

E aí pessoal, tudo bem?
É quase um milagre este artigo sair com tão pouco tempo desde o último, mas o fato é que estou muito empolgado com meus estudos e o curso da Udemy que comentei no último artigo, tanto que comecei a aplicar algumas coisas na prática!
Hoje quero mostrar um pequeno programa que criei para testar e praticar as técnicas de Machine Learning na categorização de textos. É apenas um protótipo que usa matérias jornalísticas, mas você pode baixá-lo para testar e estudar!
Importante: Meu objetivo não é abordar profundamente as diferentes técnicas, abordagens e algoritmos disponíveis, pois meu conhecimento ainda não me permite. Ao invés disso, quero te mostrar como é possível aplicar tais conhecimentos e, quem sabe, te estimular a também estudar o assunto!
Como você pode ver no aquivo em meu Github, o programa ficou com 152 linhas de código, o que é pouco mas vou me concentrar nas partes relacionadas ao processamento dos dados, treinamento e predição que são o foco do artigo de hoje.
Acabei criando um repositório em meu github para este projeto, assim fica mais fácil baixar, instalar e testar o código!
O programa pode ser dividido nas seguintes etapas:
- Baixar e extrair o conteúdo das matérias a partir de um CSV com links e categorias;
- Limpar o conteúdo e deixar apenas o que é relevante para o treinamento do modelo;
- Criar o Bag of Words e treinar o modelo que fará a categorização;
- Categorizar novos links com o modelo treinado.
1. Baixar e extrair o conteúdo (Goose, o achado!)
Se você já criou algum tipo de web scraping, sabe como pode ser chato trabalhoso. Para os meus propósitos, era necessário extrair das páginas HTML apenas o conteúdo da matéria sem poluir o resultado com tags ou textos periféricos. Depois de muitas tentativas usando requests, lxml e regex, encontrei o projeto goose-extractor no pypi.

Em uma olhada rápida na documentação, percebemos que esse projeto é perfeito para o nosso caso e em 3 linhas ele resolve o problema:
from goose import Goose .... goose = Goose() article = goose.extract(link) text = article.cleaned_text
Basta passar o link da página e o Goose faz o resto! Ele também permite acessar outros atributos da página, como o título da matéria, descriptors, etc. Vale a pena conferir!
Por se tratar de uma tarefa I/O Bound e serem mais de 700 links para baixar, estou usando a classe ThreadPoolExecutor do backport futures. O uso é muito simples e você pode saber mais na documentação do projeto!
2. Limpar o conteúdo (NLTK)
Com o texto das matérias em mãos, precisamos remover caracteres e palavras que podem atrapalhar o algoritmo de categorização, deixando apenas as palavras que possam contribuir com o “entendimento” do texto. Na primeira etapa, removo praticamente tudo que não for texto:
import unicodedata
...
def remove_nonlatin(string):
new_chars = []
for char in string:
if char == '\n':
new_chars.append(' ')
continue
try:
if unicodedata.name(unicode(char)).startswith(('LATIN', 'SPACE')):
new_chars.append(char)
except:
continue
return ''.join(new_chars)
...
text = remove_nonlatin(to_unicode(text))
Depois disso, precisamos remover as chamadas stop words que, em resumo, são palavras que se repetem muito em qualquer texto e podem prejudicar a análise feita pelo algoritmo. Isso é feito com a ajuda do projeto NLTK.
O NLTK pode ser instalado via pip mas depois da sua instalação é preciso baixar o pacote stopwords pelo gerenciador do próprio NLTK. Vou deixar lincadas as instruções das 2 etapas.
Depois de tudo instalado, é fácil remover as stop words dos nossos textos:
from nltk.corpus import stopwords
...
stops = set(stopwords.words("portuguese"))
words = ' '.join([w for w in words if not w in stops])
Por fim, criamos um DataFrame pandas para reunir os links, as categorias e os textos processados:
from pandas import DataFrame ... lines = [] words = pre_processor(link) lines.append((link, categ, words)) ... df = DataFrame(lines) df.columns = ['link', 'categoria', 'texto']
3. Bag of words
Em resumo rápido, bag of words é um modelo de representação textual que ignora a ordem e a gramática das palavras, mas preserva sua multiplicidade. Um exemplo pode nos ajudar:
O texto: “Rafael gosta muito de assistir filmes. A Ana gosta de filmes também” é transformado em uma lista de palavras:
["Rafael", "gosta", "muito", "de", "assistir", "filmes", "a", "Ana", "também"]
Depois disso, o modelo gera uma lista com a frequência que cada palavra aparece no texto : [1, 2, 1, 2, 1, 2, 1, 1, 1].
