


Ao longo dos últimos anos, os avanços em deep learning têm impulsionado um tremendo progresso no processamento de imagens, reconhecimento de fala e prospectiva. Na Uber, aplicamos deep learning em nossos negócios; desde a pesquisa de auto-condução, até a prospecção de viagem e prevenção de fraudes. Deep learning permite que nossos engenheiros e cientistas de dados criem melhores experiências para nossos usuários.
TensorFlow tornou-se uma biblioteca de deep learning preferida na Uber por uma variedade de razões. Para começar, ele é um dos frameworks de código aberto mais amplamente utilizados para deep learning, o que facilita colocar a bordo novos usuários. Ele também combina alto desempenho com uma habilidade para mexer com detalhes do modelo de baixo nível – por exemplo, podemos usar ambas as APIs de alto nível, como a Keras, e implementar nossos próprios operadores personalizados usando o kit de ferramentas CUDA da NVIDIA.
Além disso, o TensorFlow tem suporte end-to-end para uma grande variedade de casos de uso de deep learning, desde a condução de pesquisa exploratória até a implantação de modelos na produção em servidores de nuvem, aplicativos para dispositivos móveis e até mesmo veículos auto-dirigidos.
No mês passado, a Engenharia da Uber apresentou a Michelangelo uma plataforma interna de ML-as-a-service/ML como serviço que democratiza o aprendizado de máquina e facilita a construção e implantação desses sistemas em escala. Neste artigo, retiramos a cortina do Horovod, um componente de código aberto do toolkit de deep learning da Michelangelo, que facilita o início – e aceleração – dos projetos de deep learning distribuídos com o TensorFlow.
Será distribuído
À medida que começamos a treinar mais e mais modelos de aprendizagem de máquina na Uber, seu tamanho e consumo de dados aumentaram significativamente. Em uma grande parte dos casos, os modelos ainda eram pequenos o suficiente para caber em uma ou várias GPUs dentro de um servidor, mas, à medida que os conjuntos de dados cresciam, cresciam também os horários de treinamento, que as vezes demoravam uma semana – ou mais! – para completar. Nos encontramos na necessidade de uma forma de treinar usando muitos dados, mantendo tempos de treinamento curtos. Para conseguir isso, nossa equipe voltou-se para treinamento distribuído.
Começamos testando a técnica de TensorFlow distribuída padrão. Depois de testá-la em alguns modelos, tornou-se evidente que precisávamos fazer dois ajustes.
Primeiro, depois de seguir a documentação e exemplos de código, nem sempre foi claro quais modificações de código precisavam ser feitas para distribuir seu modelo de código de treinamento. O pacote TensorFlow distribuído padrão apresenta muitos novos conceitos: trabalhadores, servidores de parâmetros, tf.Server(), tf.ClusterSpec(), tf.train.SyncReplicasOptimizer() e tf.train.replicas_device_setter() para citar alguns. Embora seja benéfico para certos cenários, isso também introduziu erros difíceis de diagnosticar que retardaram o treinamento.
A segunda questão abordou o desafio da computação na escala da Uber. Depois de executar alguns benchmarks, descobrimos que não conseguimos obter o TensorFlow padrão distribuído para dimensionar, bem como nossos serviços requisitaram. Por exemplo, perdemos cerca da metade de nossos recursos devido às ineficiências de escala ao treinar em 128 GPUs.
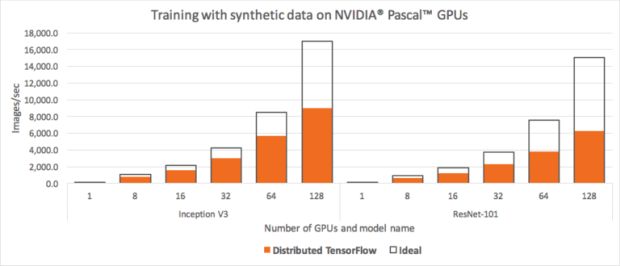
Quando executamos o conjunto de benchmarking TensorFlow padrão em 128 GPUs NVIDIA Pascal, apresentadas na Figura 1 acima, observamos que os modelos Inception V3 e ResNet-101 foram incapazes de alavancar metade de nossos recursos de GPU.
