

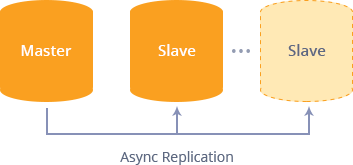
A replicação permite que você mantenha facilmente várias cópias dos dados do MySQL. Ele é obtido através dos dados do contêiner mestre sendo copiados automaticamente para um ou mais bancos de dados escravos.
Ter seus dados armazenados em vários contêineres de banco de dados pode ser muito útil para melhorar o desempenho, executar serviços de backup, analisar informações e aliviar falhas do sistema.
Podem ser destacados os seguintes casos de uso para implementação de replicação MySQL:
- Soluções de escalabilidade – melhorando o desempenho espalhando a carga entre vários escravos onde todas as leituras ocorrem, enquanto todas as escritas e atualizações ocorrem no banco de dados mestre
- Backups – executando backups no escravo sem afetar os dados mestres
- Análises – criando dados ao vivo no mestre e analisando-os no escravo sem afetar o desempenho mestre
- Distribuição de dados de longa distância – fazendo uma cópia local de dados que serão usados por um site remoto sem acesso direto ao mestre
Geralmente, o procedimento complexo de configurar a replicação mestre-escravo do MySQL é um processo completamente automatizado com o Jelastic. Para economizar tempo e esforço, desenvolvemos um pacote pronto para uso com a replicação já configurada.
Agora vamos dar uma olhada na estrutura do pacote e no guia passo a passo para uma implantação fácil na Nuvem.
Cluster MySQL de um clique para implantar instantaneamente
O pacote de instalação de um clique é construído usando a imagem Docker devbeta/mysql57:5.7.14-latest. Por padrão, você obtém dois contêineres de banco de dados MySQL 5.7 – o mestre e o escravo. Você pode ajustar o número exato de contêineres escravos durante o estágio de instalação do pacote ou, posteriormente, dentro do assistente de topologia – esses procedimentos estão descritos posteriormente no artigo.
Dentro do pacote, cada contêiner de banco de dados recebe o limite de escalonamento vertical padrão – de 1 cloudlet reservado para 8 cloudlets dinâmicos (até 1 GiB de RAM e 3,2 GHz de CPU). Posteriormente, você pode reajustar o limite de alocação de recursos padrão no assistente de topologia no dashboard.
Agora, vamos prosseguir para obter o pacote do MySQL Cluster instalado na Nuvem.
Instalação de Bancos de Dados MySQL Replicados
A implantação de pacotes JPS é um processo completamente automatizado que pode ser realizado em apenas alguns cliques.
1. Efetue login na Plataforma Jelastic com suas credenciais e clique em Importar no painel superior.
![]()
2. Mude para a guia URL e insira o link abaixo para buscar o arquivo jps desejado:
https://github.com/jelastic-jps/mysql-cluster/raw/master/manifest.jps
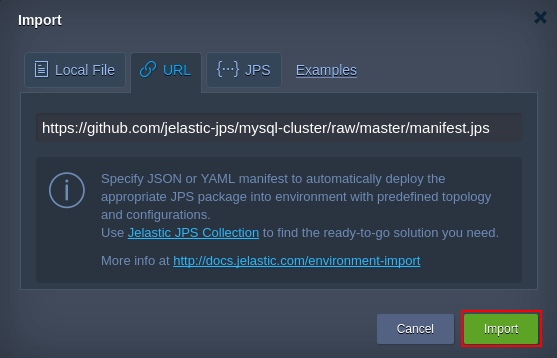
Clique em Importar para continuar.
3. Na janela de confirmação aberta, introduza o número total de contêineres onde um contêiner é o mestre e o restante dos contêineres são os escravos.
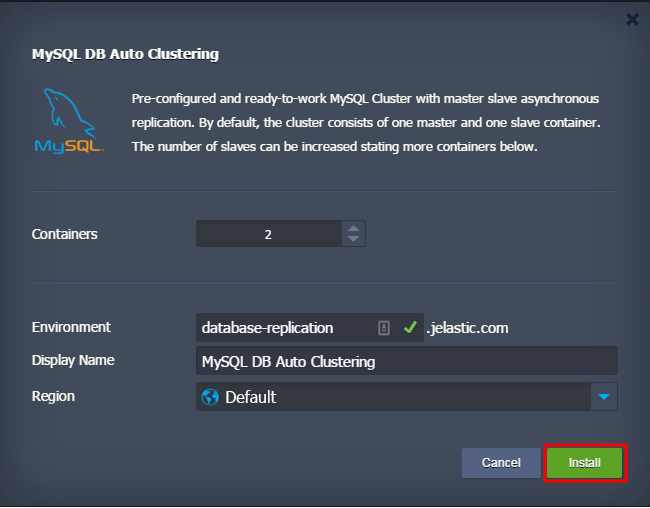
Digite o nome do ambiente e, opcionalmente, o Nome para exibição (alias). Além disso, selecione a região preferível (se houver vários disponíveis) e clique em Instalar.
