualizados até quando estão disponíveis no lago de dados.
A Uber tem muitos casos de uso que requerem que N + 1 seja o menor possível, preferivelmente na ordem de alguns minutos. Esses casos de uso incluem detecção de fraudes, onde até mesmo o menor atraso pode afetar a experiência do cliente. Por esses motivos, tornamos a atualização de dados uma prioridade alta em DBEvents.
Qualidade
Os dados em um lago de dados são inúteis se não pudermos descrevê-los ou entendê-los. Imagine uma situação em que diferentes serviços de upstream tenham esquemas diferentes para tabelas diferentes.
Embora cada uma dessas tabelas tenha sido criada com um esquema, esses esquemas evoluíram à medida que seus casos de uso foram alterados.
Sem um meio consistente de definir e desenvolver um esquema para os dados sendo ingeridos, um lago de dados pode se transformar rapidamente em um pântano de dados, uma coleção de grandes quantidades de dados que não podem ser compreendidos.
Além disso, à medida que um esquema de tabela evolui, é importante comunicar o raciocínio por trás da adição de novos campos ou da depreciação dos existentes.
Sem uma compreensão do que uma coluna representa, não se pode entender os dados. Como resultado, garantir dados de alta qualidade foi outra prioridade para os DBEvents.
Eficiência
Na Uber, temos milhares de microsserviços responsáveis por diferentes partes da lógica de negócios, além de diferentes linhas de negócios. Na maioria dos casos, cada microsserviço tem um ou mais bancos de dados de apoio usados para armazenar dados não efêmeros.
Como se pode imaginar, isso leva a centenas ou milhares de tabelas que podem ser elegíveis para ingestão, exigindo uma grande quantidade de recursos de computação e armazenamento.
Consequentemente, um terceiro objetivo que definimos para DBEvents foi tornar o sistema eficiente. Ao otimizar o uso de recursos, como armazenamento e computação, acabamos reduzindo os custos em torno do uso do centro de dados e do tempo de engenharia e, posteriormente, facilitamos a adição de mais fontes no futuro.
Criando DBEvents
Com essas três necessidades em mente, criamos o DBEvents, o sistema de captura de dados alterados da Uber, para capturar e ingerir alterações nos dados de forma incremental, levando a uma melhor experiência em nossa plataforma.
A ingestão do conjunto de dados pode ser dividida em dois processos:
- 1. Bootstrap: A representação de um instantâneo de instante de tempo de uma tabela.
- 2. Ingestão incremental: Ingestão incremental e aplicação de alterações (ocorrendo upstream) em uma tabela.
Bootstrap
Desenvolvemos uma biblioteca plugável de origem para iniciar o bootstrap de fontes externas como Cassandra, Schemaless e MySQL no lago de dados via Marmaray, nossa plataforma de ingestão.
Esta biblioteca fornece a semântica necessária para inicializar conjuntos de dados de forma eficiente, fornecendo uma arquitetura conectável para adicionar qualquer fonte. Cada fonte externa faz um instantâneo de seus dados brutos no HDFS.
Depois que o processo de backup de captura instantânea é concluído, Marmaray chama a biblioteca, que por sua vez lê os dados de volta, os esquematiza e os serve como um Conjunto de Dados Distribuídos Resilientes ao Spark (RDD) que pode ser usado por Marmaray.
Marmaray, em seguida, persiste o RDD em Apache Hive depois de realizar deduplicação opcional, mesclagem de linha parcial e várias outras ações.
Para melhorar a eficiência e a confiabilidade de ingerir tabelas realmente grandes, o processo de bootstrap é incremental. Pode-se definir um tamanho de lote para o conjunto de dados e pode, de forma incremental (e possivelmente paralela), fazer o bootstrap de um conjunto de dados, evitando trabalhos excessivamente grandes.
