

Durante a última década, os modelos de deep learning provaram ser altamente eficazes em realizar uma ampla variedade de tarefas de machine learning em visão, fala e linguagem.
Na Uber, estamos usando esses modelos para uma variedade de tarefas, incluindo suporte para o cliente, detecção de objetos, aprimoramento de mapas, simplificação das comunicações em chat, previsão e prevenção de fraudes.
Muitas bibliotecas open source, incluindo TensorFlow, PyTorch, CNTK, MXNET e Chainer, entre outras, implementaram os blocos de building necessários para construir esses modelos, permitindo um desenvolvimento mais rápido e menos propenso a erros.
Isso, por sua vez, impulsionou a adoção de tais modelos tanto pela comunidade de pesquisa em machine learning quanto pelos profissionais do setor, resultando em um rápido progresso tanto no projeto de arquitetura quanto nas soluções industriais.
Na Uber AI, decidimos evitar reinventar a roda e desenvolver pacotes construídos com base nas fortes bases que as bibliotecas open source fornecem.
Para esse fim, em 2017 nós lançamos o Pyro, uma linguagem de programação profunda e probabilística construída em PyTorch, e continuamos a aprimorá-lo com a ajuda da comunidade open source.
Outra grande ferramenta open source de IA criada pela Uber é o Horovod, um framework hospedado pela LF Deep Learning Foundation que permite o treinamento distribuído de modelos de deep learning em várias GPUs e várias máquinas.
Estendendo nosso compromisso de tornar o aprendizado profundo mais acessível, lançamos o Ludwig, uma toolbox open source de deep learning construída sobre o TensorFlow que permite aos usuários treinarem e testarem modelos de deep learning sem escrever código.
O Ludwig é único em sua capacidade de ajudar a tornar o deep learning mais fácil de entender para não especialistas e possibilitar ciclos de iteração de melhoria de modelo mais rápidos para desenvolvedores e pesquisadores experientes em machine learning.
Usando o Ludwig, especialistas e pesquisadores podem simplificar o processo de prototipagem e agilizar o processamento de dados, de modo que possam se concentrar no desenvolvimento de arquiteturas de deep learning em vez de disputas de dados.
Ludwig
Temos desenvolvido o Ludwig internamente na Uber nos últimos dois anos para simplificar o uso de modelos de deep learning em projetos aplicados, pois eles geralmente exigem comparações entre diferentes arquiteturas e iteração rápida.
Temos testemunhado seu valor em vários projetos da Uber, incluindo nosso Customer Obsession Ticket Assistant (COTA), extração de informações de carteiras de motorista, identificação de pontos de interesse durante conversas entre motoristas parceiros e passageiros, previsão de tempo de entrega de alimentos e muito mais.
Por esse motivo, decidimos lançá-lo como open source, pois acreditamos que não há outra solução atualmente disponível com a mesma facilidade de uso e flexibilidade.
Originalmente, projetamos o Ludwig como uma ferramenta genérica para simplificar o processo de desenvolvimento e comparação de modelos ao lidar com novos problemas de machine learning aplicados.
Para fazer isso, nos inspiramos em outros softwares de machine learning: de Weka e de MLlib, a ideia de trabalhar diretamente com dados brutos e fornecer um certo número de modelos pré-construídos; de Caffe, a natureza declarativa do arquivo de definição; e de scikit-learn, sua API programática simples.
Essa combinação de influências faz com que ele seja uma ferramenta bastante diferente das bibliotecas de deep learning usuais que fornecem primitivas de álgebra tensorial e outras utilidades para codificar modelos, enquanto ao mesmo tempo a torna mais geral que outras bibliotecas especializadas como PyText, StanfordNLP, AllenNLP e OpenCV.
O Ludwig fornece um conjunto de arquiteturas de modelo que podem ser combinadas para criar um modelo de ponta a ponta para um determinado caso de uso.
