



Brincando de Big Data e Data Mining
No seguinte artigo, o autor apresenta três experimentos nos quais ele avalia o quão rápido conseguimos processar gigabytes de dados, comparando diferentes linguagens.

Olá pessoal, tudo bem?
Hoje quero compartilhar uma brincadeira experimento que fiz relacionado ao que podemos chamar de Big Data e Data Mining. Vamos ver o quão rápido conseguimos processar alguns gigabytes de dados!
Update: Meu amigo Wesley Carvalho preparou um projeto usando Pentaho Data Integration (ou Kettle) para avaliarmos a performance, junto aos outros exemplos deste artigo! Veja os resultados no experimento 3!
Antes de começar, vamos ver o que a Wikipedia pode nos dizer sobre Big Data e Data Mining:
Big Data is a term for data sets that are so large or complex, that traditional data processing application software is inadequate to deal with them. [Wikipedia en]
—
Data mining is the computing process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. [Wikipedia en]
Sem perder muito tempo em definições, vamos seguir para as premissas deste experimento.
Pelo que vimos na Wikipedia, precisamos de um grande volume de dados (de preferência complexos) para podermos processar, extrair padrões e reorganizar. Acredito que os exemplos perfeitos sejam arquivos de log! Uma aplicação web, por exemplo, é capaz de gerar um volume interessante de dados padronizados mas não estruturados em formato de logs.
Vou usar neste experimento logs de uma aplicação web servida pelo Apache que segue o seguinte formato (consulte a tabela Custom Log Formats da documentação do Apache para entender):
LogFormat "%h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" combined
Este é um exemplo de uma entrada de log no formato acima:
192.168.0.1 - - [28/Sep/2016:22:20:27 +0000] "GET /path/ HTTP/1.1" 200 4696 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0 Safari/537.36"
Infelizmente não posso disponibilizar os arquivos de log que usei para download, mas você pode usar seus próprios logs ou baixar logs da NASA, por exemplo.
Vamos aos experimentos!
Experimento 1 – Processamento Síncrono
Obs: Todo o código esta disponível no Github!
O primeiro experimento, com scripts em Python e Go, faz a extração de dados de aquivos de log e a inserção dos dados em um banco de dados NoSQL (ArangoDB). O ArangoDB foi o escolhido, entre outros motivos, pela ótima performance e por disponibilizar uma interface web onde podemos acompanhar algumas métricas interessantes para o experimento.
As premissas para este experimento foram:
- Fazer a extração dos dados sem usar regex
- Fazer a inserção dos dados em lotes de 2000 registros
- Executar de forma síncrona
O uso de regex para a extração dos dados foi testada com o uso da lib apache_log_parser, mas não apresentou boa performance e, por isso, foi descartada.
Operações em lote (ou bulk) são normalmente usadas para acelerar o processo de inserção de dados. Neste caso, cheguei ao numero 2000 após alguns testes (500, 1000 e 2000), onde o melhor resultado (mais rápido) foi o lote de 2 mil registros.
Os testes foram feitos usando CPython (Python 3.5), PyPy2.7 (v5.8.0) e Go (v1.8.3). Todos os testes rodaram no mesmo ambiente:
- Hardware: Notebook dell core i7-6500U 2.50GHz, 16G RAM
- Sistema operacional: Ubuntu 14.04 LTS 64-bit
- Banco de dados: ArangoDB 3.2.1 local
A massa de dados consiste em 100 arquivos de log no formato texto, num total de 2,4GB de dados (2402 mega).
