



Criando análises de dados com o Presto e o Parquet na Uber

Desde determinar os pontos de encontro mais convenientes para o motorista até projetar o caminho mais rápido, o Uber utiliza análises orientadas por dados para criar experiências de viagens perfeitas. Dentro da engenharia, são analisados os processos de tomada de decisão. Conforme expandimos para novos mercados, a habilidade de agregar dados precisa e rapidamente se torna ainda mais importante.
No início de 2014, a Uber tinha apenas algumas centenas de funcionários ao redor do mundo. Mas no final de 2016, tínhamos mais de duas mil pessoas executando mais de cem mil consultas analíticas diariamente. Nós precisávamos de um sistema de consultas de dados que pudesse acompanhar nosso crescimento. Para executar as consultas analíticas em várias fontes de dados, nós desenvolvemos um sistema analítico que aproveita o Presto, um motor SQL distribuído open source para grandes conjuntos de dados, e o Parquet, um formato de armazenamento por colunas para o Hadoop.
Nesse artigo, nós resumimos a arquitetura do Presto e discutimos como desenvolvemos um novo leitor Parquet para potencializar as análises robustas de dados do Uber utilizando a mágica do armazenamento por colunas.
Utilizando o presto no Uber
Escolhemos o Presto como nosso motor SQL por sua escalabilidade, alta performance, e fácil integração com o Haddop. Essas propriedades o tornam bom para muitas de nossas equipes.
Arquitetura do Presto
O ecossistema do Presto na Uber é formado por uma variedade de nós que processam dados armazenados no Hadoop. Cada cluster Presto tem um nó “coordenador” que compila o SQL e agenda as tarefas, assim como, um número de nós “trabalhadores” que executam em conjunto as tarefas. Como detalhado na figura 1, o cliente envia as consultas SQL para nosso coordenador Presto, cujo analista compila o SQL em uma Árvore Sintática Abstrata (do inglês Abstract Sintax Tree – AST).
A partir daqui o planejador compila o AST em um planejamento de consultas, otimizando ele para um fragmentador que então segmentará o plano em tarefas. Então, o planejador atribui cada tarefa – ou ler arquivos do Sistema de Arquivos Distribuídos do Hadoop ou realizando agregações – para um trabalhador específico, e o nó gerente acompanha seu progresso. Finalmente, os resultados dessas tarefas são exibidos para o cliente.
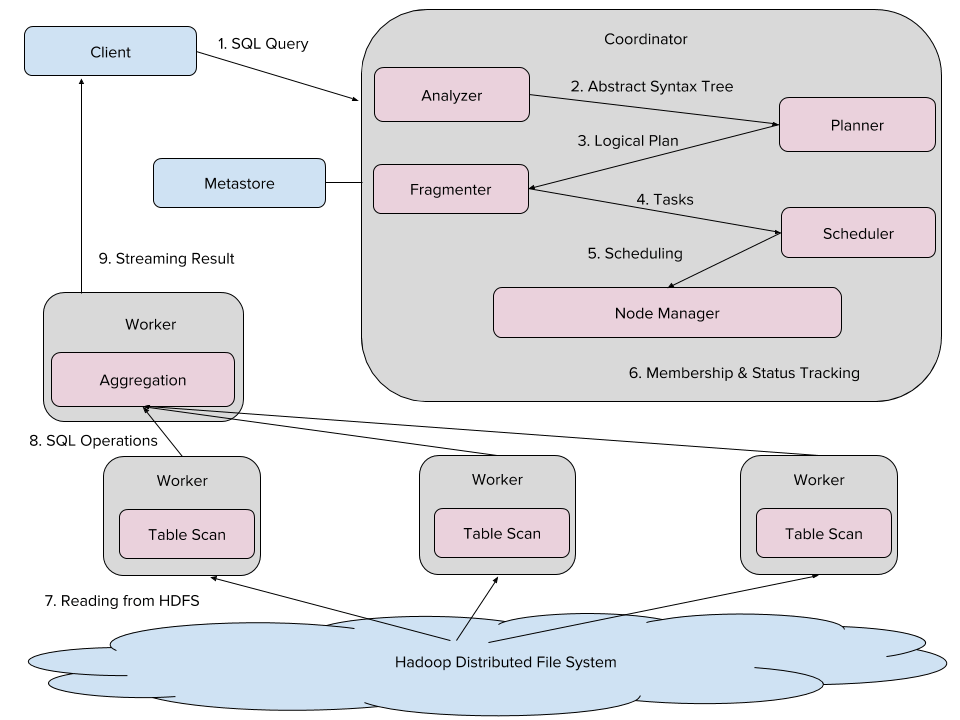
Infraestrutura e análise do Hadoop
Todos os conjuntos de dados analíticos na Uber são armazenados em nosso armazenamento Hadoop, incluindo registros de eventos replicados pelo Kafka, tabelas de arquitetura orientada a serviços construídas com MySQL e Postgres, e dados de viagens armazenados no Schemaless. Nós executamos o Flink, Pinot e MemSQL para análise e exibição em tempo real desses dados.