Motivado para tirar o máximo proveito da nossa capacidade de GPU, ficamos ainda mais entusiasmados com o treinamento distribuído depois que o Facebook publicou seu artigo, “Minibatch SGD Preciso, Grande: ImageNet de Treinamento em 1 Hora“, demonstrando o treinamento de uma rede ResNet-50 em uma hora em 256 GPUs, combinando princípios de paralelismo de dados com uma técnica inovadora de ajuste de taxa de aprendizado. Este marco deixou bem claro que o treinamento distribuído em larga escala pode ter um enorme impacto no modelo de produtividade do desenvolvedor.
Alavancando um tipo diferente de algoritmo
Depois disso, começamos a procurar por uma maneira melhor de treinar nossos modelos TensorFlow distribuídos. Uma vez que nossos modelos eram pequenos o suficiente para caber em uma única GPU, ou várias GPUs em um único servidor, tentamos usar a abordagem paralelo de dados do Facebook para o treinamento distribuído.Após essa realização, começamos a procurar por uma maneira melhor de treinar nossos modelos TensorFlow distribuídos.
Uma vez que nossos modelos eram pequenos o suficiente para caber em uma única GPU, ou várias GPUs em um único servidor, tentamos usar a abordagem paralelo de dados do Facebook para o treinamento distribuído.
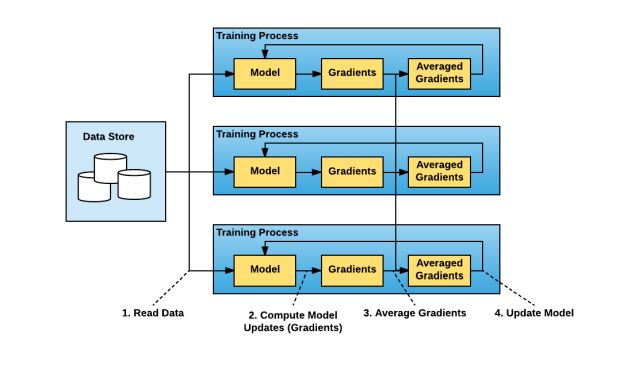
Conceitualmente, o paradigma de treinamento distribuído em paralelo de dados é direto:
1 – Executa várias cópias do script de treinamento e cada cópia:
- lê um pedaço dos dados
- executa isso pelo modelo
- calcula as atualizações do modelo (gradientes)
2 – Gradientes médios entre essas cópias múltiplas
3 – Atualiza o modelo
4 – Repete (desde a Etapa 1a)
O pacote TensorFlow distribuído padrão é executado com uma abordagem de servidor de parâmetros para gradientes de média. Nesta abordagem, cada processo possui uma das duas funções potenciais: um trabalhador ou um servidor de parâmetros. Os trabalhadores processam os dados de treinamento, calculam os gradientes e os enviam para os servidores de parâmetros a serem calculadas as médias.
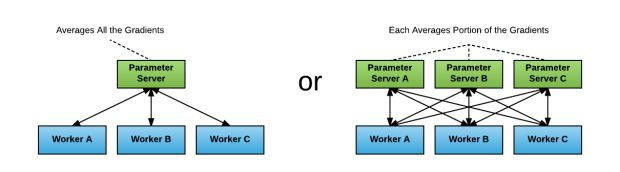
Embora essa abordagem tenha melhorado nosso desempenho, encontramos dois desafios:
- Identificar a proporção certa de trabalhadores para servidores de parâmetros: Se um servidor de parâmetros for usado, provavelmente se tornará um gargalo de rede ou computacional. Se forem utilizados múltiplos servidores de parâmetros, o padrão de comunicação torna-se “tudo para todos”, o que pode saturar as interconexões de rede.
- Lidar com a aumentada complexidade do programa TensorFlow: Durante o nosso teste, cada usuário de TensorFlow distribuído teve que iniciar explicitamente cada trabalhador e servidor de parâmetros, passar informações de descoberta de serviço como hosts e portas de todos os trabalhadores e servidores de parâmetros, e modificar o programa de treinamento para construir tf.Server() com um tf.ClusterSpec ()apropriado. Além disso, os usuários tiveram que garantir que todas as operações foram colocadas apropriadamente usando tf.train.device_replica_setter() e o código é modificado para usar towers para alavancar várias GPUs dentro do servidor. Isso muitas vezes levou a uma curva de aprendizado acentuada e uma quantidade significativa de reestruturação de código, levando para longe o tempo da modelagem real.