Os tempos de execução foram obtidos com o comando time do sistema operacional. Os resultados foram:
| Engine | Tempo de Exc | Total de registros no BD |
| CPython | 3:50 min | 10.560.341 |
| PyPy | 2:41 min | 10.560.341 |
| Go | 4:25 min | 10.560.341 |
Abaixo, está o painel de controle do ArangoDB, onde é possível ver as taxas de requisições por segundo e de transferência de dados por segundo:
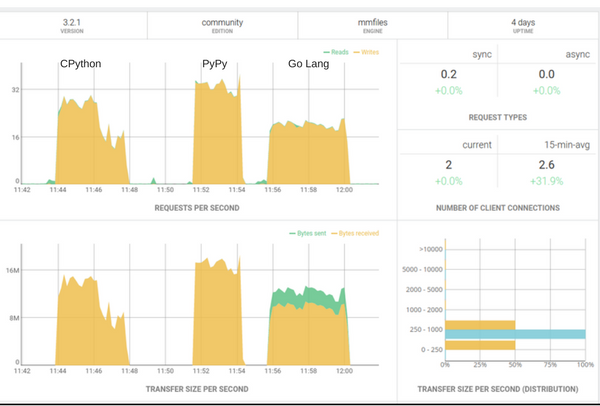
Dentre os três testes, o PyPy foi o que conseguiu as melhores taxas de requisição e transferência por segundo, o que foi uma surpresa, apesar de haver uma observação muito importante sobre Go no final do artigo!
PyPy, em resumo, é uma implementação alternativa da linguagem Python com foco em desempenho. Saiba mais na Wikipedia!
Já neste experimento, com processamento síncrono, conseguimos bons resultados. Foram mais de 10 milhões de registros extraídos dos arquivos de log e inseridos no banco em menos de três minutos no melhor dos casos! Isso nos dá uma estimativa de aproximadamente 200 milhões de registros inseridos no banco em uma hora de processamento!
Experimento 2 – Processamento Assíncrono
Obs: O código esta disponível no Github!
Após divulgar os primeiros resultados e receber sugestões para usar goroutines para melhorar o desempenho do código Go, foram criadas novas versões dos scripts, agora para processar os dados paralelamente.
As premissas para este experimento foram:
- Fazer a extração dos dados sem usar regex
- Fazer a inserção dos dados em lotes de 2000 registros
- Executar de forma paralela.
Todas as versões dos softwares usados foram mantidas, os dados usados foram os mesmos, o ambiente do teste é o mesmo, só havendo alteração no código.
No script Go foi usado goroutines, como mencionado anteriormente, para tornar o processamento paralelo e, durante a execução, foi possível perceber como o processador foi melhor utilizado!
No script em Python foi usada a classe ProcessPoolExecutor do pacote concurrent.futures para atender a premissa de execução paralela e não apenas concorrente.
Os tempos de execução na versão paralela foram obtidos com o time, como anteriormente. Os resultados foram:
| Engine | Tempo de Exc | Total de registros no BD |
| CPython | 2:15 min | 10.560.341 |
| PyPy | 1:51 min | 10.560.341 |
| Go | 2:26 min | 10.560.341 |
Novamente podemos ver o painel de controle do ArangoDB onde notamos que a quantidade de requests por segundo e a taxa de transferência tiveram um aumento considerável.
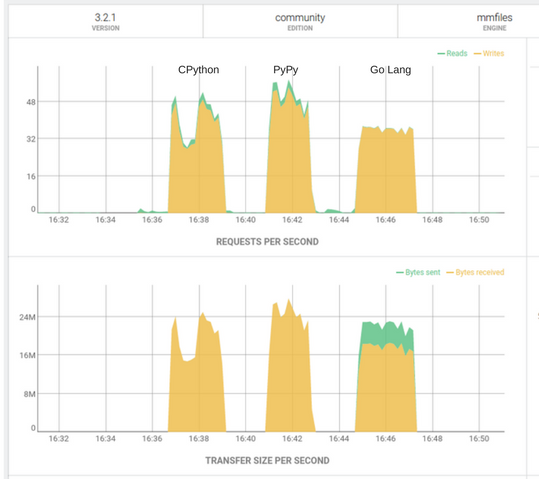
O PyPy continuou com a vantagem nos testes feitos com paralelismo. Podemos ver que ele conseguiu as melhores taxas de requisição por segundo e transferência por segundo.
