

No início de 2015, a Uber Engineering migrou suas entidades empresariais de identificadores inteiros para identificadores UUID como parte de uma iniciativa para o uso de múltiplos centros de dados ativos. Para conseguir isso, nossa equipe de data warehouse foi encarregada de identificar cada relação de chave estrangeira entre cada tabela no data warehouse para preencher todas as colunas de ID com os UUIDs correspondentes¹.
Dada a propriedade descentralizada de nossas tabelas, esse não era um esforço simples. A solução mais promissora foi reunir a informação raspando todas as consultas SQL submetidas ao warehouse e observando quais colunas foram unidas. Para atender a essa necessidade, construímos e abrimos o código do Queryparser, nossa ferramenta para parsear e analisar consultas SQL.
Neste artigo, discutimos a implementação do Queryparser, a variedade de aplicativos que ele desbloqueou e alguns problemas e limitações encontrados ao longo do caminho.
Implementação
Internamente, o Queryparser é implementado em uma arquitetura de streaming, conforme mostrado na Figura 1 abaixo:
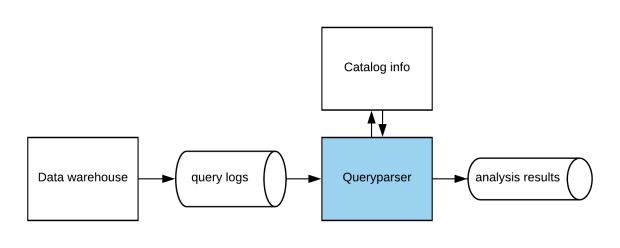
O Queryparser consome o fluxo de consultas em tempo real enviado ao data warehouse, analisa todos e emite os resultados da análise para um fluxo separado. As consultas individuais são processadas em três etapas, explicadas abaixo e ilustradas na Figura 2.
- Fase 1: Parsear. Transforma a consulta de uma string de caracteres brutos em uma representação da árvore de sintaxe abstrata (AST).
- Fase 2: Resolver. Analisa o AST bruto e aplica regras de escopo. Transforma nomes de colunas simples adicionando o nome da tabela e transforma nomes de tabela simples, adicionando o nome do esquema. Requer como entrada a lista completa de colunas em cada tabela e a lista completa de tabelas em cada esquema, também conhecido como “informações do catálogo”.
- Fase 3: Analisar. Examina o AST resolvido, procurando colunas que são comparadas para igualdade.
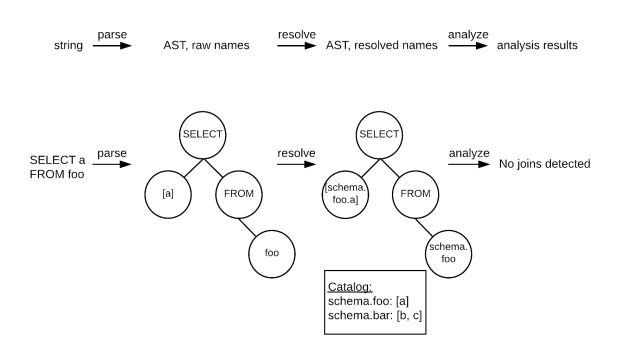
A implementação e a arquitetura identificaram com sucesso os relacionamentos de chave estrangeira – um ótimo resultado, dado que o protótipo tinha apenas uma cobertura parcial da gramática do SQL. A informação do catálogo era completamente codificada, e nossa compreensão do que contava como uma relação de chave estrangeira era evoluir continuamente.²
A escolha por Haskell
Uma das primeiras coisas que você pode ter notado no repositório open source Queryparser é que ele está escrito em Haskell. O Queryparser foi originalmente concebido por um engenheiro da Uber que era um entusiasta do Haskell, e isso rapidamente ganhou força com vários outros engenheiros. Na verdade, muitos de nós aprendemos a desenvolver Haskell especificamente nele.