O Sistema de Arquivos Distribuídos do Hadoop é nosso data lake. Nesse ecossistema, os registros de eventos e dados de viagens são absorvidos utilizando ferramentas internas de absorção da Uber, e tabelas orientadas a serviços são copiadas para o sistema de arquivos do Hadoop via Sqoop. Com o Uber Hoodie, ferramenta de atualizações incrementais da Uber e uma biblioteca de inserção, primeiro os dados são depositados em nosso sistema de arquivos do Hadoop como arquivos brutos aninhados, e então algumas dessas tabelas brutas são convertidas em tabelas modeladas por meio de tarefas de extração, transformação e carregamento (do inglês Extract, Transform, Load – ETL). Enquanto os pacotes ETL são executados no Hive e no Spark, consultas interativas são executadas no Presto quase em tempo real.
Essa infraestrutura Hadoop robusta é integrada com os data centers da Uber, incorporando as funcionalidades existentes ativas de observação, segurança e gerenciamento de clusters.
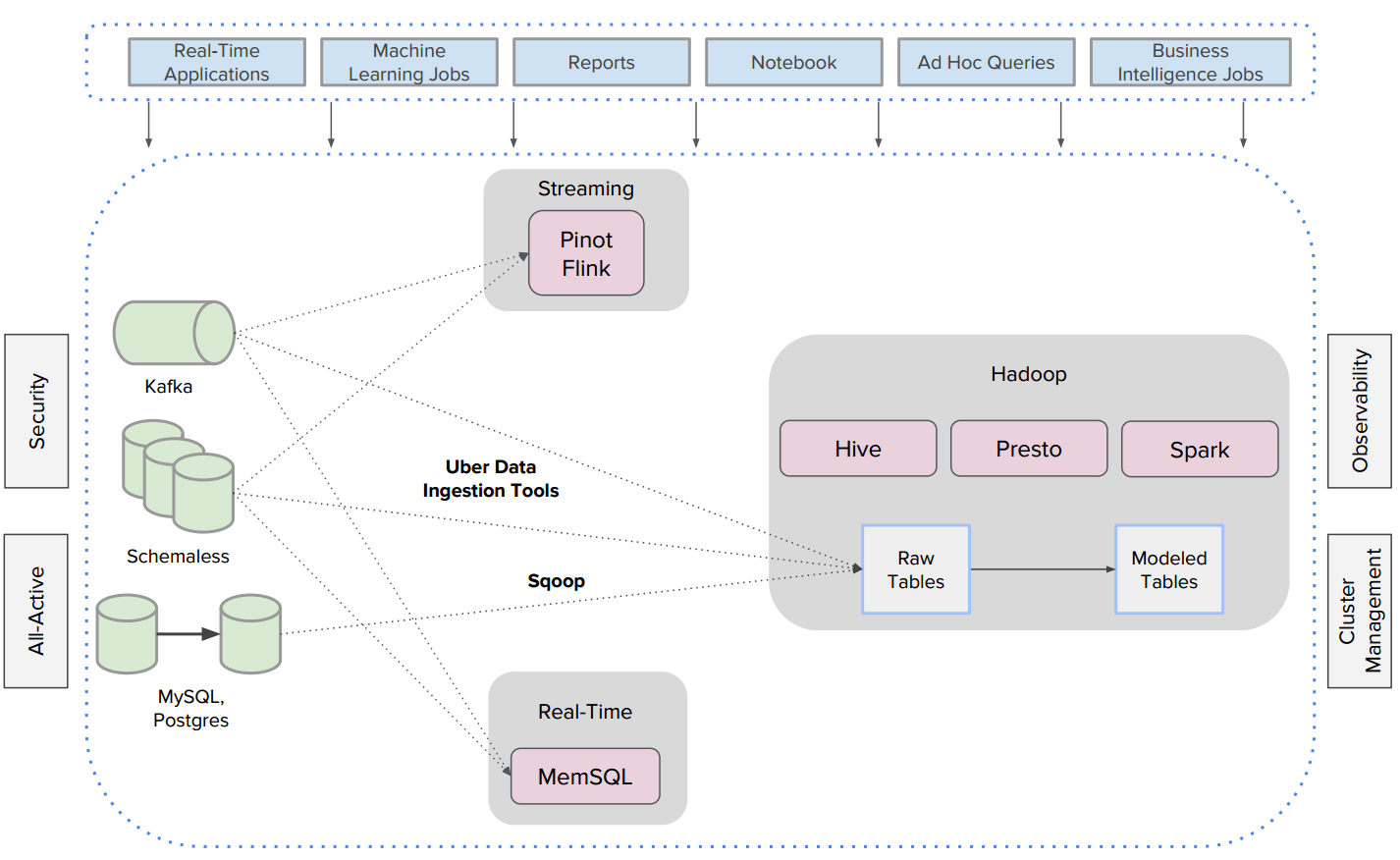
Armazenamento por colunas para fácil acesso
Os dados da Uber são depositados no sistema de arquivos do Hadoop e registrados como tabelas brutas ou modeladas, sendo que ambas podem ser consultadas pelo Presto.
As tabelas brutas não requerem processamento prévio e são altamente aninhadas; não é incomum vermos mais de cinco níveis de aninhamento. A latência para absorção das tabelas brutas é aproximadamente 30 minutos graças ao poder de processamento do Hoodie.
