

Eu sou fã da linguagem SQL. Esta “coroa” já tem 40 anos, mas ainda assim a gente está sempre aprendendo coisas novas. Ou esclarecendo dúvidas antigas.
Uma questão que volta e meia perguntam é sobre performance na execução de comandos CRUD com múltiplas condições: existe diferença entre executar uma operação com múltiplas condições ou executar várias operações com uma única condição?
O bom senso sugere que qualquer operação que dependa de pesquisa deveria se beneficiar da execução de um único comando com múltiplas condições. Pensando no caso de uma operação de DELETE, por exemplo. Deve ser mais vantajoso fazer uma única varredura na tabela testando N condições do que fazer N varreduras, testando uma condição por vez. É a mesma ideia que definir uma lista de livros que se deseja antes de iniciar procura dentro de uma biblioteca.
Pena que ainda existam desenvolvedores que não se preocupam em analisar detalhes tão óbvios e acabam escrevendo códigos ruins. Mas, para os que levam estas questões a sério, como eu, mostro aqui um breve estudo para avaliar performance em alguns cenários.
Definindo cenários
Para responder a questão de performance, é preciso entender que estes números vão depender de uma série de fatores: se as condições são para um ou vários campos, se os campos são indexados ou não, qual o nível de fragmentação dos índices considerados, qual a quantidade de linhas na tabela, qual o tamanho de cada registro, qual a quantidade de registros que são afetados na declaração SQL, etc.
Se ficarmos aqui pensando em todos os fatores que influenciam esta comparação, chegaremos à conclusão que dá para fazer uma tese em mestrado sobre o tema J. Mas a ideia deste artigo é ter uma noção da resposta estudando alguns cenários bem restritos.
Sendo assim, eu resolvi adotar os seguintes critérios para fazer esta pesquisa:
- Todos os testes são feitos sobre uma tabela com layout simples, baseado na tabela Sales.SalesOrderDetails do banco de exemplo AdventureWorks2012 (SQL Server 2012). O script para criação e população desta tabela está disponível neste link;
- A tabela de teste tem tamanho médio, com pouco mais de 121 mil registros e possui apenas dois índices: um clusterizado e outro não-clusterizado;
- Todos os cenários comparam dois tipos de declarações SQL:
- execução de 1 DELETE com 10 condições
- execução de 10 DELETEs com 1 condição
- O critério usado para comparação é o custo total informado no plano de execução de cada consulta;
- Os cenários de avaliação combinam dois parâmetros:
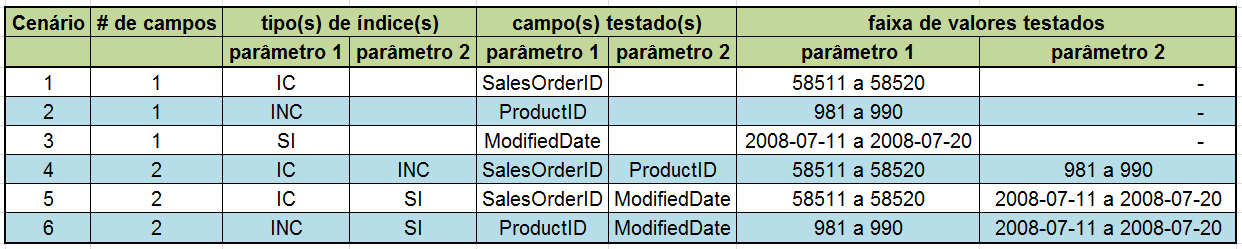
- Número de campos usados como condição – testes com 1 ou 2 campos
- Existência de índice no(s) campo(s) de pesquisa – testes com campos sem índice (SI), com índice clusterizado (IC) e não-clusterizado (INC).
- Quando se usa dois parâmetros simultaneamente, a declaração terá sempre o operador OR na cláusula WHERE para facilitar a lógica das declarações.
Combinando estes parâmetros, defini seis cenários de comparação que são descritos na Tabela 1.
Tabela 1: cenários pesquisados
O script com as declarações SQL de cada cenário está disponível para download aqui.