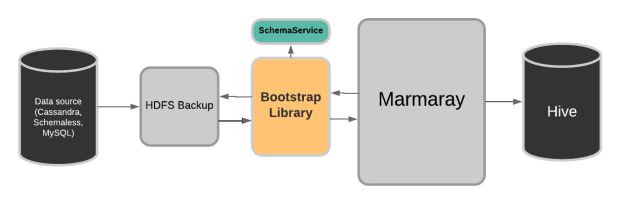
Exemplo de bootstrap do MySQL
Criar backups de bancos de dados MySQL tradicionalmente envolve fazer uma cópia dos dados no sistema de arquivos e armazená-los em outro mecanismo de armazenamento usando seu formato de arquivo nativo.
Esse tipo de backup, no qual os arquivos são copiados bit por bit, é chamado de backup físico. Os chamados arquivos físicos que estão sendo copiados geralmente contêm dados duplicados devido à existência de índices, o que aumenta significativamente o tamanho do conjunto de dados no disco.
Como parte de nossa arquitetura DBEvents, desenvolvemos e criamos em código aberto um serviço chamado StorageTapper, que lê dados de bancos de dados MySQL, transforma-os em uma versão esquematizada e publica os eventos em destinos diferentes, como o HDFS ou o Apache Kafka.
Esse método de geração de eventos em sistemas de armazenamento de destino nos permite criar backups lógicos. Em vez de usar uma cópia direta de um conjunto de dados, um backup lógico depende dos eventos criados pelo StorageTapper, com base no banco de dados original, para recriar conjuntos de dados no sistema de destino.
Além de maior eficiência do que os backups físicos, os backups lógicos oferecem os seguintes benefícios:
- Eles são fáceis de processar por sistemas diferentes do serviço de armazenamento de origem, porque os dados estão em um formato padrão e utilizável.
- Eles não são dependentes de versões específicas do MySQL, proporcionando assim uma melhor integridade dos dados.
- Eles são significativamente compactos porque não copiam dados duplicados.
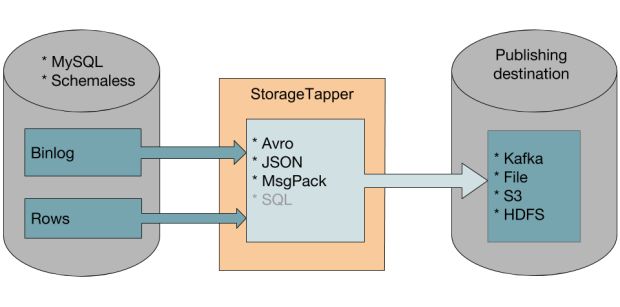
Alcançando frescor
Para tornar nossos dados o mais atualizados possível, precisamos consumir e aplicar alterações a um conjunto de dados de forma incremental, em pequenos lotes. Nosso lago de dados usa o HDFS, um sistema somente de anexação, para armazenar petabytes de dados.
A maioria dos nossos dados analíticos é gravada no formato de arquivo Apache Parquet, que funciona bem para grandes verificações colunares, mas não pode ser atualizado. Infelizmente, como o HDFS é somente para anexação e o Apache Parquet é imutável, os usuários não podem aplicar atualizações a um conjunto de dados sem reescrever em massa todo o conjunto de dados ou, no caso do Hive, reescrever grandes partições do conjunto de dados.
Para ingerir dados rapidamente, usamos o Apache Hudi, uma biblioteca de código aberto criada pela Uber para gerenciar todos os conjuntos de dados brutos no HDFS, o que reduz o tempo gasto para realizar upserts em nosso lago de dados imutável. O Apache Hudi fornece upserts atômicos e fluxos de dados incrementais em conjuntos de dados.
Exemplo de Ingestão Incremental do MySQL
Juntamente com o bootstrapping, também podemos usar o StorageTapper para executar a ingestão incremental de fontes MySQL. Em nosso caso de uso, o StorageTapper lê os eventos dos logs binários do MySQL, que registra as alterações feitas no banco de dados.