O Haskell acabou sendo uma boa escolha para prototipagem do Queryparser por uma variedade de razões. Para começar, o Haskell possui um suporte de biblioteca muito maduro para analisadores de linguagem. Seu sistema de tipo expressivo também foi extremamente útil para os refatoradores frequentes e extensivos do nosso modelo interno de uma consulta SQL.
Além disso, nos apoiamos fortemente no compilador para nos guiar através desses refatoradores grandes e assustadores. Se tentássemos o mesmo usando uma linguagem dinamicamente tipada, teríamos perdido semanas perseguindo erros de tempo de execução que o compilador do Haskell pode marcar rapidamente para nós.
A principal desvantagem da escrita do Queryparser em Haskell foi que não havia desenvolvedores suficientes que soubessem a linguagem. Para introduzir mais de nossos engenheiros no Haskell, começamos um grupo de leitura semanal, que se reuniu durante o almoço para discutir livros e documentação do Haskell.
Note que, para a interoperabilidade com o restante da infraestrutura não-Haskell da Uber, o Queryparser foi (e é) implementado atrás de um servidor proxy Python.
Diversidade de soluções
Após o sucesso inicial do Queryparser, consideramos outras formas pelas quais a ferramenta poderia melhorar nossas operações de data warehouse. Além de implementar a detecção de join, decidimos implementar várias outras funções de análise:
- Acesso à tabela: quais tabelas foram acessadas na consulta
- Acesso à coluna: quais colunas foram acessadas em cada cláusula da consulta
- Linhagem de tabela: quais tabelas foram modificadas pela consulta e quais foram as entradas que determinaram seu estado final
Juntas, as novas análises dão uma compreensão cheia de nuances dos padrões de acesso em nosso data warehouse, permitindo avanços nas seguintes áreas: administração de tabelas, comunicação direcionada, compreensão do fluxo de dados, resposta a incidentes e operações defensivas, descritas abaixo:
Administração de tabelas
No que diz respeito à administração de tabelas, os benefícios foram triplos. Em primeiro lugar, as estatísticas de acesso à tabela nos permitiram liberar armazenamento e calcular recursos, encontrando tabelas que foram acessadas com pouca frequência e depois removê-las.
Em segundo lugar, as estatísticas de acesso à coluna nos permitem melhorar o desempenho do banco de dados otimizando layouts de tabelas no disco, particularmente com as projeções Vertica. O truque foi definir as colunas GROUP BY maiores como as chaves de corte e as colunas ORDER BY superiores como as chaves da ordem.
Finalmente, as estatísticas de join da coluna nos permitem melhorar a usabilidade dos dados e reduzir a carga do banco de dados, identificando clusters de tabelas que foram frequentemente unidos e substituindo-os por uma única tabela dimensionalmente modelada.
Comunicação direcionada
As estatísticas de acesso à tabela nos permitem enviar comunicações direcionadas aos consumidores de dados. Em vez de explodir toda a lista de discussão de Engenharia de Dados com atualizações sobre esquemas de tabela ou problemas de qualidade de dados, poderíamos notificar apenas os consumidores de dados que acessaram recentemente a tabela.
Compreensão do fluxo de dados
Os dados da linhagem da tabela desbloquearam um caso de uso especial: se uma sequência de consultas fosse analisada em conjunto, os dados da linhagem da tabela poderiam ser agregados para produzir um gráfico do fluxo de dados na sequência.
Por exemplo, considere o SQL hipotético na Figura 3, abaixo, que produz uma nova versão da tabela modelada A a partir das tabelas dependentes B e C:
| Query |
| drop A_new if exists |
| create A_new as select … from B |
| insert into A_new select … from C |
| drop A_old if exists |
| rename A to A_old |
| rename A_new to A |
Sequência de consultas SQL para computação da tabela modelada A a partir das tabelas dependentes B e C.
