

Nesse novo artigo sobre geração de relatórios com dados sumarizados, o foco é o volume de dados. No cenário que descrevo aqui, o problema é que a base de dados ficou tão grande que nem mesmo a visão indexada consegue oferecer uma performance adequada.
Cada empresa tem seu próprio padrão do que é aceitável para o tempo de resposta de um relatório sumarizado, mas é comum aceitarmos respostas na ordem de alguns segundos. Mas quando se passa do limite reconhecido como aceitável, é hora de ligar o alerta.
“Houston, temos um problema”!
Volume dados como fator limitante
Sempre (ou quase) existe a alternativa de usar força bruta para resolver problemas de performance. Isto significa escalar para uma máquina maior, com maior poder de processamento e/ou memória e ao mesmo tempo usar unidades de armazenamento mais rápidas.
Mas na maioria dos casos é mais barato usar a inteligência em lugar de força bruta, isto é, aproveitar os recursos oferecidos pelo seu sistema gerenciador de bancos de dados ao invés de aumentar a capacidade do hardware.
O SQL Server, por exemplo, oferece vários desses recursos e é importante conhecer a função de cada um deles. Por exemplo: as tabelas em memória são um recurso fantástico, mas não se deixe levar pelo nome bacana. Elas foram idealizadas para ajudar em cenários que envolvem alto volume de transações e alta concorrência. Sendo assim, elas se destinam a ajudar na escrita no banco, não na leitura. Tanto é que o nome da funcionalidade é InMemory OLTP.
Para melhorar performance na sumarização de grandes volumes de dados, uma alternativa muito interessante são os índices ColumnStore. Eles armazenam e tratam os dados num formato colunar, diferente da ideia padrão de lidar com dados na forma de registros (ou seja, linhas). Mas, como sempre, não existe lanche grátis. Estes índices costumam oferecer resultados excepcionais para agregação de dados em tabelas físicas, mas eles vão bem apenas em tabelas grandes que não costumam sofrer atualizações de dados frequentes. As operações de INSERT, DELETE e principalmente UPDATE ficam muito mais lentas em tabelas que usam este tipo de índice.
Por isso, esses índices são mais apropriados para Data Warehouses, particularmente nas tabelas fato. Salvo exceções muito bem definidas, eu não recomendaria seu uso em tabelas transacionais.
Planejando a Criação do Ambiente de Testes
Para mostrar o uso deste índice, é necessário antes de tudo aumentar muito o tamanho das tabelas envolvidas.
No artigo anterior eu mostrei a eficiência da visão indexada num ambiente em que a tabela de linhas da ordem de compra tinha pouco mais de 137 milhões de registros. Desta vez eu tive que aumentar esta tabela por um fator de 16. Vejo a tabela a seguir.
| Table Name | # Records | Reserved (KB) | Data (KB) | Indexes (KB) | Unused (KB) |
| Purchasing PurchaseOrderLines | 2.193.358.848 | 266.433.048 | 265.180.440 | 1.251.448 | 1.160 |
| Purchasing PurchaseOrder | 543.686.656 | 65.494.424 | 65.329.208 | 154.424 | 10.792 |
A geração dos dados de teste é bastante simples: importei os dados de algumas tabelas da base demo WIDEWORLDIMPORTERS e depois executei INSERTs várias vezes na mesma tabela, duplicando a quantidade de registros a cada rodada. O script completo com todas as instruções para preparação dos dados e execução dos testes está disponível aqui.
Apesar de simples, o processo é pesado. São necessárias muitas horas de processamento e o resultado é uma base de dados que passa dos 500 Gb. Solucionei esta questão usando uma infraestrutura adequada para realizar os meus testes: criei uma máquina virtual no AZURE rodando SQL Server 2016 com espaço em disco, memória e poder de processamento adequados a este trabalho. Tudo muito simples e rápido. Para quem nunca tentou trabalhar no AZURE como IAAS (Infrastructure As A Service), recomendo a leitura desta página.