O log binário inclui todas as operações INSERT, UPDATE, DELETE e DDL, às quais nos referimos como eventos de log binários. Esses eventos são gravados no log na mesma ordem em que as alterações foram confirmadas no banco de dados.
O StorageTapper lê esses eventos, os codifica no formato Apache Avro e os envia para o Apache Kafka. Cada evento de log binário é uma mensagem no Kafka e cada mensagem corresponde a uma linha completa de dados da tabela.
Como os eventos enviados para o Apache Kafka refletem a ordem em que as alterações foram feitas no banco de dados de origem, quando aplicamos as mensagens do Apache Kafka a um banco de dados diferente, obtemos uma cópia exata dos dados originais.
Esse processo usa menos recursos de computação do que a transferência direta de dados do MySQL para um banco de dados diferente.
Reforçando a qualidade
Para garantir dados de alta qualidade, primeiro precisamos definir a estrutura de um conjunto de dados no lago de dados usando um esquema.
A Uber usa um serviço de gerenciamento de esquema interno chamado Schema-Service, que garante que cada conjunto de dados inserido no lago de dados tenha um esquema associado e que qualquer evolução do esquema passe por certas regras de evolução.
Essas regras de evolução garantem compatibilidade retroativa em esquemas para evitar a quebra de consumidores de tais conjuntos de dados.
O Schema-Service usa o formato Apache Avro para armazenar esquemas e executar a evolução do esquema. Esse esquema geralmente é uma representação 1:1 do esquema da tabela upstream.
Uma ferramenta de autoatendimento permite que os usuários internos desenvolvam o esquema, desde que as alterações sejam aceitas como compatíveis com versões anteriores.
Depois que as alterações do esquema passam no formato Apache Avro, uma uma declaração de linguagem de definição de dados (DDL) é aplicada à tabela para alterar o esquema real da tabela.
A codificação de esquema é um processo através do qual cada datum/dado é esquematizado. Uma biblioteca de aplicação de esquemas (heatpipe) esquematiza ou codifica cada datum, muito parecido com um thin client que pode realizar verificações de esquema em cada datum.
A biblioteca de aplicação de esquemas também adiciona metadados a cada changelog, tornando-os padronizados globalmente, independentemente de qual fonte os dados se originam ou para qual coletor os dados devem ser gravados.
Certificar-se de que todos os nossos dados seguem um esquema e que nossos esquemas estejam atualizados significa que podemos encontrar e usar todos os dados ingeridos em nosso lago de dados.
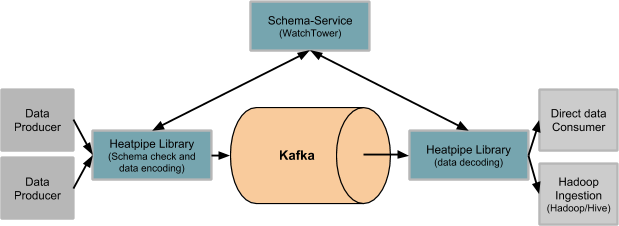
Exemplo de aplicação de esquema do MySQL
Conforme descrito acima, os usuários podem solicitar alterações no esquema para o MySQL através do Schema-Service, que validará as alterações e garantirá que elas sejam compatíveis com versões anteriores.
Se a solicitação for bem-sucedida, uma nova versão do esquema estará disponível para uso. Sempre que o StorageTapper lê uma instrução ALTER TABLE nos logs binários do MySQL, ele detecta essas mudanças de esquema. Isso aciona o StorageTapper para começar a usar o novo esquema para processar mais eventos.
Uso eficiente de recursos
Identificamos algumas ineficiências em nossos pipelines mais antigos:
- Compute o uso: Trabalhos grandes capturando instantaneamente toda a tabela e recarregando-os a uma cadência é altamente ineficiente, especialmente quando apenas alguns registros podem ter sido atualizados.