Por outro lado, as tabelas modeladas – que são acessadas com mais frequência – são mais cuidadosamente selecionadas e niveladas utilizando as tarefas ETL. A latência para a absorção das tabelas modeladas é muito maior, a maioria das tabelas modeladas tem uma latência que vai de 8 a 24 horas.
Devido à escala dos nossos dados e a necessidade de uma baixa latência para nossas analises, nós armazenamos os dados como colunas ao invés de linhas, o que permite ao Presto responder às pesquisas mais eficientemente. Por não precisar analisar e descartar dados indesejados em linhas, o armazenamento em colunas economiza espaço em disco e melhora a performance para conjuntos de dados maiores.
Envolvendo o Parquet
Nós escolhemos o Parquet para solução de armazenamento do Hadoop por suas funcionalidades de compressão e codificação, assim como por seu suporte aos conjuntos de dados aninhados. Essas funcionalidades permitem que nossos motores de consultas (incluindo o Presto) atinjam o pico de performance e velocidade de consulta.
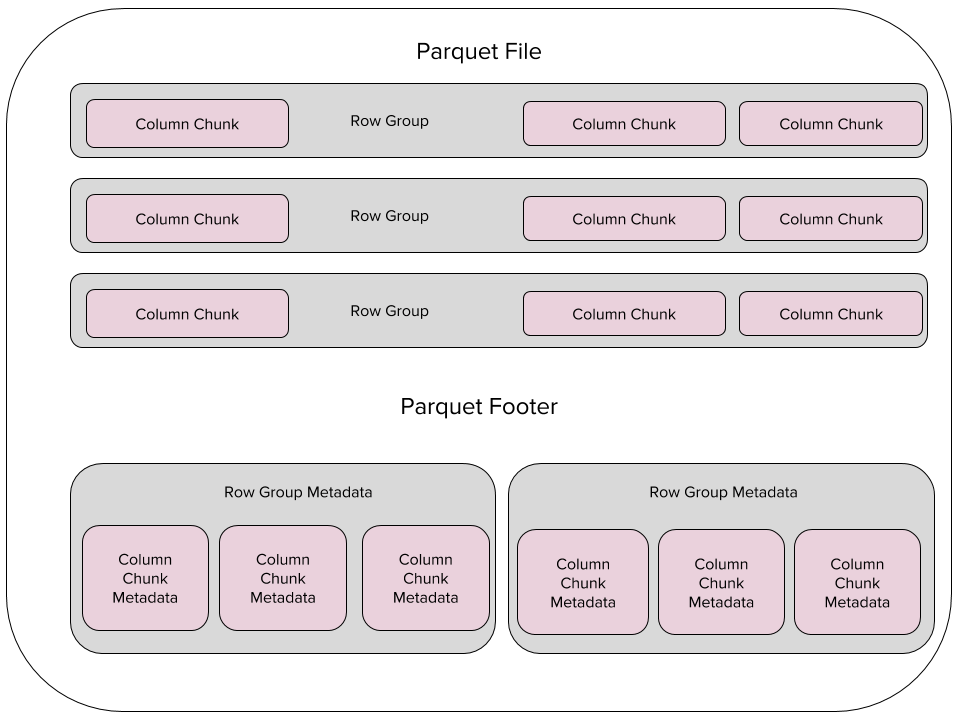
No Parquet, primeiro os dados são particionados horizontalmente em grupos de linhas, então dentro de cada grupo os dados são particionados verticalmente em colunas. Os dados para uma coluna particular são armazenados juntos, utilizando compressão e codificação para economizar espaço e melhorar a performance. Cada arquivo Parquet tem um rodapé que armazena os codecs, informação de codificação, bem como estatísticas em nível de colunas, ex.: os valores mínimo e máximo da coluna.
Em um nível teórico, o Paquet era a combinação perfeita para nossa arquitetura Presto, mas essa mágica suportaria as necessidades do nosso sistema em colunas?
Um novo leitor Parquet para o Presto