Como uma analogia, se as bibliotecas de deep learning fornecem os blocos de building para construir o seu building, o Ludwig fornece os buildings para fazer sua cidade, e você pode escolher entre os buildings disponíveis ou adicionar seu próprio building ao conjunto de buildings disponíveis.
Os principais princípios de design que criamos na toolbox são:
- Nenhuma codificação é necessária: nenhuma habilidade de codificação é necessária para treinar um modelo e usá-lo para obter previsões.
- Generalidade: uma nova abordagem baseada em tipo de dados para o design de modelo de deep learning que torna a ferramenta utilizável em diversos casos de uso.
- Flexibilidade: os usuários experientes têm amplo controle sobre a construção e o treinamento de modelos, enquanto os recém-chegados terão facilidade de uso.
- Extensibilidade: fácil de adicionar nova arquitetura de modelo e novos tipos de dados de recursos.
- Compreensibilidade: os modelos internos de deep learning são geralmente considerados caixas-pretas, mas fornecemos visualizações padrão para entender seu desempenho e comparar suas previsões.
O Ludwig permite que seus usuários treinem um modelo de deep learning fornecendo apenas um arquivo tabular (como CSV) contendo os dados e um arquivo de configuração YAML que especifica quais colunas do arquivo tabular são recursos de entrada e quais são variáveis de destino de saída.
A simplicidade do arquivo de configuração permite uma prototipagem mais rápida, reduzindo potencialmente as horas de codificação para alguns minutos.
Se mais de uma variável de destino de saída for especificada, o Ludwig executará o aprendizado multitarefa, aprendendo a prever todas as saídas simultaneamente, uma tarefa que geralmente requer um código personalizado.
A definição do modelo pode conter informações adicionais, em especial informações de pré-processamento para cada recurso no conjunto de dados, qual codificador ou decodificador usar para cada recurso, parâmetros arquitetônicos para cada codificador e decodificador e parâmetros de treinamento.
Valores padrão de pré-processamento, treinamento e vários parâmetros de arquitetura de modelo são escolhidos com base em nossa experiência ou são adaptados da literatura acadêmica, permitindo aos novatos treinar facilmente modelos complexos.
Ao mesmo tempo, a capacidade de definir cada um deles individualmente no arquivo de configuração do modelo oferece flexibilidade total aos especialistas.
Cada modelo treinado com o Ludwig é salvo e pode ser carregado posteriormente para obter previsões sobre novos dados. Como exemplo, os modelos podem ser carregados em um ambiente de serviço para fornecer previsões em aplicativos de software.
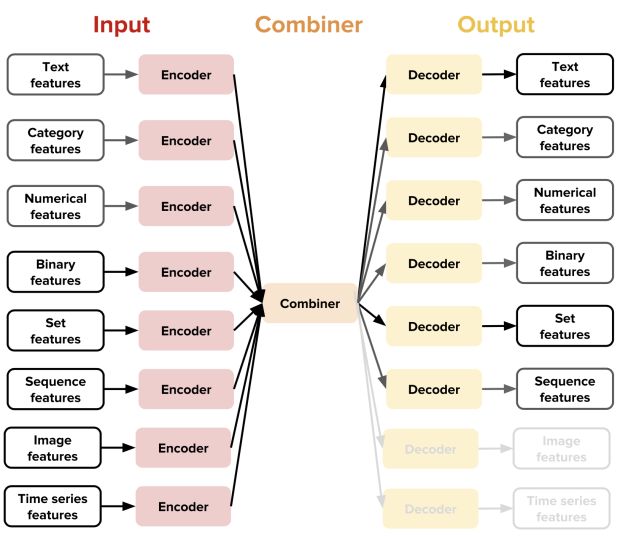
A principal nova ideia introduzida pelo Ludwig é a noção de codificadores e decodificadores específicos para tipos de dados, o que resulta em uma arquitetura altamente modularizada e extensível: cada tipo de dado suportado (texto, imagens, categorias e assim por diante) possui uma função específica de pré-processamento.