Os resultados
A seguir, apresento os resultados dos 12 testes (06 cenários com 02 declarações), mas antes é importante explicar alguns detalhes.
O custo total das declarações é facilmente identificado no plano de execução quando analisamos as declarações do tipo 2 (declaração única com múltiplos testes). Porém, quando se trata das declarações do tipo 1 (lote com várias declarações cada uma com um único teste), o plano de execução mostra separadamente o custo de cada uma das 10 declarações que compõem o lote de instruções.
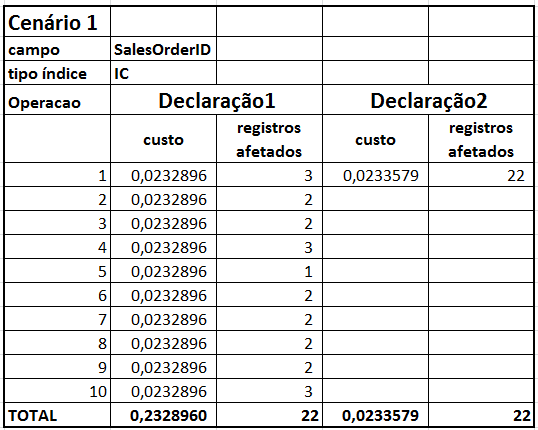
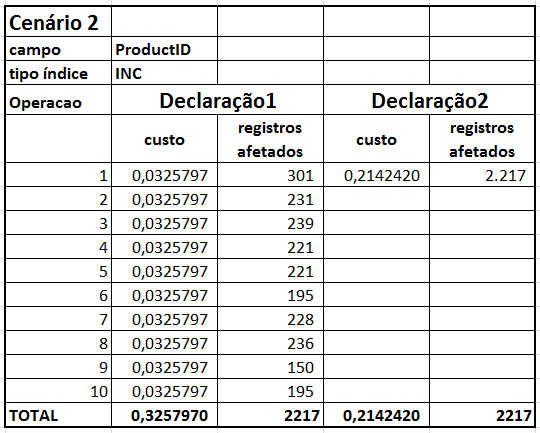
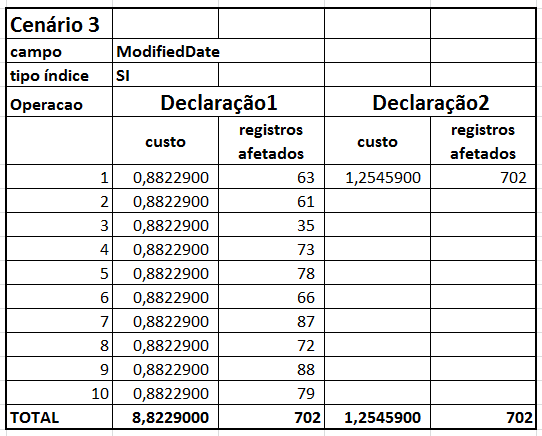
Para facilitar a análise dos resultados, eu apresento na Tabela 2 custos de cada sentença, custo total do lote, o número de registros afetados e o plano de execução das declarações dos tipos 1 e 2 para cada cenário definido.
Tabela 2: resultados das declarações em cada cenário.