O Paquet é suportado pelo Presto utilizando o leitor original open source do Parquet. Mesmo funcionando bem com o Presto open source, esse leitor não incorpora completamente o armazenamento em colunas e não emprega otimizações de performance com as estatísticas dos arquivos do Parquet, tornando ele ineficiente para nosso caso de uso.
Para solucionar esse problema de performance, nós desenvolvemos um novo leitor de arquivos Parquet para o Presto, para aprimorar o potencial do Parquet em nosso sistema de análise de dados. Abaixo temos um exemplo de uma consulta para determinar quais motoristas temos como alvo em uma cidade específica, em uma certa data, baseados na demanda esperada por motoristas.
SELECT base.driver_uuid FROM rawdata.schemaless_mezzanine_trips_rows WHERE datestr = ‘2017-03-02’ AND base.city_id in (12)
Nesse cenário, a tabela aninhada rawdata.schemaless_mezzanine_trips_rows armazena mais de 100 terabytes de dados brutos de viagens no Parquet. Utilizando o exemplo acima, nós vamos demonstrar como as consultas são processadas utilizando tanto o leitor original open source quanto o leitor open source que criamos.
Leitor Parquet open source original
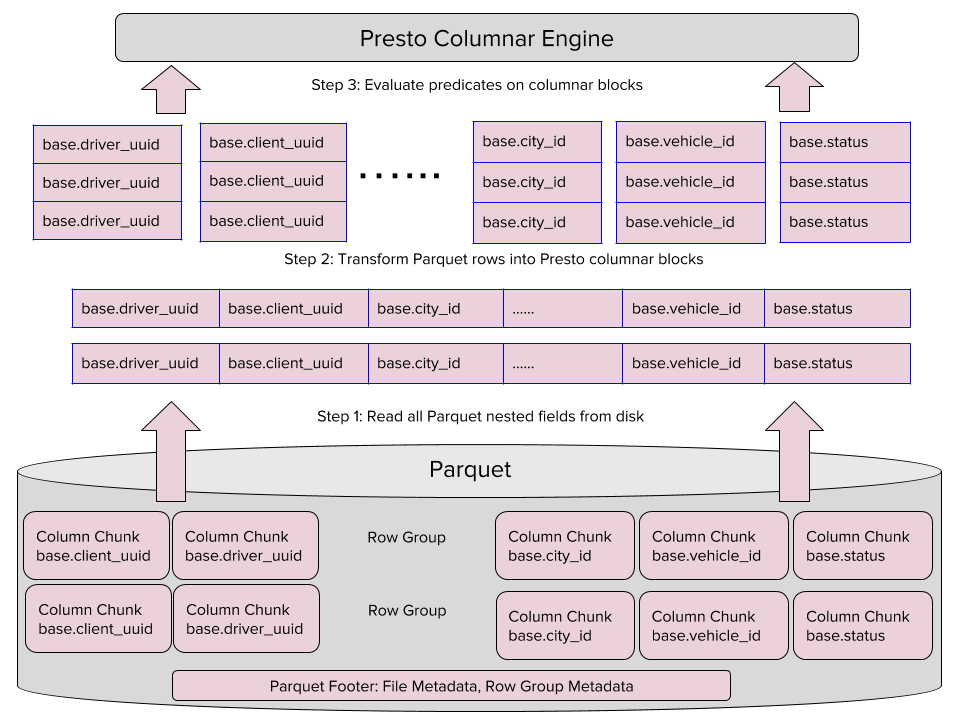
O leitor original realiza as consultas em três passos:
- lê todos os dados no Parquet, linha a linha, utilizando a biblioteca open source Parquet;
- transforma os registros Parquet de registros em linha para blocos em colunas do Presto na memória, para todas as colunas aninhadas;
- avalia a declaração (base.city_id=12) nesses blocos, executando as consultas em nosso motor Presto.