Na Figura 4, abaixo, descrevemos a linhagem da tabela que o Queryparser produziria para cada consulta na sequência. Além disso, descrevemos e explicamos o fluxo de dados cumulativo observado para cada consulta na sequência. No final, o fluxo de dados cumulativo (corretamente!) registra que a tabela A possui dependências nas tabelas B e C:
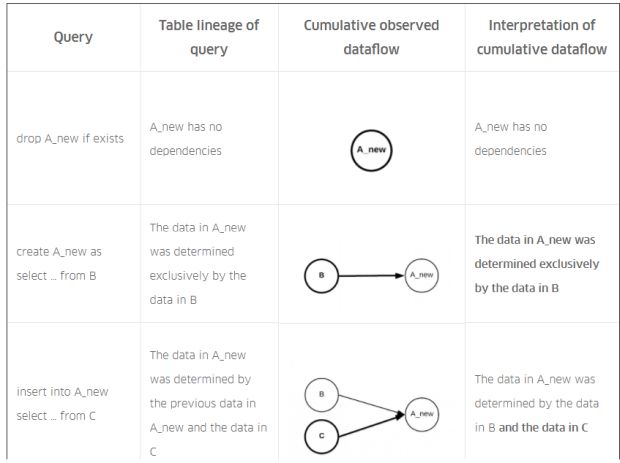
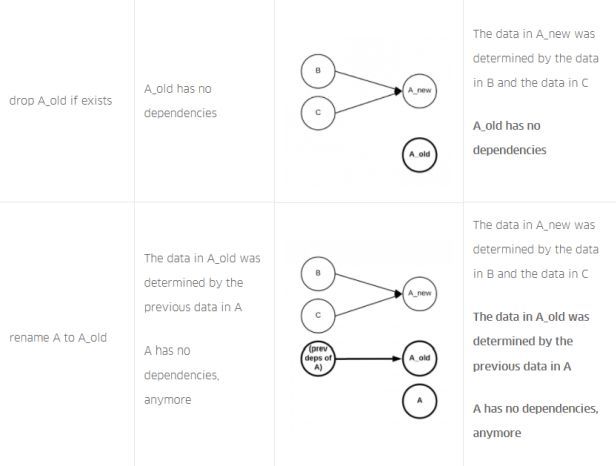
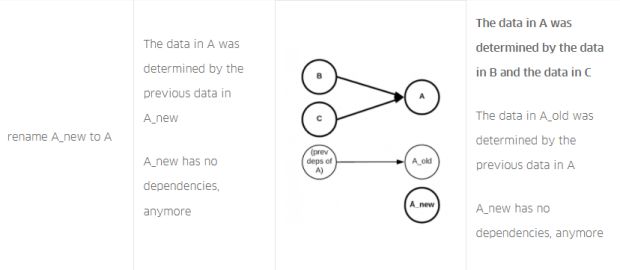
SQL da Figura 3, com linhagem de tabela para cada consulta na sequência e linhagem de tabela cumulativa para toda a sequência.
Nós modificamos nosso framework ETL para registrar a sequência de consultas SQL em cada ETL e enviá-las para o Queryparser, no ponto em que o Queryparser gerou programaticamente gráficos de fluxo de dados para todas as tabelas modeladas em nosso warehouse. Veja a Figura 5 abaixo para um exemplo:
Resposta a incidentes
Os dados da linhagem de tabela têm sido úteis para responder a incidentes de qualidade de dados, diminuindo o tempo de mitigação, oferecendo visibilidade tática no impacto do incidente. Por exemplo, dadas as dependências da tabela na Figura 5, se houvesse um problema na tabela A, saberíamos que o alcance do impacto incluía as tabelas modeladas E e G.
Também saberíamos que, uma vez que o problema tivesse sido resolvido, E e G precisariam ser preenchidas novamente. Para resolver isso, poderíamos combinar os dados de linhagem com os dados de acesso à tabela para enviar comunicações direcionadas a todos os usuários de E e G.