| planos execução | Cenario1_1.sqlplan | Cenario1_2.sqlplan |
| planos execução | Cenario2_1.sqlplan | Cenario2_2.sqlplan |
| planos execução | Cenario3_1.sqlplan | Cenario3_2.sqlplan |
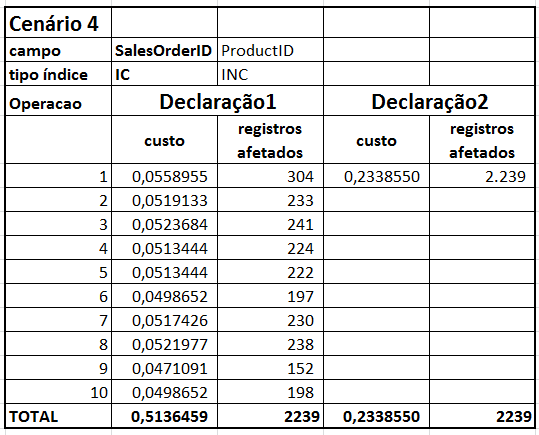
| planos execução | Cenario4_1.sqlplan | Cenario4_2.sqlplan |
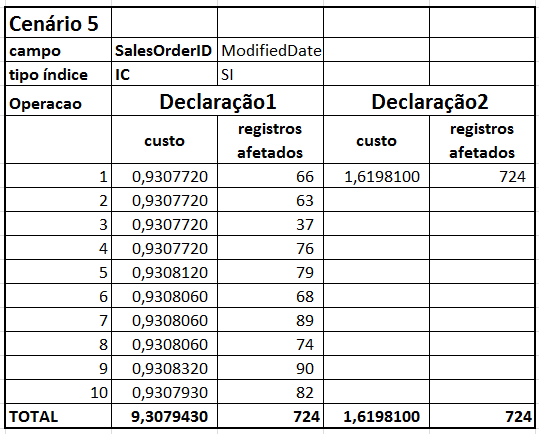
| planos execução | Cenario5_1.sqlplan | Cenario5_2.sqlplan |
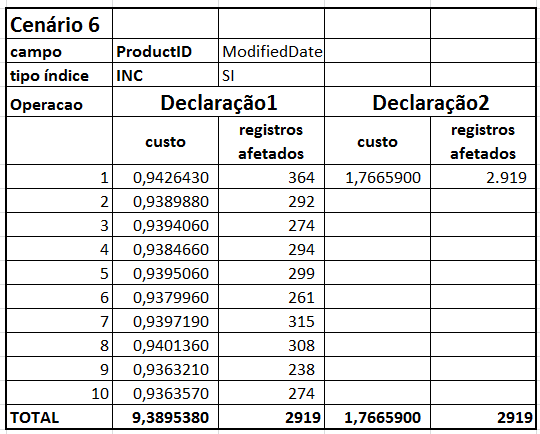
| planos execução | Cenario6_1.sqlplan | Cenario6_2.sqlplan |
Analisando os números
Eu coletei este monte de números na intenção de responder algumas perguntas. Obviamente estas “respostas” precisam ser entendidas dentro de um contexto bem limitado, dada a simplicidade dos testes que mostrei aqui.
Pergunta 1: qual é a vantagem de se executar DELETEs com base em campos indexados? Todo mundo que mexe com bancos de dados sabe que é vantagem fazer pesquisas sobre campos indexados, mas a maioria das pessoas (e eu me incluo neste grupo) não faz ideia do quanto é vantajoso usar índices.
Para simplificar a conversa, vou analisar apenas os resultados dos cenários 1, 2 e 3, que analisam apenas um único campo. Observe a Tabela 3.
Tabela 3: Desempenho conforme o tipo de índice usado
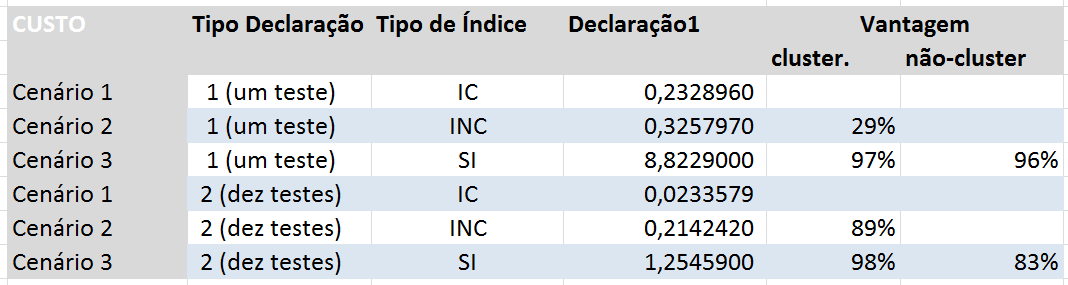
Observe que nos testes simples (declaração tipo 1, com apenas um valor pesquisado), a consulta com índice clusterizado (IC) é significativamente mais rápida do que aquela com índice não-clusterizado (INC): custo 29% menor.