Novo leitor Parquet da Uber
Para acomodar o tamanho e a escala dos dados da Uber, nós criamos um novo leitor Parquet open source que utiliza a memória e a CPU com mais eficiência. Esse novo leitor implementa quatro otimizações orientadas a melhorar a performance e aumentar a velocidade das consultas.
Redução de colunas aninhadas
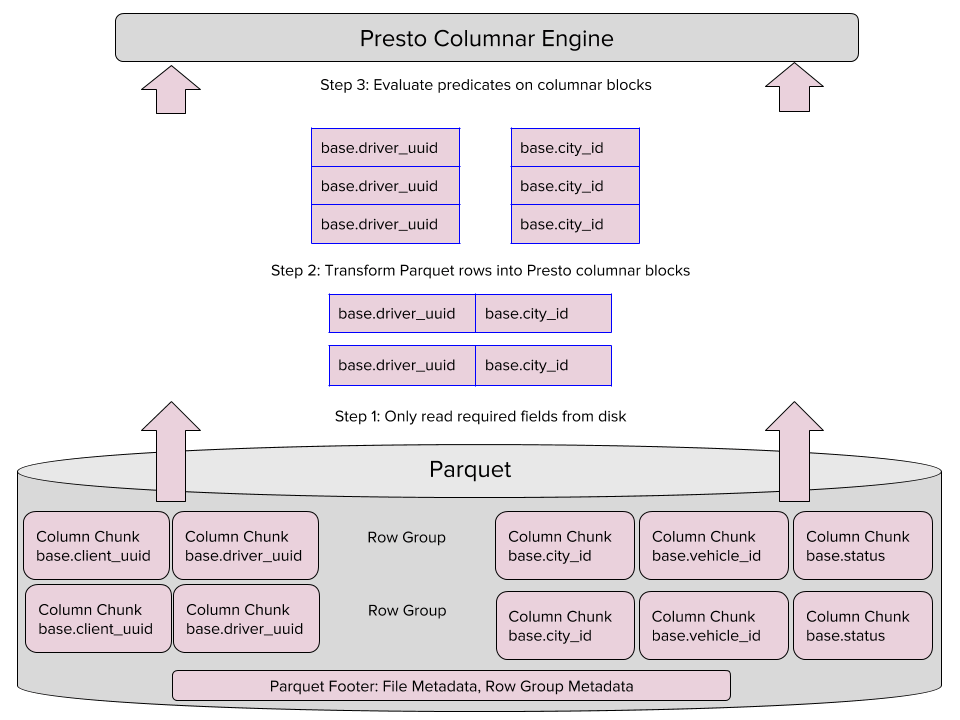
Uma maneira do leitor otimizar as consultas é pulando os dados desnecessários, chamado de redução de colunas aninhadas. Como o nome sugere, essa otimização é mais efetiva quando utilizada em dados aninhados.
O novo leitor executa a redução de colunas aninhadas em três passos:
- lê somente as colunas necessárias no Parquet;
- transforma os registros Parquet em linha para blocos em colunas;
- avalia a declaração nesses blocos, no motor Presto.