Após gerar a massa de dados, precisei fazer uma alteração adicional. Como os testes propostos aqui se destinam a analisar desempenho de consultas sobre dados sumarizados, não basta apenas que a base transacional cresça. O objeto usado na geração dos relatórios também precisa crescer. Mesmo que a tabela fonte estivesse lidando com mais de 2 bilhões de registros, a visão indexada destes dados sumarizados por dia gerava uma massa que não chegava a 1 milhão de registros.
Por isso alterei o tipo de dados do campo OrderDate, que foi mudado de DATE para SMALLDATETIME. Esta mudança permitiu aumentar a granularidade da data da ordem de dias para segundos. Em seguida, alterei os valores deste campo aleatoriamente. Com esta mudança, a massa de dados sumarizados cresceu para mais de 150 milhões de registros.
Comparando Resultados
Para avaliar estes dados sumarizados, criei uma visão indexada e uma tabela com um índice ColumnStore clusterizado, como mostra a listagem a seguir:
-- =========================================== -- visao indexada -- =========================================== CREATE VIEW ixView.vwRelatorioCompras WITH SCHEMABINDING AS SELECT C.SupplierCategoryName AS Category , S.SupplierName AS Supplier , I.StockItemName AS Item , O.OrderDate , SUM( L.OrderedOuters ) AS Ordered , SUM( L.ReceivedOuters) AS Received --, SUM( L.OrderedOuters ) - SUM(L.ReceivedOuters) AS ToBeDelivered , COUNT_BIG(*) AS NumRecords FROM [Purchasing].[Suppliers] S INNER JOIN [Purchasing].[SupplierCategories] C ON S.SupplierCategoryID = C.SupplierCategoryID INNER JOIN [Purchasing].[PurchaseOrders] O ON S.SupplierID = O.SupplierID INNER JOIN [Purchasing].[PurchaseOrderLines] L ON O.PurchaseOrderID = L.PurchaseOrderID INNER JOIN [Warehouse].[StockItems] I ON L.StockItemID = I.StockItemID GROUP BY C.SupplierCategoryName , S.SupplierName , I.StockItemName , O.OrderDate GO CREATE UNIQUE CLUSTERED INDEX ixRelatorioCompras ON ixView.vwRelatorioCompras (Category, Supplier, Item, OrderDate) GO -- =========================================== -- tabela com índice ColumStore clusterizado -- =========================================== CREATE TABLE [colStore].[tbRelatorioCompras]( [Category] [nvarchar](50) NOT NULL, [Supplier] [nvarchar](100) NOT NULL, [Item] [nvarchar](100) NOT NULL, [OrderDate] [smalldatetime] NOT NULL, [Ordered] [bigint] NOT NULL, [Received] [bigint] NOT NULL, [NumRecords] [bigint] NOT NULL ) GO CREATE CLUSTERED COLUMNSTORE INDEX cciRelatorioCompras ON [colStore].[tbRelatorioCompras] GO INSERT INTO [colStore].[tbRelatorioCompras] SELECT * FROM ixView.vwRelatorioCompras GO
Observe que, no segundo caso, eu criei uma tabela, defini um índice ColumnStore clusterizado e em seguida eu fui obrigado inserir dados nela. Diferentemente da visão indexada, esta é uma tabela como qualquer outra e ela não tem nenhum vínculo com outros objetos do banco. Por isso é necessário mover dados para a nova tabela periodicamente.
Assim como um índice clusterizado normal (B-Tree), criar um índice ColumnStore clusterizado em uma tabela, significa dizer que se está definindo que a tabela inteira será gravada fisicamente no formato ColumnStore.
Isso traz implicações interessantes. Em primeiro lugar, o armazenamento ColumnStore é muito diferente, usando a ideia de rowgroups ao invés de páginas de dados. Veja no quadro abaixo que o espaço em disco ocupado pela tabela com índice ColumnStore clusterizado representa apenas 3% do usado pela visão indexada (que usa um índice B-Tree clusterizado).
| Table Name | # Records | Reserved (KB) | Data (KB) | Indexes (KB) | Unused (KB) |
| IxView.vwRelatorioCompras | 156.424.596 | 31.701.984 | 30.974.824 | 727.112 | 48 |
| colStore.tbRelatorioCompras | 156.424.596 | 985.488 | 941.352 | 0 | 44.136 |
Quando falamos de performance, o resultado também é surpreendente. Executei uma consulta idêntica nos dois objetos, retornando exatamente o mesmo resultado. Porém o custo de execução da consulta e o tempo de resposta foram dramaticamente menores quando usei o índice ColumStore: resultados representam só 3 a 4% do custo e tempo de resposta obtidos com a visão indexada!