Verificando os planos de execução que nos dois casos (Tabela 2), vemos que as operações executadas são CLUSTERED INDEX DELETE (CID) no Cenário 1 e NON-CLUSTERED INDEX SEEK seguido do CID no Cenário 2. Isso acontece porque um INC é, por assim dizer, um catálogo criado sobre a tabela, enquanto que um IC é uma forma de armazenar os dados de modo que as páginas de dados, por si só, já são um catálogo. Portanto era de se esperar que houvesse esta vantagem.
Quando a análise compara os custos das declarações do tipo 2 (com 10 valores pesquisados), aí a diferença dispara: custo do IC é 89% menor do que o do INC. Esse resultado pode ter sido afetado por diversos fatores, mas neste caso especial provavelmente a diferença acontece por causa dos valores que são pesquisados.
Observe na Tabela 1 que os valores escolhidos para os três campos são sequenciais. Porém, como eu já comentei, um índice clusterizado define a forma com os dados são armazenados na página de dados. Sendo assim, os registros afetados pela consulta baseada no IC provavelmente estão todos gravados na mesma página de dados, reduzindo dramaticamente o custo da operação.
Vejamos agora as consultas com IC e SI. Aqui as diferenças de custo são estratosféricas: o custo IC É 97% menor nas consultas tipo 1, enquanto que nas consultas tipo 2 esta diferença é um pouco maior, chegando a 98%.
Olhando novamente os planos de execução, vemos que o otimizador de consultas faz um CLUSTERED INDEX SCAN seguido do CID nas consultas do Cenário 3. Ou seja, apesar das duas declarações serem executadas sobre o índice clusterizado da tabela, o fato de haver um CLUSTERED INDEX SCAN deixou estas consultas quase 100 vezes mais lentas do que as que se baseavam diretamente no IC.
Pergunta 2: é vantagem fazer uma única declaração pesquisando por vários valores? Novamente uma resposta fácil J. A Tabela 4 traz os resultados e vemos que as declarações do tipo 2 (uma declaração com N condições) têm custo menor em todos os 6 cenários pesquisados.
Tabela 4: Desempenho com base no tipo de declaração SQL
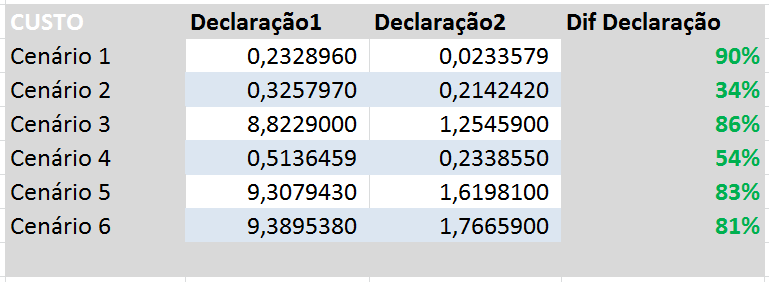
Note que no Cenário 1 (consultas com IC) que o custo para se executar 1 consulta com 10 condições é 90% menor (ou seja, 1/10 do total) do que executar 10 consultas com 1 condição. Portanto o custo é praticamente o mesmo se a consulta tiver uma ou dez condições. Veja Tabela 2 os custos de cada declaração executada neste cenário.
Pergunta 3: é vantagem fazer uma declaração pesquisando dois campos ao mesmo tempo? Aqui a resposta é mais complicada. E em primeiro lugar, é preciso entender como combinar os cenários para comparar os resultados.
Olhando a Tabela 1, você vai notar que os cenários foram definidos de tal maneira que representassem uma composição dos cenários anteriores. Por exemplo, o Cenário 4 (testes no campos SalesOrderID e ProductID) é uma combinação dos cenários 1 e 2. Isso quer dizer que a execução das consultas do cenário 4 causa o mesmo efeito na tabela que a execução conjunta das consultas dos cenários 1 e 2.
