

No artigo anterior (link) falei sobre a leitura de listas de valores em arquivos JSON usando recursos do Azure SQL DB. Agora é a vez de tratar de listas de valores em arquivos texto (TXT, CSV etc.).
Arquivos Texto e Listas
Nos exemplos que apresentarei a seguir, eu uso um arquivo CSV com o mesmo esquema do arquivo JSON já apresentado, como se vê a seguir:
| OrderNumber | Customer | Address | ProductID |
| 574895677 | John Doe | {‘Name’: ‘Casa’, ‘Street’: ‘Rua 5, no 42’,… | ‘AAF’,’AAR’,’AAS’,’AAT’…. |
Requisitos
Assim como ocorre com a leitura de arquivos JSON em uma conta de armazenamento da nuvem, para lidar com arquivos textos também serão necessárias:
- uma chave mestra
- uma credencial de escopo
- uma fonte de dados externa
A criação destes objetos foi tratada na primeira parte dessa série. Aqui apresento como verificar se/quais deles já existem no seu banco de dados:
| 01
02 03 04 05 06 |
–verificando existência de chave mestra
select * from sys.symmetric_keys –verificando existência de uma credencial de escopo select * from sys.database_scoped_credentials –verificando existência de uma fonte de dados externa select * from sys.external_data_sources |
Lendo Dados do CSV
A coisa fica um tanto confusa quando se trata de leitura de arquivos texto armazenados em contas de blobs através dos serviços de dados do AZURE. Isso ocorre por duas razões principais:
- Existem várias alternativas de acesso a este tipo de arquivo
- Existem diferenças fundamentais entre o modo como usá-las dependendo se usamos SQL Server, AZURE SQL (várias opções) e AZURE SYNAPSE SQL POOL.
Em resumo, um script pode rodar com sucesso ou não dependendo da combinação de alternativas que você escolhe. E esse número de combinações é respeitável.
Não bastasse isso, quem trabalha com SQL normalmente está acostumado com ambiente WINDOWS. No entanto, se seus dados estão numa conta de armazenamento, é preciso levar em conta algumas peculiaridades do ambiente LINUX.
Por exemplo, ao apontar para um determinado arquivo, os nomes da conta de armazenamento, container, caminho e arquivo são todos sensíveis a maiúsculas. Você era uma letra e vai receber uma mensagem como esta:
| Msg 4861, Level 16, State 1, Line 9
Cannot bulk load because the file “<CaminhoArquivo>” could not be opened. Operating system error code 5(Access is denied.). |
Em segundo lugar, é preciso tomar cuidado com separadores de campos e de linhas. No WINDOWS, costuma-se usar “\r\n” para identificar novas linhas. Mas a conta de armazenamento usa o padrão LINUX “0x0a”.
Tendo isso em mente, vamos a alguns exemplos de leitura.
Lendo Dados como SINGLE_CLOB
A primeira e mais simples maneira de ler arquivos CSV é usando OPENROWSET com a opção SINGLE_CLOB, conforme já apresentei no tratamento dos arquivos JSON.
A característica do SINGLE_CLOB é retornar um arquivo inteiro como um único campo no formato VARCHAR(MAX). A sintaxe é bem simples e a performance é bastante boa, mas o resultado é praticamente ilegível. Veja o quadro a seguir:
| 01
02 03 04 05 06 |
SELECT *
FROM OPENROWSET ( BULK ‘data/LargeArray/myFile.csv’, DATA_SOURCE = ‘myStuff’, SINGLE_CLOB ) as T |
||
|
No caso dos JSON, o operador OPENROWSET com opção SINGLE_CLOB era usado em associação com o OPENJSON, retornando um resultado tabulado. Mas não existe nada parecido quando se trata de arquivos texto.
Então é preciso mudar a forma como se usa o OPENROWSET.
Lendo Dados com a Opção FORMATFILE
O problema é solucionado usando uma sintaxe diferente do OPENROWSET: com a opção FORMATFILE. Isto permite usar um arquivo externo que especifica o esquema usado no arquivo CSV, de maneira idêntica ao que se usa com o utilitário BCP.
Lamentavelmente, as sintaxes do OPENROWSET disponíveis no AZURE SQL DB são limitadas. Todas as especificações de formato precisam ser informadas através do arquivo de formatação especificado na opção FORMATFILE. Para simplificar o exemplo a seguir, alterei o arquivo original de modo que:
- Não se usasse aspas (“”) para caracterizar colunas de texto
- Não houvesse uma linha de cabeçalho. (Nomes das colunas, bem como outros detalhes relativos ao esquema do arquivo, são especificados no arquivo de formatação).
- Usasse um separador de colunas especial (por exemplo, “|”), de modo a poder usar as vírgulas dentro dessas duas colunas de texto que já utilizam este caractere.
Outro detalhe importante é que o arquivo de formatação parece ser muito simples, mas depurá-lo em caso de erro é um caos. Para evitar essa dor de cabeça, eu executei o BCP localmente para que ele próprio lesse o arquivo de dados e gerasse o arquivo de formatação correspondente. Você pode encontrar exemplos deste procedimento neste estudo de caso ou diretamente na documentação do BCP.