No início de 2017, o Baidu publicou um artigo intitulado “Trazendo Técnicas de HPC para Deep Learning“, evangelizando um algoritmo diferente para gradientes de média e comunicando esses gradientes a todos os nodes (etapas 2 e 3 acima), denominados ring-allreduce, bem como um fork de TensorFlow através do qual eles demonstraram um rascunho de implementação deste algoritmo. O algoritmo baseou-se na abordagem introduzida no artigo de 2009 “Algoritmos de redução total de ideal largura de banda para clusters de estações de trabalho“, de Patarasuk e Yuan.
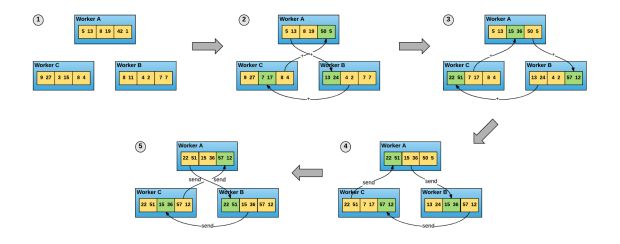
No algoritmo de redução total do anel, cada um dos nodes N se comunica com dois dos seus pares 2*(N-1) vezes. Durante esta comunicação, um node envia e recebe pedaços do buffer de dados. Nas primeiras iterações N-1, os valores recebidos são adicionados aos valores no buffer do node. Nas segundas iterações N-1, os valores recebidos substituem os valores mantidos no buffer do node. O artigo de Baidu sugere que esse algoritmo possui ideal largura de banda, o que significa que, se o buffer for grande o suficiente, ele utilizará de maneira otimizada a rede disponível.
Além de ser o ideal da rede, a abordagem da redução total é muito mais fácil de entender e adotar. Os usuários utilizam uma implementação da Interface de Passagem de Mensagens (MPI), como Open MPI para iniciar todas as cópias do programa TensorFlow. O MPI, então, configura de forma transparente a infraestrutura distribuída necessária para que os trabalhadores se comuniquem entre si. Tudo o que o usuário precisa fazer é modificar seu programa para gradientes médios usando uma operação allreduce().
Apresentando Horovod
A percepção de que uma abordagem de redução total do anel pode melhorar tanto a usabilidade quanto o desempenho nos motivou a trabalhar em nossa própria implementação para abordar as necessidades de TensorFlow da Uber. Adotamos a implementação esboço do algoritmo de redução total do anel de TensorFlow de Baidu e construímos sobre ele. Apresentamos o nosso processo abaixo:
- Convertemos o código em um pacote Python autônomo, chamado Horovod, com o nome de uma dança folclórica tradicional russa na qual os artistas dançam com os braços unidos em um círculo, muito parecido com o modo como os processos dos TensorFlow distribuídos usam Horovod para se comunicar uns com os outros. Em qualquer momento, várias equipes da Uber podem usar diferentes versões do TensorFlow. Queríamos que todas as equipes pudessem aproveitar o algoritmo de redução total do anel sem precisar atualizar para a versão mais recente do TensorFlow, aplicar patches em suas versões ou mesmo gastar tempo criando o framework. Ter um pacote autônomo nos permitiu reduzir o tempo necessário para instalar o Horovod de aproximadamente uma hora apenas para alguns minutos, dependendo do hardware.
- Substituímos a implementação de redução total do anel de Baidu com NCCL. NCCL é a biblioteca NVIDIA para comunicação coletiva que fornece uma versão altamente otimizada de redução total do anel. O NCCL 2 introduziu a capacidade de executar a redução total em várias máquinas, o que nos permite tirar proveito de suas muitas otimizações de aumento de desempenho.
- Nós adicionamos suporte para modelos que se encaixam dentro de um único servidor, potencialmente em GPUs múltiplas, enquanto a versão original apenas suportou modelos que se encaixam em uma única GPU.
