

No meu trabalho, eu estou sempre bem próximo dos desenvolvedores, exatamente para ajudar e orientar os profissionais no sentido de adotar melhores práticas de acesso aos bancos de dados.
Um assunto que sempre entra na discussão é a “equivalência” entre os comandos de manipulação de dados, que nós DBAs chamamos de DML: INSERT, UPDATE e DELETE. A tal equivalência aqui se refere ao custo de execução de cada um desses comandos e, por esse critério, muita gente assume que não haveria grande impacto de se usar um comando ou outro.
Pessoalmente, eu não gosto da ideia de se usar o comando UPDATE com muita frequência. Para mim, isso é um retrabalho nos dados. Na grande maioria das vezes, o registro pode ser tratado adequadamente na operação de INSERT. Se a aplicação obriga que um registro seja atualizado frequentemente, é um sinal de que a modelagem do banco não foi devidamente estudada.
O fato é que a realidade é mais complicada do que gostaríamos. A própria comparação dos comandos DML envolve uma série de parâmetros. Precisamos especificar qual SGBD é usado, qual tipo de comando está sendo executado e qual o tipo de índice existe na tabela.
A seguir, eu apresento o plano de execução de 3 comandos DML (INSERT, UPDATE, DELETE) executados no SQL Server 2008 R2 em uma tabela sem índices afetando um único registro em cada operação. O mesmo número de campos (3) é tratado tanto no INSERT como no UPDATE.
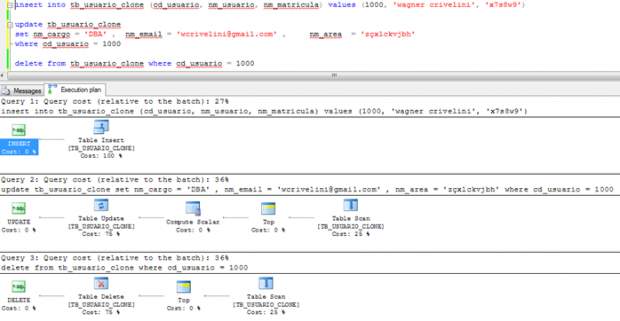
Eu usei também o SHOWPLAN_ALL para ver o custo estimado de cada consulta
set showplan_all on
| COMANDO | CUSTO ESTIMADO | CUSTO % |
| insert | 0,01000216 | 27,3% |
| update | 0,01328420 | 36,3% |
| delete | 0,01328410 | 36,3% |
Observe o custo relativo de cada consulta sobre o custo total do “batch”: a consulta 1 (INSERT) representa 27% do custo total. As outras (2 e 3, ou UPDATE e DELETE, respectivamente) têm o mesmo custo e representam cada uma 36% do total. Portanto, nesse cenário onde não se usam índices, o comando INSERT é 33% mais rápido que os comandos UPDATE ou DELETE (0,36/0,27).
Agora mostro o mesmo teste usando um índice clusterizado na tabela.
[sql]
alter table tb_usuario_clone
add constraint pk_clone
primary key clustered (cd_usuario)
[/sql]
A expectativa é que houvesse um custo maior para inserir um registro na tabela, porque o registro deveria ser inserido de tal modo que respeitasse a sequência de valores definida por esse índice. Inversamente, era de se esperar que os comandos DELETE e UPDATE fossem mais rápidos, uma vez que o otimizador de consultas poderia usar o novo índice para localizar o registro desejado.
Mas todas essas expectativas estão furadas. O otimizador de consultas do SQL Server 2008 R2 usa o novo índice, como se vê no plano de execução. Mas as estimativas de custo dos 3 comandos continuam exatamente iguais.
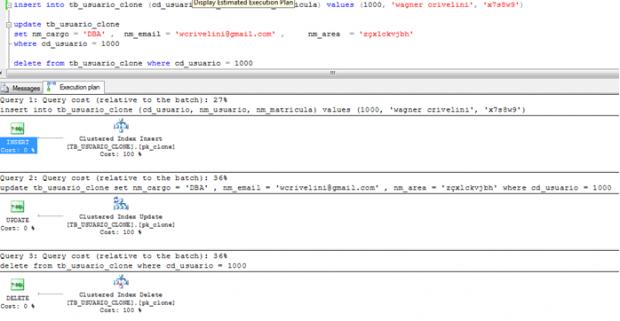
set showplan_all on
| COMANDO | CUSTO ESTIMADO | CUSTO % |
| insert | 0,01000216 | 27,3% |
| update | 0,01328420 | 36,3% |
| delete | 0,01328410 | 36,3% |
Os números mostram novamente que o comando INSERT apresenta menor custo que UPDATE e DELETE, mesmo havendo um índice na tabela. O fato de termos exatamente as mesmas estimativas de custo com e sem índices é até surpreendente e merece um estudo mais detalhado. Porém, essa questão vai além do objetivo deste artigo e deixo essa avaliação a cargo do leitor.
Como se vê, o comando INSERT tem menor custo de execução do que UPDATE ou DELETE, independentemente de a tabela conter índices ou não. É fácil concluir que não é uma boa prática usar comandos INSERT sem o devido cuidado de registrar valores para todos os campos possíveis. O uso dos comandos UPDATE e DELETE, além de representar um retrabalho com o registro, são ainda mais pesados do que a inserção de um novo registro. Além do mais, devemos lembrar que a execução de todo os 3 comandos é registrada no log do banco de dados e, portanto, o uso de comandos extras representa também mais consumo de espaço em disco.
Essas questões precisam ser avaliadas desde a modelagem do banco de dados para que se possa garantir uma aplicação que contenha os dados desejados e funcione de forma otimizada. Veja o caso do status de um pedido, por exemplo. Em vez de se criar um modelo que obrigue a atualização de um campo STATUS da tabela PEDIDO, seria mais interessante criar uma segunda tabela (PEDIDOSTATUS) com os campos código do pedido, data e status. Nesse caso, só faremos INSERTs na segunda tabela e ainda teremos o benefício de manter um histórico desse pedido.
Obviamente deve-se avaliar o espaço em disco necessário para armazenamento dos dados da tabela PEDIDOSTATUS, que tende a crescer rapidamente. Mas essa alternativa representa menos processamento no servidor, além manter um histórico dos status de pedido que de outra forma seria perdido. Hoje o custo de disco é muito baixo se comparado à importância de se ter dados da aplicação. E manter um histórico dos status de pedido pode ser muito útil para empresa.
São pequenos detalhes como esse que garantem a operação ótima de um banco de dados. E, no exemplo citado, ainda oferecem mais informação para a administração da empresa.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?