Desse modo, cheguei nos arquivos exemploCSV.csv e CSVfile.fmt e os carreguei para a conta de armazenamento. Para organizar os arquivos em grupos apropriados, criei dentro do container os diretórios CSV e FMT (atenção para as letras maiúsculas). O conteúdo destes arquivos é apresentado na tabela a seguir.
| Arquivo CSV |
| 574895677|John Doe|{‘Name’: ‘Casa’, ‘Street’: ‘Rua 5, no 42’, ‘City’: ‘São Paulo’, ‘State’: ‘SP’ },……. |
| Arquivo de formatação |
| 14.0
4 1 SQLCHAR 0 50 “|” 1 OrderNumber SQL_Latin1_General_CP1_CI_AS 2 SQLCHAR 0 200 “|” 2 Customer SQL_Latin1_General_CP1_CI_AS 3 SQLCHAR 0 8000 “|” 3 Address SQL_Latin1_General_CP1_CI_AS 4 SQLCHAR 0 8000 “0x0a” 4 ProductID SQL_Latin1_General_CP1_CI_AS |
Finalmente podemos ler o arquivo usando a declaração abaixo. Seu resultado é apresentado na sequência.
| 01
02 03 04 05 06 07 08 |
SELECT *
FROM OPENROWSET ( BULK ‘data/LargeArray/CSV/exemploCSV.csv’, DATA_SOURCE = ‘myStuff’, FORMAT=‘CSV’, FORMATFILE=‘data/LargeArray/FMT/CSVfile.fmt’, FORMATFILE_DATA_SOURCE = ‘myStuff’ ) as CSV |
||||||||
|
Trabalhando com Listas
Agora podemos começar a tratar da lista existente na coluna ProductID. A ideia é que o output mostre um registro para cada item apresentado nesta lista.
No entanto, para o TSQL, esta é simplesmente uma coluna de cadeia de caracteres como outra qualquer.
Felizmente, a partir do SQL Server 2016, temos a função STRING_SPLIT para lidar com esta situação. Sua sintaxe é bastante simples: basta apontar para a cadeia de caracteres e informar qual o separador usado. Mas atenção: esta é uma função tabular, o que muda muito na sintaxe da declaração.
Desse modo, nossa declaração passa a ser assim:
| 01
02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 |
— tratamento da lista
WITH cteSplit AS ( SELECT * FROM OPENROWSET ( BULK ‘data/LargeArray/CSV/exemploCSV6.csv’, DATA_SOURCE = ‘myStuff’, FORMAT=‘CSV’, FORMATFILE=‘data/LargeArray/FMT/CSVfile.fmt’, FORMATFILE_DATA_SOURCE = ‘myStuff’ ) as CSV ) SELECT S.OrderNumber , S.Customer , S.Address , X.Value AS ProductID –> resultado desejado FROM cteSplit S CROSS APPLY STRING_SPLIT(S.ProductID, ‘,’) X |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Note que a função STRING_SPLIT converteu a lista da coluna ProductID em uma “tabela”. E o operador CROSS APLLY combina os dois conjuntos.
Observação: não existe atualmente um tipo de dados JSON no TSQL. Sendo assim, a manipulação dessa coluna precisa ser feita usando outras técnicas. Para uma introdução ao assunto, sugiro verificar a função JSON_VALUE.
Dica Sobre a Função STRING_SPLIT
Dependendo das características do seu ambiente, pode ocorrer de aparecer uma mensagem de erro informando que a operação com esta função excede o limite de iterações. Em outras palavras, a cadeia de caracteres tratada pelo STRING_SPLIT é grande demais.
Nunca tive este problema usando o AZURE SQL DB, mas já me ocorreu com o SQL Server, mesmo em VMs.
Como esta função trabalha de forma recursiva, basta adicionar a seguinte dica SQL (ou “hint”, se preferir) ao final da declaração:
| [SELECT……….]
OPTION (MAXRECURSION <LimiteIterações>) |
Este limite é um número inteiro entre 0 e 32767, sendo que o zero representa sem limite algum. O valor default é 100.
Pelo que me consta, este parâmetro surgiu logo que as CTEs foram incorporadas ao TSQL. Como havia a possibilidade de se construir CTEs recursivas, um código malfeito poderia rodar indefinidamente, daí a importância de se criar um ponto de parada.
Portanto, se você estiver usando a função STRING_SPLIT e receber a mensagem de erro mencionada acima, basta definir um valor adequado para a quantidade de iterações. Como você deve ter notado, o uso de MAXRECURSION 0 neste contexto apresenta um risco muito baixo.