Este processo, de traduzir palavras em números, é necessário, pois os algoritmos que vamos usar para classificar os textos só aceitam/”entendem” números. Para nossa sorte, o scikit-learn, uma das principais bibliotecas do tipo em Python, já tem uma classe para ajudar neste processo.
Abaixo, vou mostrar a função de treinamento por completo. Acredito que seja mais fácil explicar assim:
import sklearn
from sklearn.externals import joblib
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer
def train(df, fit_file):
print "\nTraining..."
df = df.dropna()
train_size = 0.8
vectorizer = CountVectorizer(
analyzer="word",
tokenizer=None,
preprocessor=None,
stop_words=None
)
logreg = LogisticRegression()
pipe = Pipeline([('vect', vectorizer), ('logreg', logreg)])
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(
df.texto, df.categoria, train_size=train_size
)
pipe.fit(X_train, Y_train)
accuracy = pipe.score(X_test, Y_test)
msg = "\nAccuracy with {:.0%} of training data: {:.1%}\n".format(train_size, accuracy)
print msg
pipe.fit(df.texto, df.categoria)
joblib.dump(pipe, fit_file)
Das linhas 11 a 16, criamos a instância que vai montar o modelo bag of words dos textos que baixamos, mas por enquanto nada foi feito.
Na linha 17, é criada a instância que efetivamente vai analisar nossos dados e fazer predições. Como o nome sugere, será usada uma técnica chamada Regressão Logística para fazer a classificação dos textos. Eu testei algumas técnicas diferentes de classificação, mas esta apresentou os melhores resultados, chegando a 84% de acerto! Você pode conferir os teste que fiz neste link aqui!
Na linha 18, reunimos os 2 processos anteriores em um pipeline. Isto foi necessário para facilitar a preservação e armazenamento do modelo treinado. Vamos falar disso daqui a pouco!
Da linha 19 a 21 usamos uma função do scikit-learn para dividir nossa massa de dados em 80% para treino e 20% para testar a precisão do modelo.
Da linha 22 a 25, nós treinamos nosso modelo, avaliamos a precisão do mesmo e mostramos essa informação no terminal.
Finalizando, na linha 26 o modelo é treinado novamente, mas agora com 100% dos dados, e na linha 27 usamos outra ferramenta do scikit-learn para salvar o modelo treinado em disco, pois não precisamos refazer todo este processo toda vez que o programa for usado.
4. Pronto para uso!
Finalmente! O programa está pronto para categorizar novos textos! Vamos ver a função predict!
def predict(url, fit_file):
pipe = joblib.load(fit_file)
words = pre_processor(url)
resp = pipe.predict([words])
print "\nCategory: %s \n" % resp[0]
resp = zip(pipe.classes_, pipe.predict_proba([words])[0])
resp.sort(key=lambda tup: tup[1], reverse=True)
for cat, prob in resp:
print "Category {:16s} with {:.1%} probab.".format(cat, prob)
A função recebe como parâmetros uma URL (que vamos categorizar) e o caminho para o arquivo salvo em disco com nosso modelo treinado.
A linha 2 carrega o pipeline que salvamos no disco como o CountVectorizer e o LogisticRegression.
A linha 3 usa uma função para baixar e processar o texto da URL fornecida. Basicamente, os passos 1 e 2 desse artigo.
A linha 4 usa nosso pipeline para criar o bag of words do texto e fazer a predição de qual a categoria que melhor representa este texto.
As linhas de 6 a 9 mostram todas as categorias que nosso modelo conhece e as respectivas probabilidades em relação ao texto que está sendo categorizado.
Vamos ver como funciona!
Agora que já falamos sobre as principais partes do programa, vamos ve-lo em ação!