Em suma, os codificadores mapeiam os dados brutos para os tensores e os decodificadores mapeiam os tensores para os dados brutos.
Com esse design, o usuário tem acesso a combinadores (componentes de cola da arquitetura) que combinam os tensores de todos os codificadores de entrada, processam-nos e retornam os tensores a serem usados para os decodificadores de saída.
Por exemplo, o combinador de concatenação padrão do Ludwig concatena as saídas de diferentes codificadores, passa-as por camadas totalmente conectadas e fornece a ativação final como entrada para decodificadores de saída.
Outros combinadores estão disponíveis para outros casos de uso, e muitos mais podem ser facilmente adicionados através da implementação de uma interface de função simples.
Ao compor esses componentes específicos do tipo de dados, os usuários podem fazer o Ludwig treinar modelos em uma ampla variedade de tarefas.
Por exemplo, combinando um codificador de texto e um decodificador de categoria, o usuário pode obter um classificador de texto, enquanto a combinação de um codificador de imagem e um decodificador de texto permitirá que o usuário obtenha um modelo de legenda de imagem.
Cada tipo de dados pode ter mais de um codificador e decodificador. Por exemplo, o texto pode ser codificado com uma rede neural convolucional (CNN), uma rede neural recorrente (RNN) ou outros codificadores.
O usuário pode, então, especificar qual deles utilizar e seus hiperparâmetros diretamente no arquivo de definição de modelo sem precisar escrever uma única linha de código.
Essa versátil e flexível arquitetura de decodificador-codificador facilita para praticantes de deep learning menos experientes treinarem modelos para diversas tarefas de machine learning, como classificação de texto, classificação de objeto, legendagem de imagem, marcação de sequência, regressão, modelagem de linguagem, tradução automática, previsão de séries temporais e resposta a perguntas.
Isso abre uma variedade de casos de uso que normalmente estão fora do alcance de profissionais inexperientes e permite que usuários experientes em um domínio abordem novos domínios.
No momento, o Ludwig contém codificadores e decodificadores para valores binários, números flutuantes, categorias, sequências discretas, conjuntos, malas, imagens, texto e séries temporais, juntamente com a capacidade de carregar alguns modelos pré-treinados (por exemplo, incorporação de palavras), mas planejamos expandir os tipos de dados suportados em versões futuras.
Além de sua acessibilidade e arquitetura flexível, o Ludwig oferece benefícios adicionais para não programadores. O Ludwig incorpora um conjunto de utilitários de linha de comando para treinamento, teste de modelos e obtenção de previsões.
Ampliando sua facilidade de uso, a toolbox fornece uma API programática que permite aos usuários treinar e usar um modelo com apenas algumas linhas de código.
Além disso, ele inclui um conjunto de outras ferramentas para avaliar modelos, comparando seu desempenho e previsões por meio de visualizações e extraindo os pesos e ativações do modelo a partir deles.
Finalmente, a capacidade de treinar modelos em várias GPUs localmente e de maneira distribuída através do uso do Horovod, um framework treinamento distribuído open source, possibilita iterar em modelos e obter resultados rapidamente.
Usando o Ludwig
Para entender melhor como usar o Ludwig para aplicações do mundo real, vamos criar um modelo simples com a toolbox. Neste exemplo, criamos um modelo que prevê o gênero e o preço de um livro, de acordo com seu título, autor, descrição e capa.