Os dados da linhagem da tabela também são úteis para identificar a causa raiz de um incidente. Por exemplo, se houvesse um problema com a tabela modelada E na Figura 5, isso só poderia ser devido às tabelas brutas A ou B. Se houvesse um problema com a tabela modelada G, poderia ser devido às tabelas brutas A, B, C ou D.
Operações defensivas
Finalmente, a capacidade de analisar consultas em tempo de execução desbloqueou táticas de operações defensivas que permitiram que nosso data warehouse funcionasse com mais facilidade. Com o Queryparser, as consultas podem ser interceptadas no caminho para o data warehouse e submetidas para análise. Se o Queryparser detectar erros de análise ou determinados antipadrões de consulta, a consulta pode ser rejeitada, reduzindo a carga total no data warehouse.
Problemas e limitações
Fred Brooks argumentou que não existe uma bala de prata na engenharia de software. Embora seja benéfico para nossas necessidades de armazenamento, o Queryparser não foi uma exceção. À medida que o projeto se desenrolava, revelava algumas complexidades essenciais interessantes.
Cauda longa de recursos de linguagem
Primeiro, e menos surpreendente: ao adicionar suporte para um novo dialeto SQL, há uma cauda longa de recursos de linguagem raramente usados para implementar, o que pode exigir mudanças significativas na representação interna do Queryparser de uma consulta. Isso foi imediatamente aparente durante a fase do protótipo, quando o Queryparser lidou exclusivamente com a Vertica, e foi confirmado quando o suporte para o Hive e para o Presto foi adicionado.
Por exemplo, analisar TIMESERIES e OFFSET na Vertica exigiu a adição de novas cláusulas às instruções SELECT. Além disso, analisar LEFT SEMI JOINs no Hive exigiu um novo tipo de join com regras de escopo especiais, e analisar o namespace de nível superior de bônus de “bancos de dados” no Presto (onde as tabelas pertencem a esquemas que pertencem a bancos de dados) exigiu uma reestruturação extensa de análise de struct-parsing.
Rastreando o estado do catálogo
Em segundo lugar, rastrear o estado do catálogo foi difícil. Lembre-se de que as informações do catálogo são necessárias para resolver nomes de colunas e nomes de tabelas. O data warehouse da Uber suporta cargas de trabalho altamente concorrentes, incluindo mudanças de esquema simultâneas, tipicamente criando, abandonando e renomeando tabelas, adicionando ou descartando colunas de uma tabela existente.
Experimentamos brevemente o uso do Queryparser para rastrear o estado do catálogo; se o Queryparser já estivesse analisando todas as consultas, nos perguntamos se poderíamos simplesmente adicionar uma análise que informou as mudanças de esquema e produziu o novo estado do catálogo aplicando-as ao estado do catálogo anterior.
Em última análise, essa abordagem não teve êxito devido à dificuldade de solicitar todo o fluxo de consultas. Em vez disso, nossa abordagem alternativa (e mais efetiva) foi tratar o estado do catálogo como mais ou menos estático, rastreando a associação de esquemas e listas de colunas de tabelas através de arquivos de configuração.
Consultas de sessão
Em terceiro lugar, as consultas de sessão com o Queryparser foram difíceis. Em um mundo perfeito, o Queryparser poderia rastrear a linhagem da tabela em toda uma sessão de banco de dados, contabilizando transações e reversões e vários níveis de isolamento de transações.
Na prática, no entanto, a reconstrução de sessões de banco de dados a partir dos registros de consulta foi difícil, então decidimos não adicionar suporte de linhagem de tabela para esses recursos. Em vez disso, o Queryparser depende do framework ETL da Uber para sessionizar as consultas ETL em seu nome.
Abstração furada
Finalmente, Hive é uma abstração furada sobre o sistema de arquivos subjacente. Por exemplo, INSERTs podem ser realizados por vários meios:
INSERT INTO foo SELECT … FROM bar
ALTER TABLE foo ADD PARTITION … LOCATION ‘/hdfs/path/to/partition/in/bar’
O framework ETL da Uber usou inicialmente o primeiro método, mas ele foi migrado para o segundo, pois apresentou melhorias dramáticas no desempenho. Isso causou problemas com os dados da linhagem da tabela, pois ‘/hdfs/path/to/partition/in/bar’ não foi interpretado pelo Queryparser como correspondente à barra de tabela.