- Estabilidade upstream: Devido à necessidade frequente de carregar toda a tabela, o trabalho coloca pressão na origem, como durante leituras pesadas em uma tabela MySQL.
- Correção de dados: As verificações de qualidade de dados não são executadas antecipadamente, resultando em uma experiência inferior para usuários de lago de dados e baixa qualidade de dados.
- Latência: O atraso entre o momento em que a mutação ocorre na tabela de origem e o momento em que ela está disponível para ser consultada no lago de dados é grande, diminuindo o frescor dos dados.
O Hudi contribui para a eficiência de nossos pipelines alimentados pelo DBEvents consumindo e aplicando apenas linhas e logs de alterações atualizadas de tabelas upstream.
Hudi melhora muitas das ineficiências que encontramos ao permitir atualizações incrementais em oposição a instantâneos, usando menos recursos de computação. Ao ler changelogs, o Hudi não precisa carregar tabelas inteiras, reduzindo assim a pressão nas fontes upstream.
A Figura 4, abaixo, descreve claramente como essas soluções funcionam juntas na arquitetura incremental de DBEvents. Na Uber, extraímos dados de várias fontes diferentes.
Cada origem possui uma implementação customizada para ler eventos do changelog e fornecer mudanças incrementais.
Por exemplo, changelogs do MySQL são rastreados e enviados para o Apache Kafka via StorageTapper, como descrito acima, enquanto changelogs do Cassandra são disponibilizados através de um recurso do Apache Cassandra chamado de captura de dados de mudança (CDC), juntamente com integrações específicas da Uber.
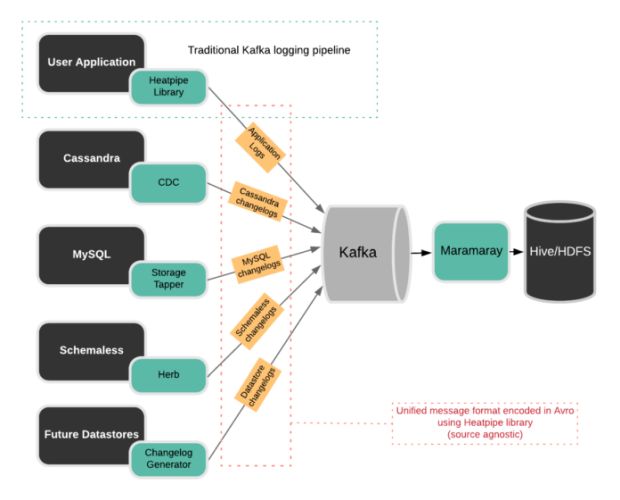
Marmaray é a biblioteca de código aberto de ingestão e dispersão de dados de uso geral da Uber. Em alto nível, a Marmaray fornece as seguintes funcionalidades para o nosso pipeline DBEvents, levando a uma maior eficiência de arquitetura:
- Produz dados esquematizados de qualidade por meio de nossa biblioteca e serviços de gerenciamento de esquemas.
- Ingere dados de vários armazenamentos de dados em nosso lago de dados do Apache Hadoop.
- Cria pipelines usando o serviço interno de orquestração de fluxo de trabalho da Uber para analisar e processar os dados ingeridos, bem como armazenar e calcular métricas de negócios com base nesses dados no HDFS e no Apache Hive.
Um único pipeline de ingestão executa o mesmo trabalho gráfico acíclico direcionado (DAG), independentemente da fonte de dados. Esse processo determina o comportamento de ingestão no tempo de execução, dependendo da origem específica, semelhante ao padrão de design da estratégia.
Padronizando eventos do Changelog
Um dos nossos objetivos era padronizar os eventos do changelog de uma maneira que pudesse ser usada por outros consumidores internos de dados, como trabalhos de streaming e pipelines personalizados.