Leitura de colunas
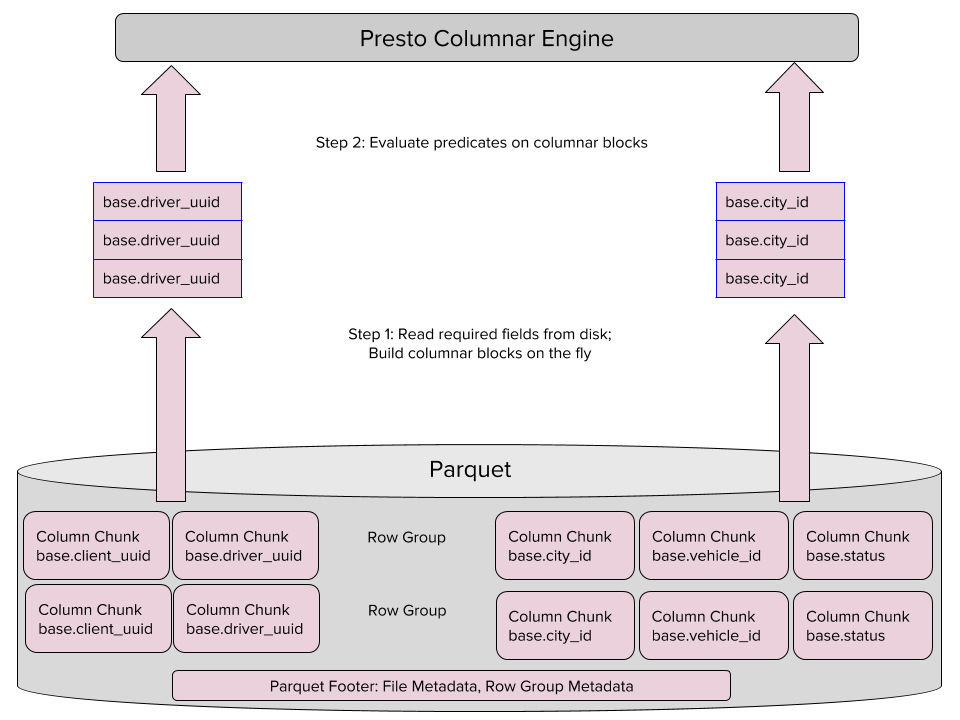
O novo leitor também pode ler colunas diretamente no Parquet ao invés de ler linha por linha, e então executar a transformação de linha para coluna, o que aumenta a velocidade das consultas. Ele executa as leituras em dois passos:
- lê somente as colunas necessárias no Parquet e constrói os blocos de colunas automaticamente, economizando CPU e memória para transformar os registros em linhas, em blocos em colunas;
- avalia a declaração utilizando os blocos de colunas no motor do Presto.
Lista de declarações
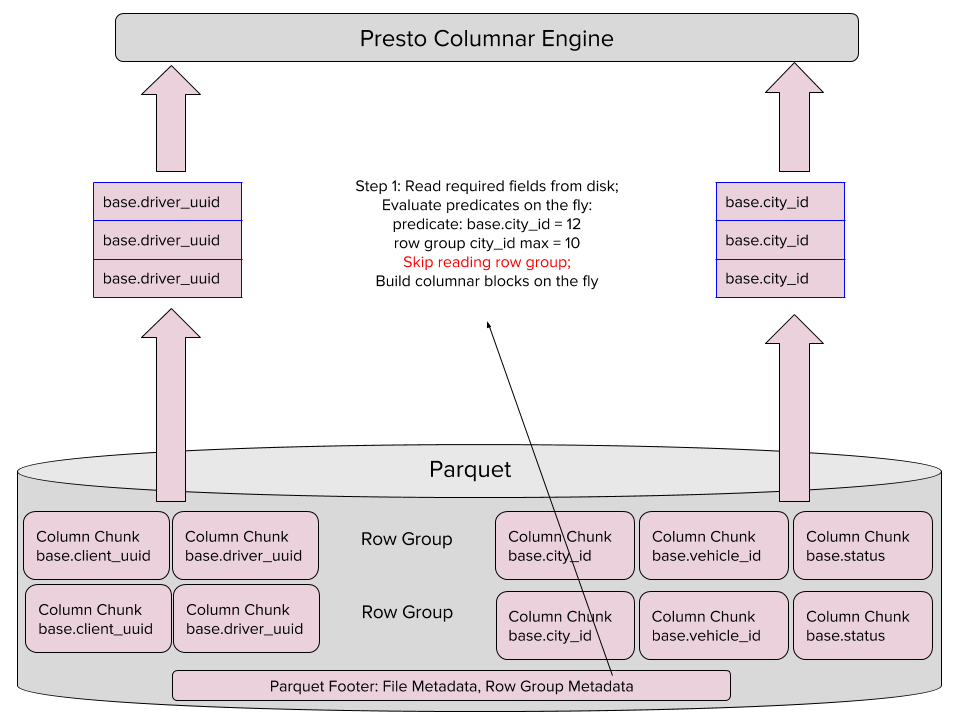
Com nosso novo leitor, podemos avaliar declarações SQL enquanto analisamos os arquivos Parquet. Utilizando as estatísticas do Parquet, podemos também pular a leitura de partes dos arquivos, dessa maneira, economizando memória e agilizando o processamento. As listas de declarações são utilizadas primariamente para consultas “agulha em um palheiro”.