- Finalmente, fizemos várias melhorias da API inspiradas nos comentários recebidos de vários usuários iniciantes. Em particular, implementamos uma operação de transmissão que impõe uma inicialização consistente do modelo em todos os trabalhadores. A nova API nos permitiu reduzir o número de operações que um usuário teve que apresentar ao seu único programa GPU para quatro.
Em seguida, discutimos como você pode usar o Horovod para os casos de uso de aprendizagem de máquina da sua equipe também!
Distribuindo seu trabalho de treinamento com Horovod
Enquanto o paradigma do servidor de parâmetros para o treinamento de TensorFlow distribuído geralmente requer a implementação cuidadosa do código boilerplate importante, Horovod precisa apenas de algumas novas linhas. Abaixo, oferecemos um exemplo de um programa TensorFlow distribuído usando o Horovod:
import tensorflow as tf import horovod.tensorflow as hvd # Initialize Horovod hvd.init() # Pin GPU to be used to process local rank (one GPU per process) config = tf.ConfigProto() config.gpu_options.visible_device_list = str(hvd.local_rank()) # Build model… loss = … opt = tf.train.AdagradOptimizer(0.01) # Add Horovod Distributed Optimizer opt = hvd.DistributedOptimizer(opt) # Add hook to broadcast variables from rank 0 to all other processes during # initialization. hooks = [hvd.BroadcastGlobalVariablesHook(0)] # Make training operation train_op = opt.minimize(loss) # The MonitoredTrainingSession takes care of session initialization, # restoring from a checkpoint, saving to a checkpoint, and closing when done # or an error occurs. with tf.train.MonitoredTrainingSession(checkpoint_dir=“/tmp/train_logs”, config=config, hooks=hooks) as mon_sess: while not mon_sess.should_stop(): # Perform synchronous training. mon_sess.run(train_op)
Neste exemplo, o texto em negrito destaca as mudanças necessárias para distribuir programas de GPU único:
- hvd.init() inicializa Horovod.
- config.gpu_options.visible_device_list = str (hvd.local_rank()) atribui uma GPU a cada um dos processos TensorFlow.
- opt = hvd.DistributedOptimizer (opt) envolve qualquer otimizador TensorFlow regular com otimizador Horovod que cuida de gradientes de média usando a redução total de anel.
- hvd.BroadcastGlobalVariablesHook(0) transmite variáveis do primeiro processo para todos os outros processos para garantir uma inicialização consistente. Se o programa não usa MonitoredTrainingSession, os usuários podem executar as operações hvd.broadcast_global_variables(0) em vez disso.
O usuário pode, então, executar várias cópias do programa em vários servidores usando o comando mpirun:
$ mpirun -np 16 -x LD_LIBRARY_PATH -H server1:4,server2:4,server3:4,server4:4 python train.py
O comando mpirun distribui train.py para quatro nodes e o executa em quatro GPUs por node.
Horovod também pode distribuir programas Keras seguindo os mesmos passos. (Você pode encontrar exemplos de scripts tanto para TensorFlow quanto para Keras na página GitHub do Horovod).
A facilidade de uso, a eficiência de depuração e a velocidade da Horovod tornam-no um companheiro altamente eficaz para engenheiros e cientistas de dados interessados em distribuir um único GPU ou programa de único servidor. Em seguida, apresentamos a Linha de Tempo do Horovod, um meio de fornecer um alto nível de compreensão dos estados dos nodes de trabalhadores durante um trabalho de treinamento distribuído.
Linha de tempo do Horovod
À medida em que trazemos os usuários para o Horovod, percebemos que precisávamos de uma maneira para que eles identificassem facilmente erros em seu código, uma questão comumente enfrentada ao lidar com sistemas distribuídos complexos. Em particular, foi difícil usar linhas de tempo TensorFlow nativas ou o CUDA Profiler porque os usuários são obrigados a coletar e fazer referência cruzada de perfis dos vários servidores.
Com a Horovod, queríamos criar uma maneira de fornecer uma compreensão de alto nível sobre as linhas de tempo de operação entre nodes. Para fazer isso, nós construímos Linha de Tempo Horovod, uma ferramenta de criação de perfil com foco em Horovod compatível com o visualizador de perfis de eventos de rastreamento about:tracing do Chrome. Os usuários podem usar as Linhas de Tempo do Horovod para ver exatamente o que cada node estava fazendo em cada etapa do tempo ao longo de um trabalho de treinamento. Isso ajuda a identificar erros e depurar problemas de desempenho. Os usuários podem habilitar linhas de tempo definindo uma única variável de ambiente e podem visualizar os resultados de perfis no navegador através de chrome://tracing.