Antes de padronizar os changelogs em DBEvents, precisávamos abordar algumas questões:
- Como podemos encontrar erros ao esquematizar a carga útil e como devemos lidar com eles?
- Uma carga útil pode ser complexa e apenas algumas partes da carga útil completa podem ser atualizadas. Como sabemos exatamente o que foi atualizado?
- Se essa carga útil for um changelog de uma mutação de linha em um banco de dados ou tabela upstream, qual é a chave primária da linha?
- Como estamos usando o Apache Kafka como um ônibus de mensagens para enviar e receber changelogs, como podemos impor o uso de timestamps crescentes para eventos em monotonia?
Para responder a essas perguntas para o caso de uso DBEvents, definimos um conjunto de cabeçalhos de metadados do Apache Hadoop que podem ser adicionados a cada mensagem do Apache Kafka. Com esse design, os metadados e os dados são codificados via heatpipe (usando o Apache Avro) e transportados pelo Apache Kafka.
Isso nos permite padronizar um conjunto global de metadados usados por todos os consumidores de tais eventos. Esses metadados descrevem cada atualização isoladamente e como essas atualizações se relacionam, de alguma forma, com fluxos anteriores de atualizações.
Os metadados também são gravados no Apache Hive em uma coluna especial chamada MetadataStruct, que segue um esquema de metadados. Um usuário pode, então, consultar facilmente o MetadataStruct e descobrir mais detalhes sobre o estado de uma linha.
Abaixo, destacamos alguns dos campos críticos de metadados que padronizamos em todos os eventos:
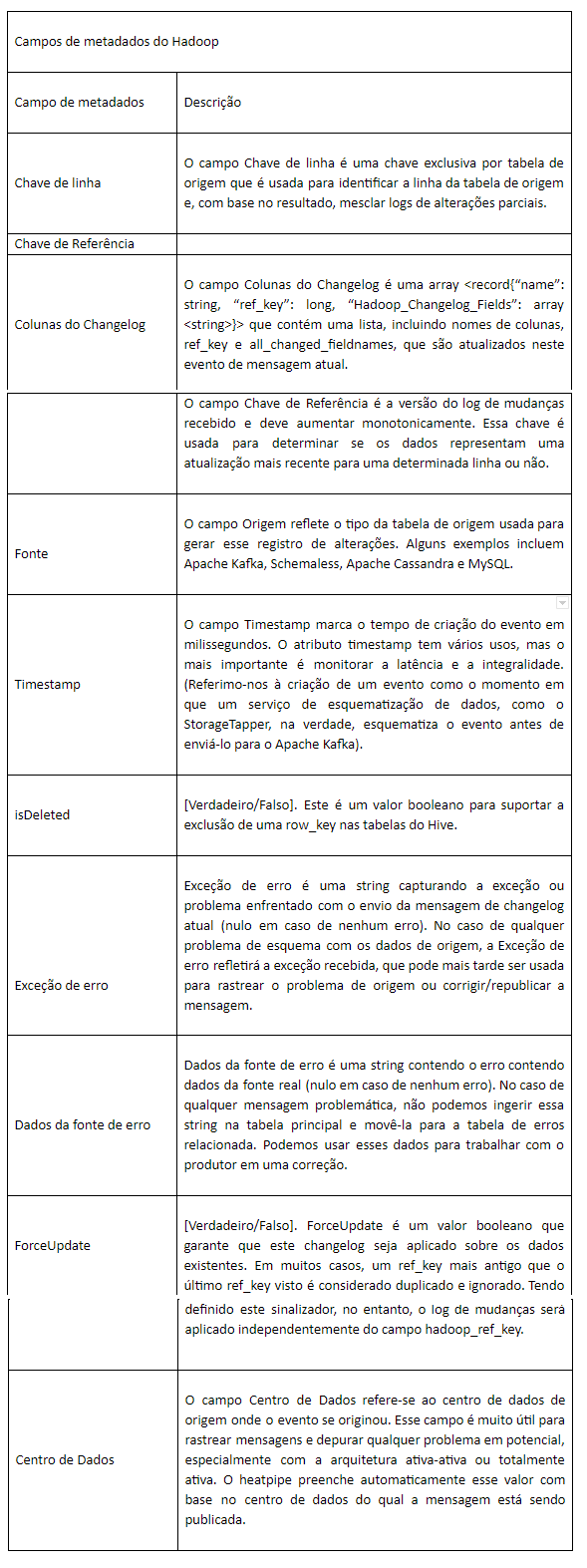
Metadados padronizados, como mostrado na tabela acima, tornam nossa arquitetura muito robusta e genérica. Esses metadados fornecem informações adequadas para entender completamente o estado de cada evento.