Treinando o modelo
Nosso conjunto de dados de livros se parece com o seguinte:
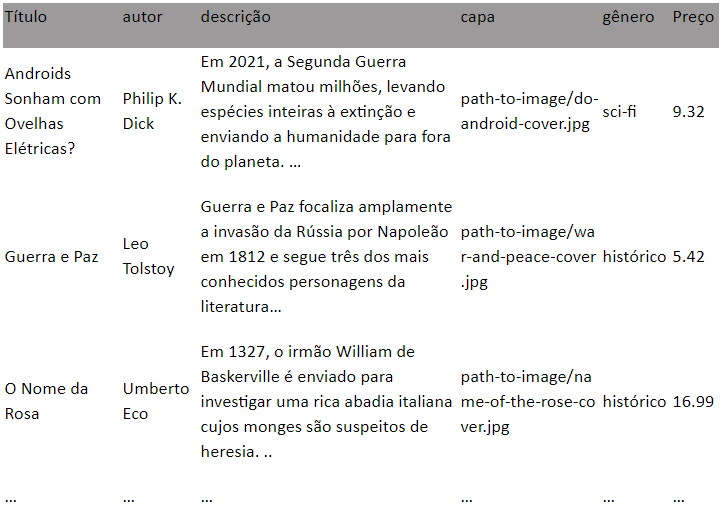
Para aprender um modelo que usa o conteúdo do título, autor, descrição e colunas de capa como entradas para prever os valores nas colunas de gênero e preço, a definição do modelo YAML seria:
input_features:
–
name: title
type: text
–
name: author
type: category
–
name: description
type: text
–
name: cover
type: image
output_features:
–
name: genre
type: category
–
name: price
type: numerical
training:
epochs: 10Começamos o treinamento digitando o seguinte comando no nosso console:
ludwig train –data_csv path/to/file.csv –model_definition_file model_definition.yamlCom esse comando, o Ludwig executa uma divisão aleatória dos dados em conjuntos de treinamento, validação e teste, faz o pré-processamento deles e constrói quatro codificadores diferentes para as quatro entradas e um combinador e dois decodificadores para os dois destinos de saída.
Em seguida, ele treina o modelo no conjunto de treinamento até que a precisão no conjunto de validação pare de melhorar ou o número máximo de dez épocas seja atingido.
O progresso do treinamento será exibido no console, mas o TensorBoard também pode ser usado.
Os recursos de texto são codificados por padrão com um codificador CNN, mas podemos usar, digamos, um codificador RNN que utilize um LSTM bidirecional com um tamanho de estado de 200 para codificar o título. Nós precisaríamos apenas mudar a definição do codificador de título para:
name: title
type: text
encoder: rnn
cell_type: lstm
bidirectional: trueSe quiséssemos alterar os parâmetros de treinamento, como número de épocas, taxa de aprendizado e tamanho do lote, alteraríamos a definição do modelo da seguinte forma:
input_features:
– …
output_features:
– …
training:
epochs: 100
learning_rate: 0.001
batch_size: 64Todos os parâmetros sobre como realizar o pré-processamento de divisão e de dados, os parâmetros de cada combinador de codificador e decodificador possuem valores padrão, mas eles são configuráveis.
Consulte o guia do usuário para descobrir a ampla variedade de definições de modelo e parâmetros de treinamento disponíveis, e dê uma olhada nos nossos exemplos para ver como o Ludwig pode ser usado para várias tarefas diferentes.
Visualizando os resultados do treinamento
Após o treinamento, Ludwig cria um diretório de resultados contendo o modelo treinado com seus hiperparâmetros e estatísticas resumidas do processo de treinamento.
Podemos visualizá-los usando uma das várias opções de visualização disponíveis com a ferramenta de visualização, por exemplo:
ludwig visualize –visualization learning_curves –training_stats results/training_stats.jsonIsso exibirá um gráfico que se parece com o seguinte, mostrando a perda e a precisão como funções do número da época do treinamento:
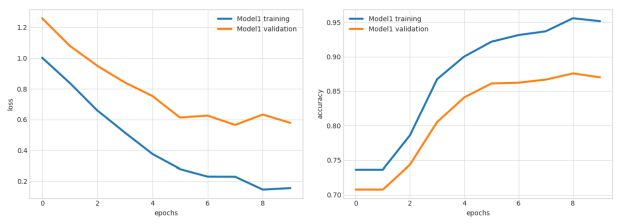
Várias visualizações estão disponíveis. A seção de visualização no guia do usuário oferece mais detalhes.
