

Que os conteúdos de um site devem ser únicos, incríveis e geniais, isso qualquer pessoa que conhece o mínimo que seja de SEO já está mais do que careca de saber.
Entretanto, mesmo um site ou e-commerce que tenha somente conteúdo de qualidade, exclusivo e original pode sofrer com um grave problema de SEO On Page: o conteúdo duplicado interno, ou seja, dentro do seu próprio domínio. Isso também é conhecido como páginas duplicadas.
O problema de conteúdo duplicado interno à primeira vista é muito, muito simples: sites complexos e/ou mal programados geram URLs diferentes para conteúdos idênticos ou muito parecidos. Porém, muitas vezes nos esbarraremos em grandes dificuldades para lidar com páginas duplicadas, principalmente quando temos que oferecer opção de filtros avançados que geram URLs dinâmicas ou “semi-dinâmicas”.
Temos abaixo os 2 principais casos de conteúdo duplicado:
1. Ausência de URLs amigáveis e uso de parâmetros
Esse problema muito fatalmente ocorrerá em sites que não possuem URLs amigáveis e trabalham baseados em variáveis/parâmetros na URL, que costumam aparecer em uma ordem mais ou menos aleatória, como no exemplo a seguir:
- http://www.conversion.com.br/exemplo/site.php?cidade=sao+paulo&estado=sp&bairro=centro
- http://www.conversion.com.br/exemplo/site.php?cidade=sao+paulo&bairro=centro&estado=sp
- http://www.conversion.com.br/exemplo/site.php?bairro=centro&cidade=sao+paulo&estado=sp
Não precisa ser nenhum gênio da matemática para perceber que em um site com poucas dezenas de páginas, terão sido geradas milhares e milhares de páginas idênticas.
2. URLs diferentes para conteúdos muito parecidos
O problema de conteúdo ou páginas duplicadas também ocorre em sites com URLs diferentes mas título ou conteúdo muito parecido.
Sites de e-commerce, por exemplo, costumam ser um dos maiores prejudicados com o problema de conteúdo duplicado, porque o uso de filtros na busca por produtos, marcas e categorias, mesmo com um bom trabalho de SEO em URLs amigáveis, tende a permitir a indexação de todo esse conteúdo.
Como alguns devem ter em mente, a solução para o conteúdo duplicado é a canonical tag. Entretanto, no e-commerce, mesmo com o uso de canonical tag continuaremos a encontrar conteúdo duplicado ou, o que não é menos grave, o Google poderá indexar menos páginas do site, por ter perdido tempo indexando páginas na prática inúteis, tendo deixado de indexar outras que são mais úteis.
Há casos ainda mais complexos em que se deve decidir se uma página com determinada palavra-chave long tail vale a pena ou deve ser indexada, pela semelhança com outras páginas – uma vez que pode ser entendido como doorway pages (técnica de Black Hat).
Indexação mais lenta, menor aproveitamento de long tail
Sabemos que as palavras-chave de cauda longa são indispensáveis em um trabalho de SEO. É através desse trabalho que o Google determina o campo semântico do site, ponto este que é, no meu entender, um dos principais fatores de rankeamento.
É natural que as páginas mais importantes do site sejam fácil e rapidamente indexadas, principalmente se o site tiver um bom Domain Authority. Porém, mesmo com boa autoridade de domínio pode ficar difícil indexar e, principalmente, manter atualizada as páginas muito específicas e relevantes.
Identificar e corrigir conteúdo duplicado
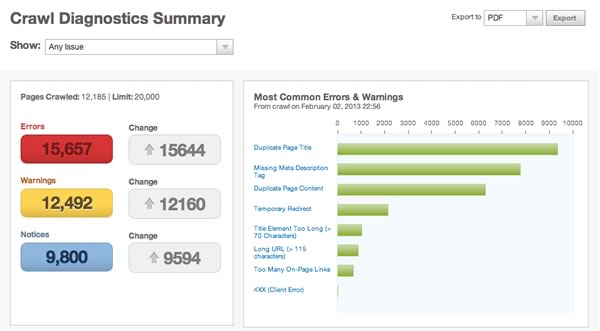
Se o seu site tem URLs amigáveis e for de pequeno porte, é muito possível que não passe por este tipo de problema. Entretanto, se o seu site for de maior porte, você precisará trabalhar com ferramentas específicas para identificar esses problemas, como faz o site SEOmoz (imagem acima) ou Screaming Frog SEO Spider.
Na imagem acima, temos um site que apesar de usar URLs amigáveis tem problemas de páginas com títulos e conteúdos semelhantes, um dos grandes problemas de SEO.
Quanto à resolução desse problema, isso daí deve ser analisado de caso para caso, mas pode consistir em estratégias como:
- Nofollow
- Tag rel=”canonical”
- Solicitação de remoção de conteúdo duplicado no Google Webmaster Tools.
- Melhoria de sua estrutura de URL amigável

De 0 a 10, o quanto você recomendaria este artigo para um amigo?