Conseguimos reduzir nosso melhor tempo em quase 1 min (de 2:41 para 1:51). Pode não parecer muito expressivo, mas em nossa estimativa de 1 hora de processamento, esta redução representa um acréscimo de 100 milhões de registros, ou 50% a mais que a versão síncrona! (de 200 MM para 300 MM).
Update: Experimento 3 – Pentaho Data Integration
Obs: Veja o projeto original no Github do Wesley!
Com a ajuda do Wesley, fiz um novo experimento, agora com o Pentaho Data Integration, uma reconhecida ferramenta de ETL. Abaixo compartilho as premissas do teste e os resultados obtidos.
Caso você se interesse em reproduzir os resultados ou queira fazer um teste com o Pentaho, a instalação e preparação do ambiente foi muito simples. O tutorial usado foi este aqui e o download pode ser feito aqui!
As premissas para este experimento foram:
- Fazer a extração, processamento e carga dos dados no ArangoDB com o PDI
- Fazer a inserção dos dados em lotes de 2000 registros
- Executar de forma paralela
Todas as versões dos softwares usados foram mantidas, os dados usados foram os mesmos, o ambiente do teste é o mesmo, só havendo alteração no processamento dos dados que agora é feito com o PDI.
| Engine | Tempo de exc | Total de registros no BD |
| CPython | 2:15 min | 10.560.341 |
| PyPy | 1:51 min | 10.560.341 |
| Go | 2:26 min | 10.560.341 |
| PDI | 3:13 min | 10.560.341 |
Abaixo, está mais um print do painel de controle do ArangoDB mostrando a quantidade de requisições e dados transferidos por segundo.
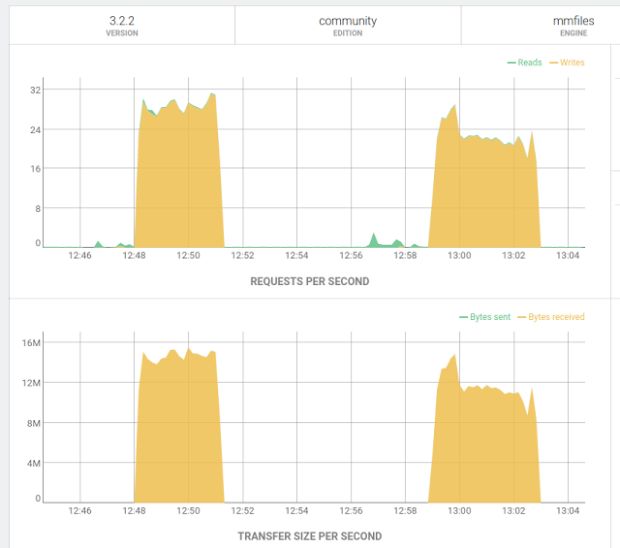
Foram feitas duas tentativas com o PDI e podemos ver que não foram atingidas as mesmas taxas de requisição e transferência de dados por segundo dos outros experimentos. Os dados presentes na tabela de comparação são da primeira tentativa que teve melhor desempenho.
Considerações
Por não ter experiência com a linguagem Go, é quase certo que existem várias oportunidades de otimização no script desta linguagem. O objetivo dos testes feitos com Go era extrapolar as barreiras da linguagem na busca da otimização do experimento.
Sobre o PDI, as impressões foram as melhores! Uma ótima ferramenta, com muitas features e opções, fácil de instalar e executar. Não tenho dúvida que seja uma ótima opção para ETL, muito madura e robusta.
Pelos motivos citados acima, peço que entrem em contato se souberem como otimizar o script em Go (e o script Python também!). Feedbacks são sempre bem vindos!
Um abraço!
é analista de sistemas/desenvolvedor formado pela FATEC-BS e pós-graduado em Engenharia de Software pela PUC-SP. Sócio e co-fundador da StormIdeas, empresa criadora do MailerWeb. Entusiasta de Linux e Python, interessado por tecnologia em geral e vários outros assuntos nerds.