Para testar no seu computador, alem de baixar o arquivo do programa e a lista de links, você precisará instalar as dependências, tudo via pip install:
- futures
- goose-extractor
- pandas
- nltk
- scikit-learn
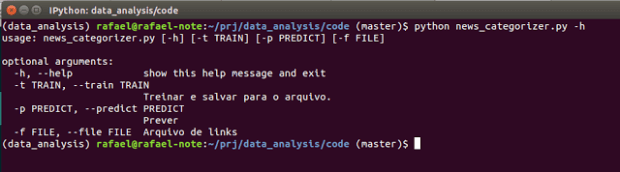
O programa usa 3 parâmetros, FILE é o caminho para o arquivo CSV com os links das matérias que você pode baixar aqui. O formato do arquivo é muito simples e você pode montar o seu com outros links e categorias.
TRAIN é o nome do arquivo com o modelo treinado. Se o arquivo já existir, o programa usa o modelo existente; caso contrário, ele vai baixar os dados e processar.
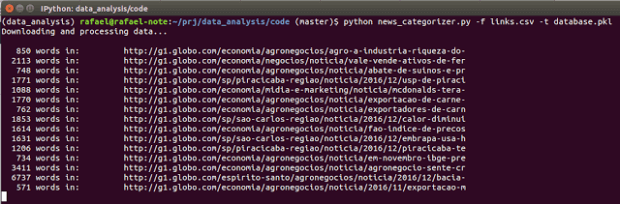
Primeiro, vamos baixar os dados, processá-los e treinar nosso modelo. Esta é a saída do programa mostrando a quantidade de palavras em cada matéria:
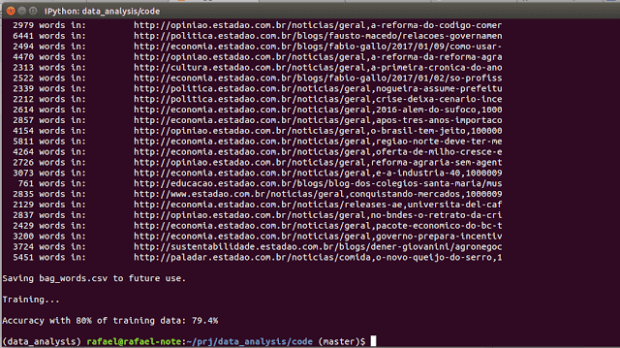
Depois de algum tempo baixando e processando os dados, o programa nos mostra que ele salvou o arquivo bag_words.csv com os dados processados e a precisão do modelo após o treinamento. Chegamos a 79%!
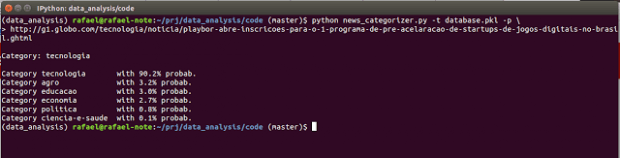
Agora vamos testar se ele acerta a categoria desta matéria do G1 sobre tecnologia:

Concluindo (finalmente!)
Eu adoraria ficar aqui e te mostrar vários exemplos de como o programa acerta a categoria de várias matérias, mas você deve estar bem cansado – eu estou! rs
Bom, espero ter atingido meu objetivo e, pelo menos, motivado você a também estudar o assunto. Deixei vários links ao longo do texto e nas referências para te ajudar a entender melhor do que estamos falando.
Fique à vontade e comente o que achou aqui em baixo e se você souber como posso melhorar a precisão dos modelos usados, será de grande ajuda!
Referências
- http://www.andreykurenkov.com/writing/organizing-my-emails-with-a-neural-net/
- http://machinelearningmastery.com/multi-class-classification-tutorial-keras-deep-learning-library/
- http://scikit-learn.org/stable/tutorial/text_analytics/working_with_text_data.html
- http://scikit-learn.org/stable/auto_examples/text/document_classification_20newsgroups.html
- http://nbviewer.jupyter.org/github/jmportilla/Udemy—Machine-Learning/blob/master/Multi-Class%20Classification.ipynb

De 0 a 10, o quanto você recomendaria este artigo para um amigo?