Previsão de resultados com modelos treinados
Usuários com novos dados que desejam que seus modelos treinados anteriormente prevejam valores de saída de destino podem digitar o seguinte comando:
ludwig predict –data_csv path/to/data.csv –model_path /path/to/modelSe um conjunto de dados contiver informações verdadeiras para comparar com previsões, a execução desse comando retornará previsões de modelo e também algumas estatísticas de desempenho de teste.
Estes podem ser visualizados através do comando visualizar (acima), que também pode ser usado para comparar o desempenho e a previsão de resultados de diferentes modelos. Por exemplo:
ludwig visualize –visualization compare_performance –test_stats path/to/test_stats_model_1.json path/to/test_stats_model_2.jsonRetornará um gráfico de barras comparando os modelos em diferentes medidas:
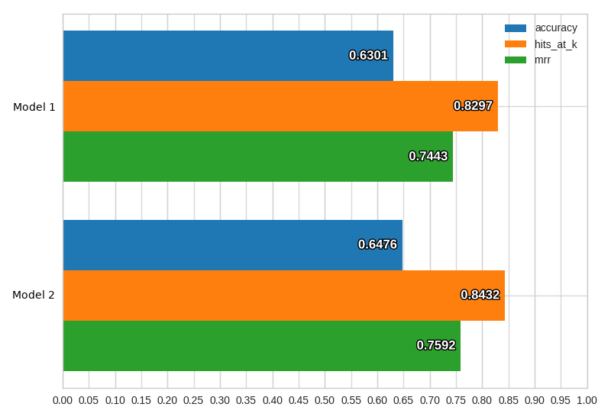
Há também um comando experiment que executa o primeiro treinamento e depois a previsão sem a necessidade de usar dois comandos separados.
Usando a API programática do Ludwig
O Ludwig também fornece uma API programática Python simples que permite aos usuários treinar ou carregar um modelo e usá-lo para obter previsões sobre novos dados:
from ludwig import LudwigModel
# train a model
model_definition = {…}
model = LudwigModel(model_definition)
train_stats = model.train(training_dataframe)
# or load a model
model = LudwigModel.load(model_path)
# obtain predictions
predictions = model.predict(test_dataframe)
model.close()Essa API permite usar modelos treinados com Ludwig dentro do código existente para construir aplicativos sobre eles. Mais detalhes sobre o uso de uma API programática com o Ludwig são fornecidos no guia do usuário e na documentação da API.
Conclusões
Decidimos abrir o código do Ludwig porque acreditamos que ele pode ser uma ferramenta útil para praticantes de machine learning não especializados e desenvolvedores e pesquisadores experientes de deep learning.
Os não especialistas podem treinar e testar rapidamente modelos de deep learning sem precisar escrever código.
Os especialistas podem obter linhas de base fortes para comparar seus modelos e ter uma configuração de experimentação que facilita o teste de novas ideias e a análise de modelos, executando o pré-processamento e a visualização de dados padrão.
Em versões futuras, esperamos adicionar vários novos codificadores para cada tipo de dados, como Transformer, ELMo e BERT para texto, e DenseNet e FractalNet para imagens.
Também queremos inserir tipos de dados adicionais, como áudio, nuvens de pontos e gráficos e, ao mesmo tempo, integrar soluções mais escalonáveis para gerenciar conjuntos de big data, como Petastorm.
O Ludwig foi construído tendo em mente os princípios de extensibilidade e, para facilitar as colaborações da comunidade, fornecemos um guia do desenvolvedor que mostra como é simples inserir tipos de dados adicionais, além de codificadores e decodificadores adicionais para os já existentes.
Esperamos que você goste de usar nossa ferramenta tanto quanto nós gostamos de construí-la!
Se a construção da próxima geração de ferramentas de machine learning lhe interessar, considere se candidatar a um cargo com a Uber AI!
***
Este artigo é do Uber Engineering. Ele foi escrito por Piero Molino, Yaroslav Dudin e Sai Sumanth Miryala. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/introducing-ludwig/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?