Avaliando a Performance
Hora de falar sobre a performance das declarações que usam esta técnica. Para fins comparativos, vou apresentar o plano de execução obtido em três cenários:
- arquivo original, contendo 1 registro e lista com 12 elementos
- arquivo com 1 registro e lista de 2000 elementos
- arquivo com 10k registros com listas de 2000 elementos
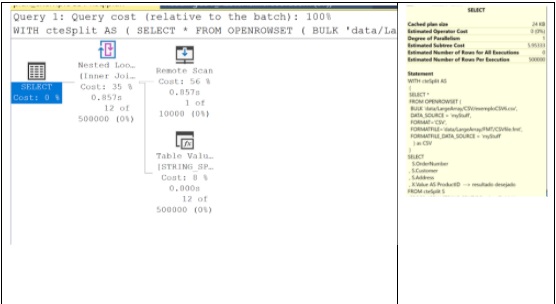
Caso 1 – arquivo original (1 registro e lista com 12 elementos)
Apesar da aparente complexidade da declaração que usa a função SPLIT_STRING, seu plano de execução é bastante simples, com apenas 04 ações.
A operação mais impactante neste teste é a leitura do arquivo texto (“REMOTE SCAN”), responsável por 56% do custo de toda operação. A operação de STRING_SPLIT representa apenas 8% e a combinação das consultas na operação de CROSS APPLY (“NESTED LOOP”) responde por mais 35%.
O que espanta é o custo total: 5,95. Este custo é altíssimo para uma consulta de um único registro (273 bytes). Isso sugere que a operação de leitura do arquivo é muito pesada (3,36), mais ainda do que o CROSS APPLY (2,09) que é uma operação famosa por ser lenta.
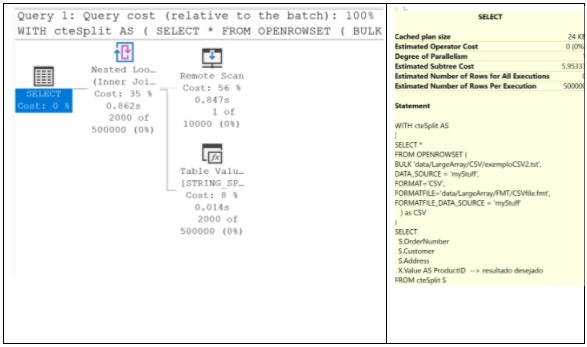
Caso 2 – arquivo com 1 registro e lista de 2000 elementos
No segundo teste, a lista estudada cresce de 12 para 2000 elementos. Lembre-se que, na definição de formato para a coluna ProductID, foi especificado que a coluna seria o tamanho de 8000 caracteres. Daí a razão de haver um limite razoavelmente baixo para o tamanho da lista.
Olhando seu plano de execução, observamos que os custos são exatamente iguais ao caso anterior, assim como os tempos de execução. Lembrando que o exemplo do Caso 1 é um arquivo de 273 bytes e agora usamos outro com 8201 bytes (isto é, 30 vezes maior).
Caso 3 – listagem de arquivo com 10k registros com listas de 2k elementos
Agora testamos a leitura com um arquivo de múltiplas linhas. O arquivo de testes reaproveita a lista com 2000 elementos criada no caso anterior, mas traz dados para 10000 ordens diferentes.
Naturalmente o tempo de execução da consulta será muito alto, visto que o SELECT exibe um total de 20 milhões de registros. Mais uma vez, o custo total exibido permanece o mesmo. Mas os tempos de processamento mudam dramaticamente.
Isso sugere que o otimizador de consultas do SQL não consegue fazer melhorias de performance neste tipo de consulta. Ainda assim, o tempo de processamento da leitura e tratamento do arquivo (2,57 seg) é bastante bom para um arquivo tão grande: 78.2 Mb.
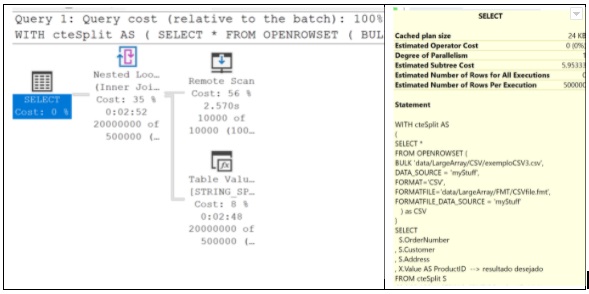
Por outro lado, as operações de STRING_SPLIT e CROSS JOIN levaram quase 170 segundos cada uma. Visto que estas duas operações em teoria ocorrem em memória, este tempo é absurdamente alto.
Comentários Finais
Apesar da aparente simplicidade, é necessário ter muita atenção para lidar com arquivos texto diretamente no AZURE SQL DB.
Porém, uma vez que tudo esteja devidamente configurado, a performance é respeitável quando se trabalha com arquivos grandes. No caso de ser necessário ler uma grande quantidade arquivos pequenos (como se tem num Data Lake, por exemplo), o AZURE SQL DB deixa de ser uma boa alternativa.
Talvez isso mude no futuro, pois outros serviços do AZURE (como o SYNAPE) oferecem uma série de funcionalidades para lidar com este cenário. Por enquanto, várias delas continuam indisponíveis no AZURE SQL DB.
Em relação à função STRING_SPLIT, a sintaxe simples ajuda bastante, mas deve-se lembrar que o processamento é pesado. De todo modo, a funcionalidade oferecida é muito útil para qualquer banco de dados que tenha que lidar com listas.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?