O novo leitor executa as listas de declarações combinando três ações em um único passo: simultaneamente lê as colunas necessárias no Parquet, avalia as declarações das colunas automaticamente, e constrói blocos de colunas. Nesse cenário, o leitor pula a leitura do grupo de linhas que a declaração não for compatível com a consulta.
Lista de dicionários
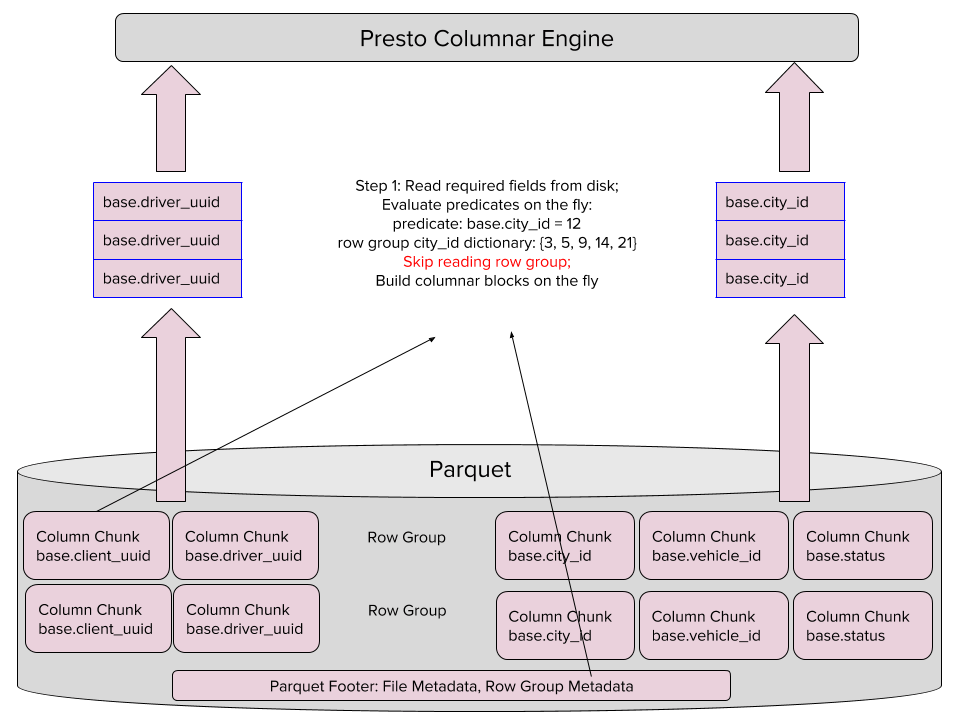
Mesmo se as estatísticas do Parquet forem compatíveis com a busca, podemos ler a página do dicionário, para cada coluna, para determinar se o dicionário pode potencialmente ser compatível com a busca. Se não for, podemos pular a leitura desse grupo de linhas. Como as listas de declarações, as listas de dicionários tornam a busca mais rápida e mais efetiva para as consultas “agulhas em um palheiro”.