Graças a esta estrutura dos testes, podemos comparar:
- Cenário 4 com os resultados acumulados dos cenários 1 e 2
- Cenário 5 com os resultados acumulados dos cenários 1 e 3
- Cenário 6 com os resultados acumulados dos cenários 2 e 3
Considerando esta lógica, a Tabela 5 mostra as proporções entre as combinações de cenários.
Tabela 5: comparativo do custo acumulado dos cenários equivalentes
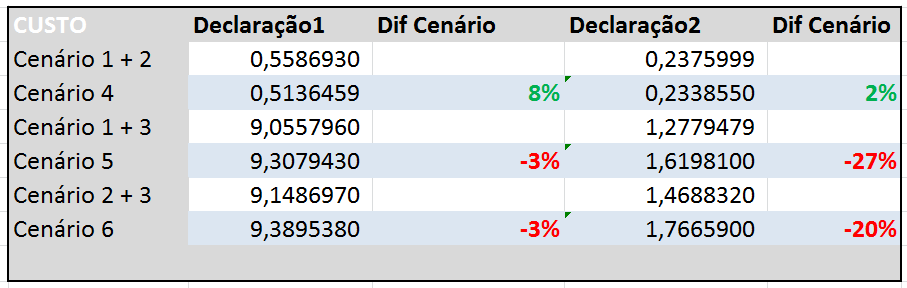
Lamentavelmente a Tabela 3 não mostra resultado muito expressivos. As proporções agora são muito parecidas em 4 das 6 comparações. Aparentemente não há vantagem significativa de se juntar duas declarações pesquisando um campo para se escrever uma única declaração pesquisando dois campos ao mesmo tempo.
Aparecem diferenças importantes apenas nas declarações do tipo 2 nos cenários 5 e 6 (20% e 27%). Mas isso acontece por conta da natureza das condições destas consultas, como descrevo a seguir.
Ao combinar pesquisas em dois campos, o otimizador de consultas tomou decisões diferentes conforme a indexação dos campos escolhidos. Nas declarações do tipo 2 no cenário 4, ele usou um CLUSTERED INDEX SEEK e um NON-CLUSTERED INDEX SEEK, que são, para todos os efeitos práticos, os mesmos operadores realizados nos cenários 1 e 2 (o leitor mais observador perceberá que estou assumindo aqui que os operadores CLUSTERED INDEX DELETE e CLUSTERED INDEX SEEK pesquisam dados de modo semelhante e tem um custo de execução praticamente idênticos).
Porém a coisa muda nos cenários 5 e 6. Ao se deparar com dois campos que exigem operações distintas, o otimizador de consultas decide executar um CLUSTERED INDEX SCAN pros dois campos testados (veja isso nos planos de execução das consultas do tipo 2 nos cenários 5 e 6). Por isso a consulta combinada ficou mais lenta do que as consultas individuais.
Resumindo os resultados da pergunta 3, concluímos que não há uma vantagem significativa de se combinar numa única declaração SQL condições sobre mais de um campo. Os resultados são praticamente equivalentes quando os campos são indexados, mas a performance caiu significativamente quando um dos campos pesquisados não tiver índices.
Conclusão
Apesar de este estudo ser bem simples e sem nenhuma pretensão de dar respostas definitivas sobre o tema, eu entendo que estes números endossam algumas noções que adotamos no dia-a-dia.
Estas noções são:
- É extremamente vantajoso executar DELETEs fazendo a pesquisa pelo índice clusterizado da tabela; se não for possível usar o índice clusterizado, é interessante indexar (INC) o campo da pesquisa;
- É vantajoso organizar todos os valores pesquisados no mínimo de operações possível. Nos testes aqui realizados a declaração única teve desempenho melhor em todos os cenários testados;
- Não há vantagem em se incluir na mesma declaração SQL pesquisas sobre diferentes campo. Além disso foi observada uma desvantagem clara quando um dos campos testados não é indexado. Portanto esta prática é desaconselhada.
Como eu disse anteriormente, os resultados mostrados aqui são aplicáveis apenas a cenários muito parecidos com os que foram testados aqui. Para outras situações, é recomendável que o leitor faça seus próprios testes usando o método aqui descrito (e eu recomendo fortemente que o faça J).
Até a próxima!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?