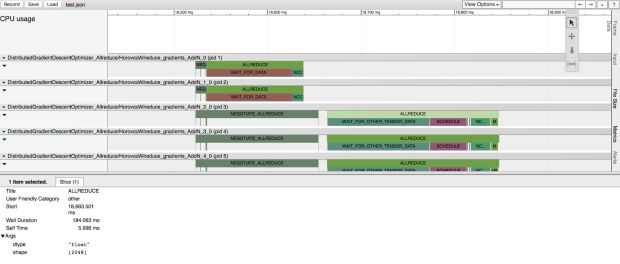
Tensor Fusion
Depois de analisarmos as linhas de tempo de alguns modelos, percebemos que aqueles com uma grande quantidade de tensores, como o ResNet-101, tendiam a ter muitas pequenas operações de allreduce. Conforme observado anteriormente, a redução total do anel utiliza a rede de uma maneira ótima se os tensores forem grandes o suficiente, mas não funciona de forma tão eficiente ou rápida se eles forem muito pequenos. Perguntamos a nós mesmos: e se vários pequenos tensores pudessem ser fundidos antes de realizar a redução total do anel neles?
Nossa resposta: Tensor Fusion, um algoritmo que funde os tensores juntos antes de chamarmos a redução total do anel de Horovod. À medida que experimentamos essa abordagem, observamos melhora de desempenho de até 65% em modelos com um grande número de camadas executadas em uma rede de protocolo de controle de transmissão não-optimizada (TCP). Nós descrevemos como usar o Tensor Fusion, abaixo:
- Determine quais tensores estão prontos para serem reduzidos. Selecione os primeiros poucos tensores que se encaixam no buffer e tenham o mesmo tipo de dados.
- Aloque um buffer de fusão se não foi alocado anteriormente. O tamanho padrão do buffer de fusão é de 64 MB.
- Copie dados de tensores selecionados para o buffer de fusão.
- Execute a operação de redução total do anel no buffer de fusão.
- Copie os dados do buffer de fusão para os tensores de saída.
- Repita até que não haja mais tensores para reduzir no ciclo.
Com Horovod, Tensor Fusion e outros recursos construídos sobre o Michelangelo, podemos aumentar a eficiência, a velocidade e a facilidade de uso em todos os nossos sistemas de aprendizagem de máquina. Na nossa próxima seção, compartilhamos benchmarks reais que mostram o desempenho da Horovod.
Benchmarks do Horovod
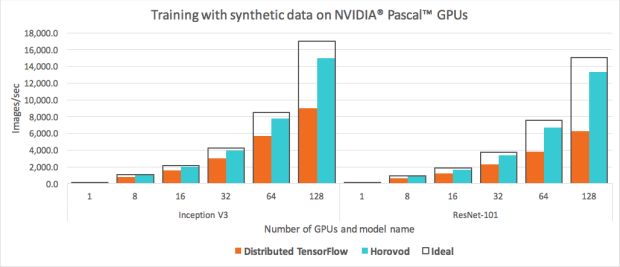
Nós re-executamos os benchmarks TensorFlow oficiais modificados para usar o Horovod e comparamos o desempenho com o TensorFlow distribuído regular. Conforme ilustrado na Figura 6, acima, observamos grandes melhorias em nossa capacidade de escala; já não perdíamos metade dos recursos da GPU – de fato, dimensionar usando os modelos Inception V3 e ResNet-101 alcançou uma marca de eficiência de 88%. Em outras palavras, o treinamento era cerca de duas vezes mais rápido que o TensorFlow distribuído padrão.