As listas de dicionários também são executadas por nosso leitor em um único passo: lê as colunas necessárias no Parquet, avalia as declarações das colunas automaticamente e constrói blocos de colunas. Semelhante às listas de declarações, as listas de dicionários possibilitam que o leitor pule grupos de linhas se os valores do dicionário não forem compatíveis com a consulta.
Leitura Preguiçosa
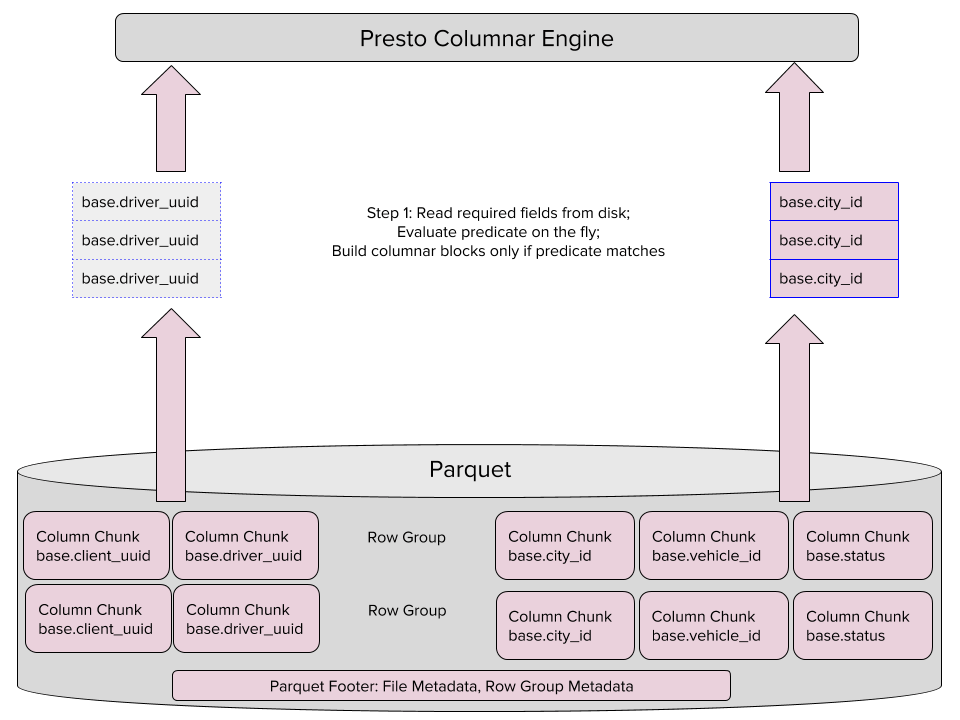
Nosso leitor também pode ser programado para ler as colunas projetadas da maneira mais preguiçosa possível. Isso significa que nós leremos as colunas projetadas somente quando elas forem compatíveis com a declaração, dessa maneira, acelerando nossa busca.
As leituras preguiçosas são executadas em um único passo: lê as colunas necessárias no Parquet, avalia as declarações das colunas automaticamente, e constrói os blocos de colunas apenas se a declaração for compatível.
Todas as 4 otimizações são únicas para o leitor Parquet da Uber, garantindo a utilização eficiente do nosso armazenamento e análise de dados. Desde que colocamos nosso novo leitor Parquet em produção, os dados são processados entre 2 e 10 vezes mais rapidamente em comparação com a utilização do leitor original open source.

Trabalho em andamento
Com o tempo, o Presto emergiu como um componente chave para análise das nossas consultas SQL interativas para big data em escala. Desde a implementação em 2016, o cluster Presto excedeu 300 nós, é capaz de acessar mais de cinco petabytes de dados, e completa mais de 90% das consultas dentro de 60 segundos. Quem precisa tirar um coelho da cartola quando temos uma mágica dessas em nossa pilha tecnológica?
Mesmo com essas métricas, nossa equipe ainda está ativamente melhorando a confiabilidade, escalabilidade e performance do Presto, para tornar nossa análise de dados o mais eficiente possível. Os esforços em andamento incluem: um conector Elasticsearch para o Presto, gerenciamento de recursos “multi-tenancy”, alta disponibilidade dos coordenadores Presto, suporte para função geo espacial e melhoramento de performance, e armazenamento no sistema de arquivos Hadoop.
***
Este artigo é do Uber Engineering. Ele foi escrito por Zhenxiao Luo. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/presto/


