

Continuando a série sobre sumarização de dados, trataremos agora de um novo caso onde o foco é performance.
Quando a performance é elemento crítico
Na medida em que o banco de dados vai crescendo, eventualmente o uso de visões comuns deixa de ser eficiente. Não é raro observarmos objetos que rodavam num tempo adequado e que aos poucos deixaram de apresentar um desempenho aceitável.
Isso acontece quando uma ou mais tabelas referenciadas no código da visão crescem demais. É comum que algumas tabelas fiquem tão grandes que os índices existentes não são capazes de garantir uma boa performance.
Quando este tipo de problema afeta muitas operações (e não apenas uma única visão) podemos analisar estratégias de particionamento das tabelas em questão. Isso pode ajudar caso se consiga definir um critério de particionamento em que uma única partição forneça todos os dados necessários. Em outras palavras: particionamento pode ajudar, mas não resolve os casos de relatórios com dados históricos, que continuariam a buscar dados em várias partições.
Caso o problema atinja apenas algumas consultas, talvez seja hora de pensar na adoção das visões indexadas, também conhecidas como visões materializadas.
O que são visões indexadas
As visões indexadas são usadas com frequência nos casos em que a consulta envolve tabelas gigantes. Na prática, a visão indexada se comporta como uma tabela, tendo inclusive um índice clusterizado. Isso significa que os dados são efetivamente gravados em disco e ordenados com base no(s) campo(s) indexado(s).
Existem diversos pré-requisitos para a criação de visões indexadas (veja o artigo da Jes Schultz Borland nas Leituras Sugeridas). Para citar alguns, eu destacaria as seguintes restrições:
- Elas só podem referenciar tabelas físicas (nunca outras visões)
- Todas as tabelas usadas devem estar no mesmo banco de dados
- A estrutura destas tabelas não pode ser alterada (opção SCHEMABINDING)
- As tabelas fontes não podem incluir certas funcionalidades especiais
- Caso a visão faça agregação de dados, deve-se observar ainda:
a. Que a visão inclua uma coluna que use a função COUNT_BIG();
b. Que a visão não inclua a cláusula HAVING;
c. Que a visão não inclua colunas com expressões envolvendo resultado de funções de agregação.
O exemplo a seguir usa a base demo WideWorldImporters e ilustra as dificuldades que temos para criar uma visão indexada. Apesar da sintaxe do script estar correta, a operação falha no momento de criar o índice. Observe atentamente a listagem a seguir:

Note que o script gerou uma mensagem de erro muito sutil. A sintaxe está correta, a visão foi criada, mas mesmo assim não foi possível gerar um índice nesta nova visão.
Isso porque uma das tabelas envolvidas (Purchasing.Suplliers) inclui colunas mascaradas. Tais colunas nem fazem parte da consulta, mas ainda assim não é possível criar o índice desta visão.
Mesmo que eu remova as máscaras destes campos (que são BankAccountName, BankAccountBranch, BankAccountCode, BankAccountNumber e BankInternationalCode), ainda terei problemas em razão do tipo de consulta que define a visão. Preciso necessariamente atender as restrições das consultas de agregação.
Então, depois das devidas alterações de código, finalmente posso criar minha visão indexada, como mostra o script abaixo:
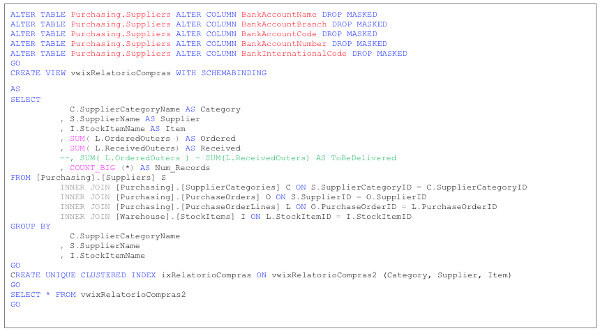
Analisando desempenho das visões indexadas
Apesar das exigências, vale a pena usar visões indexadas quando trabalhamos com tabelas realmente grandes.
Para comprovar esta afirmação, criei uma base de testes e construí tabelas com estrutura semelhante às tabelas originais da base WideWorldImporters. Porém aqui eu preparei um script para geração de uma massa de dados maior, levando a tabela de itens da ordem de compra a crescer para cerca de 140 milhões de registros. Veja detalhes no relatório a seguir:
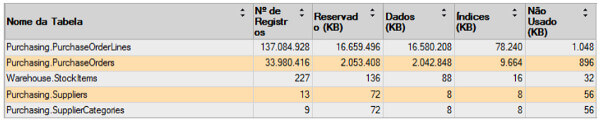
OBS: o script completo para criação da base, tabelas e importação de dados está disponível neste link.
Executei duas consultas equivalentes, uma usando as tabelas originais e a segunda usando a visão indexada. O resultado de ambas é exatamente igual. O objetivo é comparar os planos de execução dessas consultas.
A primeira consulta busca os dados diretamente nas tabelas, conforme apresentado no quadro a seguir.
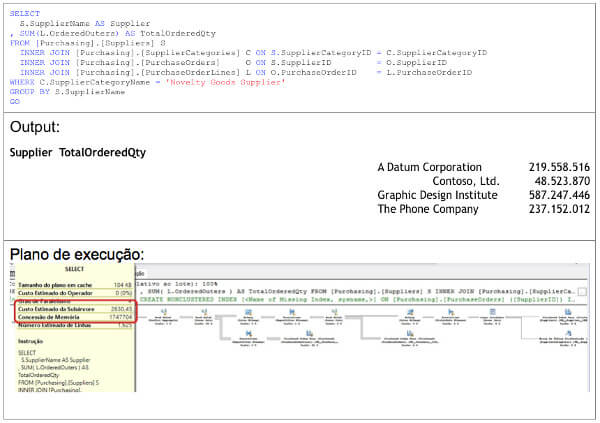
Observe que o custo de execução desta consulta é altíssimo: 2630,45. As concessões de memória chegaram a 1.747.704 processos executados.
E, no meu laptop, esta consulta rodou em 36 segundos. Agora vejamos os resultados da mesma consulta usando a visão indexada:

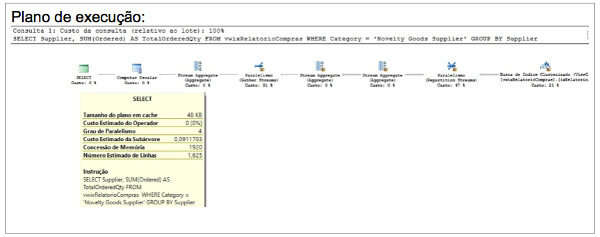
Veja que as operações neste plano de execução começam com uma operação INDEX SEEK no índice clusterizado da visão vwixRelatorioCompras.
O custo total da consulta foi de cerca de 0,09 contra 2630,45 na consulta anterior, ou seja, quase 30 mil vezes menor!
Os processos executados em memória não chegaram a 2000 (contra mais 1,7 milhão). E o tempo de execução foi menor que 1 segundo contra 36 na consulta anterior.
Os resultados são contundentes. As visões indexadas são altamente eficientes quando a consulta envolve tabelas gigantes, como neste exemplo em que usamos duas tabelas com dezenas de milhões de registros.
Mas é preciso cuidado. Em casos em que se lida com tabelas menores, com até alguns milhões de registros, é comum que o otimizador de consultas simplesmente despreze o índice criado na visão indexada e use as tabelas base para geração dos dados.
Portanto, em caso de dúvida, vale a pena testar a eficiência da visão indexada antes de movê-la para ambiente de produção.
No próximo artigo desta sequência, vou falar de índices columnstore.
Até lá!
Leituras Sugeridas
- Designing Indexed Views por MICROSOFT.
- What You Can (and Can’t) Do With Indexed Views por Jes Schultz Borland.
- SQL SERVER – Indexed View always Use Index on Table por Pival Dave.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?