Esse problema específico foi temporariamente atenuado com uma expressão regular para inferir o nome da tabela do caminho HDFS. No entanto, em geral, se você optar por ignorar as abstrações SQL do Hive em favor das operações da camada do sistema de arquivos, você exclui a análise do Queryparser.
Implementando o Queryparser
A implementação de um serviço Haskell na infraestrutura não-Haskell da Uber exigiu pouca criatividade, mas nunca constituiu um problema substancial.
Instalar o próprio Haskell foi direto. O padrão de infraestrutura Uber é executar todos os serviços em um container do Docker. As dependências de nível de container são gerenciadas por meio de arquivos de configuração, de modo que adicionar o suporte para Haskell foi tão simples como adicionar Stack à lista de pacotes necessários.
O Queryparser é implementado internamente como um artefato Haskell, executado por trás de um wrapper de serviço Python para interoperabilidade com o restante da infraestrutura da Uber. O wrapper do Python atua como um servidor proxy e simplesmente encaminha pedidos para o servidor do backend Haskell no mesmo container do Docker. O servidor Haskell consiste em uma thread principal que escuta solicitações em um soquete de domínio UNIX; quando uma nova solicitação chega, a thread principal engloba uma thread de trabalho para lidar com o pedido.
O wrapper Python também lida com a emissão métrica em nome do backend do Haskell. Os dados métricos são passados através de um segundo soquete de domínio UNIX, com os dados que fluem na direção inversa: uma daemon-thread na camada Python escuta as métricas da camada Haskell.
Para compartilhar a configuração entre as camadas Python e Haskell, implementamos um pequeno analizador de configuração em Haskell, que compreendeu o padrão Python da Uber de arquivos de configuração em camadas.
Finalmente, para definir a interface de serviço, utilizamos Thrift. Essa é a escolha padrão da Uber, e como Thrift tem suporte para Haskell, o servidor Haskell funcionou fora da caixa. Escrever o código Python para encaminhar de forma transparente os pedidos necessários para mergulhar no protocolo binário foi o passo de operações mais difícil.
Resumo
O Queryparser desbloqueou uma diversidade de soluções e teve algumas limitações interessantes. A partir de suas origens humildes como ferramenta de migração. Tornou-se um veículo para uma visão de padrões de acesso a dados em larga escala.
Se você estiver interessado em trabalhar em projetos similares, fique atento a za@uber.com e/ou inscreva-se para um cargo conosco na página Uber Careers e informe ao seu recrutador da Uber que gostaria de trabalhar na equipe Data Knowledge Platform.
Notas finais
- ¹Alerta de Spoiler: acabaram sendo dezenas de chaves primárias para migrar. Cada chave primária poderia ter muitas chaves estrangeiras sob aliases diferentes. O pior infrator tinha mais de 50 aliases diferentes.
- ²Os relacionamentos de chave estrangeira variaram do óbvio como “SELECT * FROM foo JOIN bar ON foo.a = bar.b” para o menos óbvio como “SELECT * FROM foo.a IN (SELECT b from bar)” para o discutível como “SELECT a FROM foo UNION SELECT b FROM bar”. Nós erramos ao sermos liberais sobre o que contamos como um relacionamento, já que a saída seria inspecionada manualmente de qualquer maneira.
- ³Dado o SQL “w.x.y.z”, qual identificador é o nome da coluna? Dependendo do estado do catálogo e do alcance, pode ser “w” com “x.y.z” referindo-se a campos de estrutura aninhados, ou pode ser “z” com “w.x.y” referente a “database.schema.table”, ou qualquer coisa no meio disso.
***
Este artigo é do Uber Engineering. Ele foi escrito por Matt Halverson. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/queryparser/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?