Por exemplo, se esquematizar ou decodificar o evento tiver algum problema, os campos de erro serão preenchidos, conforme mostrado na Figura 5, abaixo, e podemos decidir qual ação tomar. Na Uber escrevemos erros em uma tabela de erros juntamente com a carga real que resultou no problema.
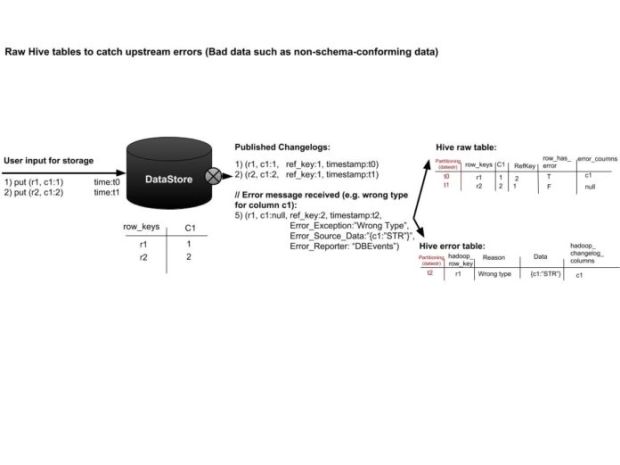
Tabelas de erro servem para muitos propósitos:
- Os produtores desses dados podem encontrar dados que não passaram nas verificações de esquema e, posteriormente, corrigir e publicar uma atualização.
- Operações e ferramentas de dados podem usar tabelas de erro para localizar e depurar dados perdidos.
- A gravação em tabelas de erros garante que não haja perda de dados no sistema e que todas as mensagens sejam contabilizadas na tabela real ou na tabela de erros.
Próximos passos
Com o fluxo de alterações incrementais disponíveis por meio de DBEvents, podemos fornecer dados mais rápidos, atualizados e de alta qualidade para o lago de dados. Usando esses dados, podemos garantir que os serviços da Uber, como o compartilhamento de corridas e o Uber Eats, funcionem da forma mais eficaz possível.
No futuro, pretendemos aprimorar o projeto com os seguintes recursos:
- Integração de autoatendimento: Queremos tornar a integração de um conjunto de dados ao Apache Hive extremamente fácil e simples. Para que isso aconteça, precisamos fazer alguns aprimoramentos no framework do DBEvents para que cada implementação de origem possa acionar o bootstrapping e a inclusão incremental de forma integrada. Isso requer integrações entre os sistemas de origem e ingestão, bem como integração com um framework de monitoramento de origem.
- Monitoramento de latência e integridade: Embora tenhamos os blocos de construção para fornecer essas informações, temos apenas uma implementação para o tipo de fonte de dados Apache Kafka. Gostaríamos de adicionar melhorias para produzir isso para todos os tipos de fonte de dados.
Se você trabalhar com computação distribuída e desafios de dados lhe interessa, considere candidatar-se a um cargo em nossa equipe!
***
Este artigo é do Uber Engineering. Ele foi escrito por Nishith Agarwal e Ovais Tariq. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/dbevents-ingestion-framework/