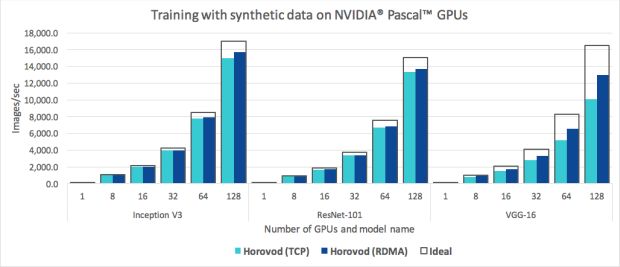
Uma vez que tanto o MPI como o NCCL suportam redes compatíveis de acesso direto remoto à memória (RDMA) (por exemplo, via InfiniBand ou RDMA em Ethernet Convergente), executamos conjuntos adicionais de testes de benchmarking usando placas de rede RDMA para determinar se elas nos ajudaram a aumentar a eficiência em relação à rede TCP.
Para os modelos Inception V3 e ResNet-101, descobrimos que o RDMA não melhorou significativamente nosso desempenho e alcançou apenas um aumento de três a quatro por cento em relação à rede TCP. O RDMA, no entanto, de fato ajudou o Horovod a exceder 90% a eficiência de escala em ambos os modelos.
Enquanto isso, o modelo VGG-16 experimentou uma aceleração significativa de 30% quando alavancamos a rede RDMA. Isso pode ser explicado pelo alto número de parâmetros do modelo VGG-16, causado pelo uso de camadas totalmente conectadas combinadas com seu pequeno número de camadas. Essas características incluíram o caminho crítico da computação GPU para a comunicação e criaram um gargalo de rede.
Esses benchmarks demonstram que o Horovod realiza uma boa escala nas redes TCP simples e nas redes com capacidade RDMA, embora os usuários com rede RDMA possam comprimir o desempenho ideal e experimentar um ganho significativo de eficiência ao usar modelos com um alto número de parâmetros do modelo, como o VGG-16.
Com o Horovod, nós apenas tocamos a superfície quando se trata de explorar otimizações de desempenho em deep learning; no futuro, pretendemos continuar a alavancar a comunidade de código aberto para extrair ganhos de desempenho adicionais com nossos sistemas e frameworks de aprendizagem de máquina.
Próximos passos
No início deste ano, abrimos Horovod em código aberto para oferecer modelos acessíveis e escaláveis de aprendizagem de máquina a todos. Existem algumas áreas em que estamos trabalhando ativamente para melhorar Horovod, incluindo:
- Tornando mais fácil instalar o MPI: Embora seja relativamente fácil instalar o MPI em uma estação de trabalho, a instalação do MPI em um cluster normalmente requer algum esforço; por exemplo, há vários gerenciadores de carga de trabalho disponíveis e diferentes ajustes devem ser feitos dependendo do hardware da rede. Estamos desenvolvendo projetos de referência para executar o Horovod em um cluster; para isso, esperamos trabalhar com a comunidade MPI e fornecedores de hardware de rede para desenvolver instruções para instalar MPI e drivers relevantes.
- Recolhendo e compartilhando aprendizagens sobre o ajuste de parâmetros do modelo para deep learning distribuída: O artigo do Facebook “Preciso, Grande Minibatch SGD: Treinando ImageNet em uma hora” descreve os ajustes necessários para modelar hiperparâmetros para alcançar a mesma ou maior precisão em um trabalho de treinamento distribuído em comparação com o treinamento do mesmo modelo em uma única GPU, demonstrando a viabilidade de treinar um modelo TensorFlow em 256 GPUs. Acreditamos que esta área de pesquisa de deep learning ainda está em seus estágios iniciais e espero colaborar com outras equipes sobre abordagens para aprimorar o treinamento de deep learning.
- Adicionando exemplos de modelos muito grandes: O Horovod atualmente suporta modelos que se encaixam em um servidor, mas podem abranger múltiplos GPUs. Estamos ansiosos para desenvolver mais exemplos para grandes modelos abrangendo múltiplas GPUs e incentivar outros a testar o Horovod também nesses tipos de modelos.
Esperamos que a simplicidade da Horovod permita que outros adotem treinamento distribuído e melhor aproveitem seus recursos de computação para deep learning. Nos parabenizamos com comentários e contribuições: por favor, informe todos os problemas que você encontra, compartilhe avanços e envie solicitações de envio.
Se você está interessado em trabalhar com Uber para democratizar o machine learning em escala, considere candidatar-se a um cargo na empresa.
***
Este artigo é do Uber Engineering. Ele foi escrito por Alex Sergeev e Mike Del Balso. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/horovod/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?