A instalação e configuração do ambiente demorarão alguns minutos e, em seguida, você verá um quadro exibindo os dados de administração do node mestre.
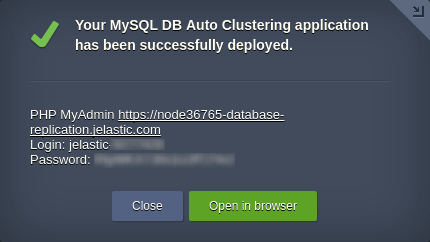
Agora, vamos colocar o banco de dados mestre em ação para verificar se a replicação funciona corretamente.
Testando a replicação de bancos de dados MySQL instalada
Para garantir que os dados sejam replicados para os bancos de dados escravos mesmo após o escalonamento horizontal, criaremos um novo banco de dados no contêiner mestre, adicionaremos mais um node escravo do MySQL ao cluster e verificaremos os dados no interior.
Criando um novo banco de dados
1. Clique no botão Abrir no navegador próximo do node mestre do MySQL para iniciar a interface web do phpMyAdmin.

2. Faça o login com as credenciais que você recebeu por e-mail após a instalação do pacote.
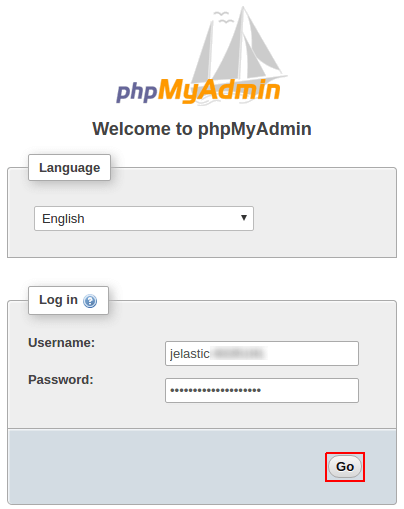
Clique em Ir para acessar a página.
3. Mude para a guia Bancos de dados, digite um nome para um novo banco de dados (por exemplo, Jelastic) e clique em Criar.
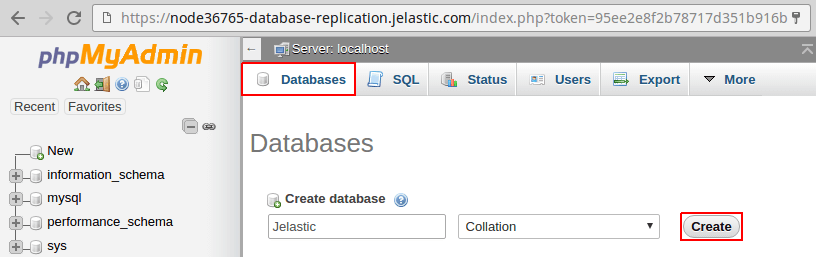
Agora, quando o banco de dados é criado no node mestre, vamos escalonar o ambiente e, em seguida, verificar os dados replicados dentro dos escravos adicionados.
Adicionando um escravo
Todos os contêineres adicionados após a instalação do cluster atuam como escravos com a replicação de dados mestre correspondente ativada automaticamente. Para ajustar o número de contêineres escravos, execute as seguintes etapas.
1. Clique no botão Alterar topologia do ambiente próximo do ambiente alvo.

2. Escale os contêineres por meio dos botões +/- na parte central do assistente.
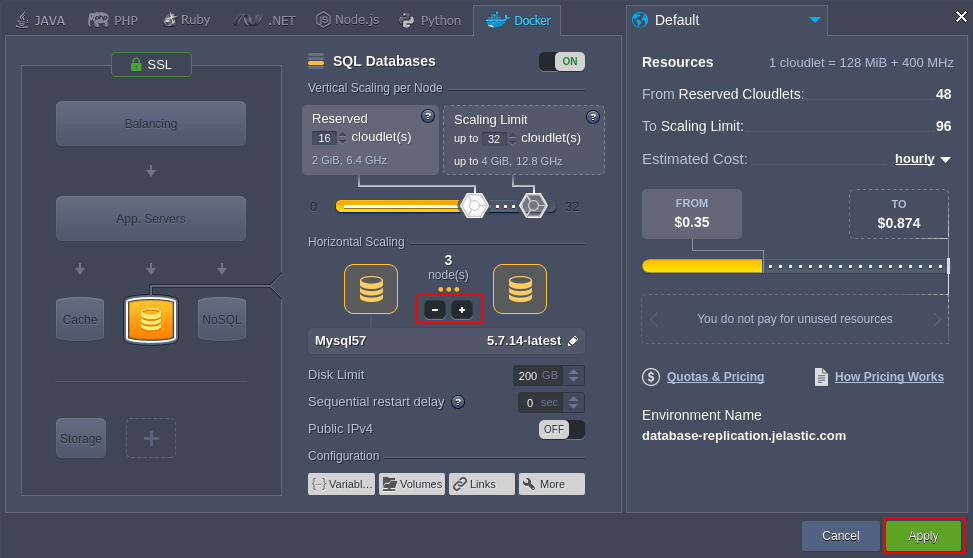
Clique em Aplicar para salvar as configurações.