Declaração:
--teste 1: visão indexada SELECT Supplier, SUM(Ordered) AS TotalOrderedQty FROM ixView.vwRelatorioCompras WHERE Category = 'Novelty Goods Supplier' GROUP BY Supplier
Custo de execução:
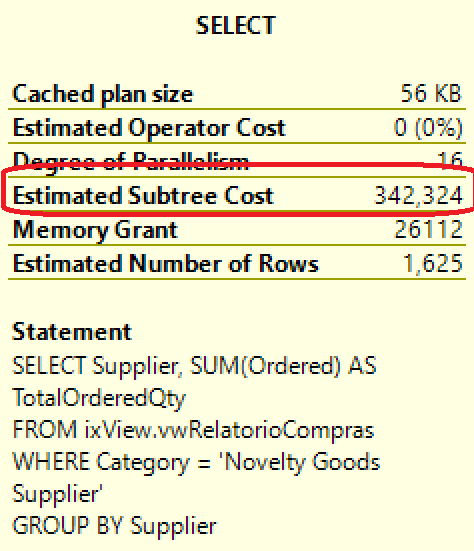
Tempo de execução:
- 24 segundos
Declaração:
-- teste 2: índice ColumnStore SELECT Supplier, SUM(Ordered) AS TotalOrderedQty FROM colStore.tbRelatorioCompras WHERE Category = 'Novelty Goods Supplier' GROUP BY Supplier
Custo de execução:
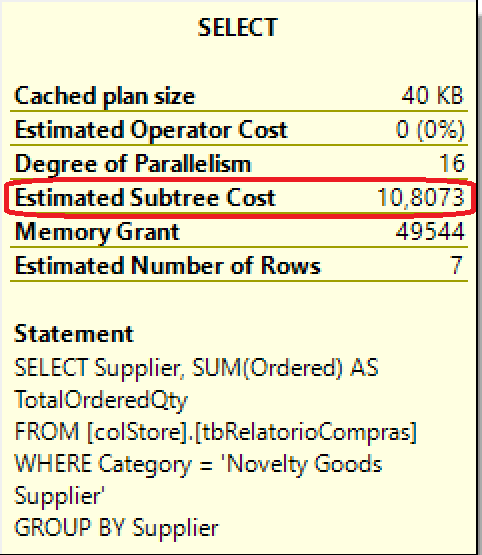
Tempo de execução:
- < 01 segundo
Considerações sobre Implementação
O resultado oferecido pelos índices ColumnStore é impressionante, mas é importante observar que atualmente não é possível criar índices ColumnStore em visões indexadas. Portanto existem custo e limitações para o uso de índices ColumnStore:
- A tabela sempre mostrará uma fotografia dos dados e não dados em tempo real.
- É necessário criar um pacote para movimentação das tabelas transacionais para a tabela.
- Este pacote deve ser executado periodicamente conforme conveniência e praticidade, por exemplo, de hora em hora ou uma vez ao dia.
- Esta movimentação de dados precisa ser monitorada e auditada
- Estes índices não devem ser usados em tabelas transacionais, pois eles são muito lentos em operações que envolvam atualização, inserção e exclusão de dados.
Com os devidos cuidados, porém, índices ColumnStore podem oferecer uma performance muito superior em aplicações que envolvam análise de dados.
Leituras Sugeridas
- ColumnStore indexes – overview por Barbara Kess & Craig Guyer.
- CREATE COLUMNSTORE INDEX (Transact-SQL) por MICROSOFT.
- What You Can (and Can’t) Do With Indexed Views por Jes Schultz Borland.
- SQL Server In-Memory OLTP and ColumnStore Feature Comparison por Jos de Bruijn e outros.
Este artigo expressa opiniões pessoais do autor.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?