Agora que você ajustou o número exato de contêineres escravos necessários, vamos lançar a interface de administração escrava para verificar os resultados da replicação.
Verificando a Replicação
Para certificar-se de que a replicação de dados do mestre para os contêineres escravos funciona como pretendida, execute as seguintes etapas.
1. Clique no botão Abrir no navegador próximo do node escravo MySQL alvo para iniciar a interface web phpMyAdmin.

2. Efetue login na interface de administração (use o mesmo login e senha que você recebeu por e-mail após a instalação do pacote).
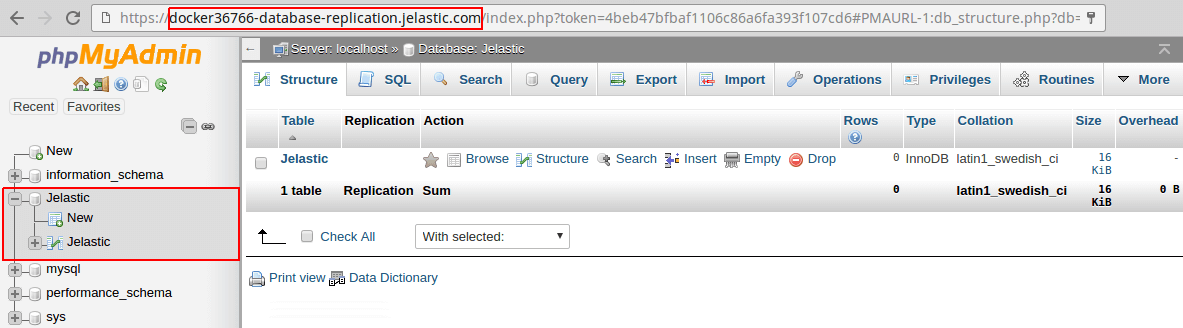
Da mesma forma, você pode acessar a interface de administração do escravo recém adicionado para verificar a disponibilidade de dados replicados.
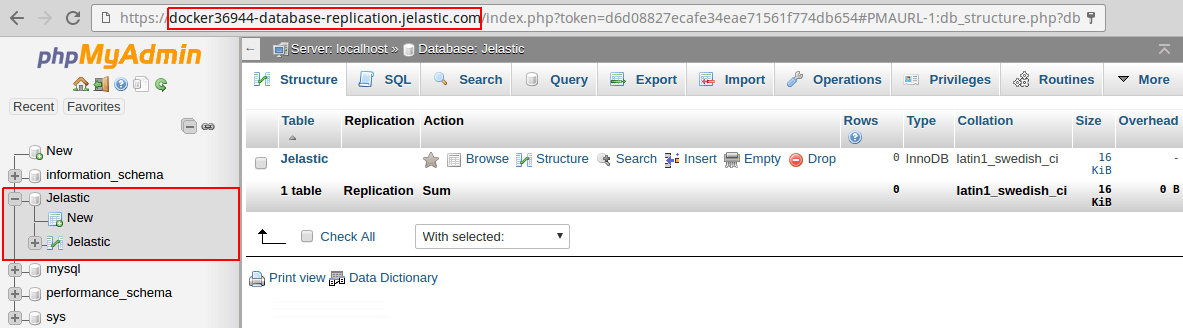
Uma vez conectado, você pode acessar e gerenciar o banco de dados (Jelastic, no nosso exemplo) que foi criado anteriormente no contêiner mestre.
É isso aí! A replicação mestre-escravo do MySQL está pronta e em execução e o cluster está pronto para processamento de dados. Integrar o cluster de banco de dados ao seu projeto geralmente depende de especificações de aplicativo, você pode encontrar vários drivers e bibliotecas na página oficial de conectores.
***
Tetiana Fydorenchyk faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela Redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://blog.jelastic.com/2017/03/14/scalable-mysql-master-slave-replication/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?