

Ano passado, no ICML, apresentei um método para tornar a consulta mais rápida usando o algoritmo do vizinho mais próximo. O documento é chamado Cobertura Rápida de Árvores (Faster Cover Trees) e discute algumas melhorias algorítmicas para a estrutura de dados em árvore. Você pode encontrar o código na biblioteca HLearn no GitHub.
A implementação foi escrita inteiramente em Haskell, e é o método mais rápido existente para consultas a vizinhos mais próximos em espaços métricos arbitrários (se você quiser uma interface não-Haskell, o repositório vem com um programa autônomo chamado hlearn-allknn para encontrar os vizinhos mais próximos). Neste artigo, eu quero discutir quatro lições aprendidas sobre como usar Haskell para escrever código numérico de alto desempenho. Mas antes de chegarmos a esses detalhes, vamos ver alguns benchmarks.
Benchmarks
A tarefa do benchmark é encontrar o vizinho mais próximo de todos os pontos do conjunto de dados fornecido. Vamos usar os quatro maiores conjuntos de dados no pacote de benchmark mlpack e da distância euclidiana (HLearn suporta outras métricas de distância, mas a maioria das bibliotecas de comparação não). Você pode encontrar mais detalhes sobre as comparações das bibliotecas e instruções para reproduzir os benchmarks na pasta bench/allknn do repositório.
O tempo de execução para encontrar cada vizinho mais próximo


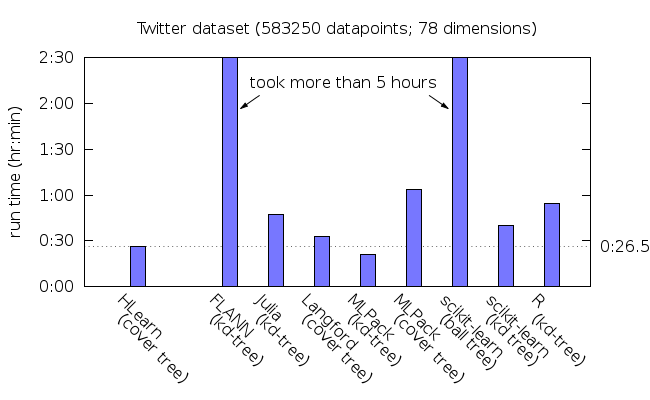

Observe que as coberturas de árvores de HLearn executam mais rápido em cada conjunto de dados, exceto para YearPredict. Mas HLearn pode usar todos os cores no seu computador para paralelizar a tarefa. Veja como o desempenho é proporcional ao número de CPUs em uma instância AWS EC2 c3.8xlarge com 16 cores verdadeiros:

Com paralelismo, HLearn é agora também o mais rápido no conjunto de dados YearPredict por uma margem bem grande. (FLANN é a única outra biblioteca que tem paralelismo, mas, em meus testes, com esse conjunto de dados, paralelismo, na verdade, causou uma redução na velocidade, por algum motivo.)
Você pode encontrar mais referências específicas dos benchmarks no documento Cobertura Rápida de Árvores.
As lições aprendidas
O Wiki Guia do Haskell para desempenho explica as noções básicas de como escrever código rápido. Mas, infelizmente, há muitos detalhes que o wiki não cobre. Então, eu selecionei quatro lições desse projeto que eu acho que resumem o state-of-the-art em codificação Haskell de alta performance.
Lição 1: Código polimórfico em GHC é mais lento do que ele precisa ser.
Haskell faz programação genérica utilizando polimorfismo simples. Minha implementação da cobertura de árvore tira o máximo proveito disso. O tipo CoverTree_ implementa a estrutura de dados que acelera a consulta a vizinhos mais próximos. Ela é definida no módulo HLearn.Data.SpaceTree.CoverTree como:
data CoverTree_
( childC :: * -> * ) -- the container type to store children in
( leafC :: * -> * ) -- the container type to store leaves in
( dp :: * ) -- the type of the data points
= Node
{ nodedp :: !dp
, level :: {-#UNPACK#-}!Int
, nodeWeight :: !(Scalar dp)
, numdp :: !(Scalar dp)
, maxDescendentDistance :: !(Scalar dp)
, children :: !(childC (CoverTree_ childC leafC dp))
, leaves :: !(leafC dp)
}
Observe que todos os campos, exceto para o nível, é polimórfico. O equivalente em struct C++ (usando modelos kinded superiores) ficaria assim:
template < template <typename> typename childC
, template <typename> typename leafC
, typename dp
>
struct CoverTree_
{
dp *nodedp;
int level;
dp::Scalar *nodeWeight;
dp::Scalar *numdp;
dp::Scalar *maxDescendentDistance;
childC<CoverTree_<childC,leafC,dp>> *children;
leafC<dp> *leaves;
}
Observe todos esses ponteiros desagradáveis no código C++ acima. Esses ponteiros destroem o desempenho do cache por duas razões. Em primeiro lugar, os ponteiros ocupam uma quantidade significativa da memória. Essa memória enche o cache, bloqueando os dados que realmente são importantes de entrarem no cache. Em segundo lugar, a memória a que esses ponteiros referenciam pode estar em posições arbitrárias. Isso faz com que o prefetcher da CPU possa carregar os dados errados em cache.
A solução para tornar o código C++ mais rápido é óbvia: remover os ponteiros. Na terminologia Haskell, nós chamamos isso de desembalar os campos do construtor Node. Infelizmente, devido a um bug no GHC (veja issues #3990 e #7647 e uma discussão no reddit), esses campos polimórficos não podem ser desempacotados. Em princípio, o polimorfismo do GHC pode ser feito em uma abstração custo zero, semelhante a modelos em C++; mas isso ainda não existe na prática.
Como um quebra galho, HLearn fornece uma variante da árvore de cobertura, especializada em trabalhar com vetores desempacotados. Ela é definida no módulo HLearn.Data.SpaceTree.CoverTree_Specialized como:
data CoverTree_
( childC :: * -> * ) -- must be set to: BArray
( leafC :: * -> * ) -- must be set to: UArray
( dp :: * ) -- must be set to: Labaled' (UVector "dyn" Float) Int
= Node
{ nodedp :: {-#UNPACK#-}!(Labeled' (UVector "dyn" Float) Int)
, nodeWeight :: {-#UNPACK#-}!Float
, level :: {-#UNPACK#-}!Int
, numdp :: {-#UNPACK#-}!Float
, maxDescendentDistance :: {-#UNPACK#-}!Float
, children :: {-#UNPACK#-}!(BArray (CoverTree_ exprat childC leafC dp))
, leaves :: {-#UNPACK#-}!(UArray dp)
}
Desde que o construtor Node não tenha mais campos polimórficos, todos os seus campos podem ser desempacotados. O programa hlearn-allknn importa esse tipo de árvore de cobertura especializada, dando um aumento de velocidade de 10-30%, dependendo do conjunto de dados. É uma pena ter que manter duas versões diferentes do mesmo código para obter esse aumento de velocidade.
Lição 2: Código de alta performance em Haskell deve ser escrito para versões específicas do GHC.
Porque o código Haskell é de tão alto nível, ele requer otimizações agressivas no compilador para um bom desempenho. Normalmente, GHC combinado com LLVM faz um trabalho incrível com essas otimizações. Mas em código complexo, às vezes essas otimizações não são aplicadas quando você as espera. Pior ainda, diferentes versões do GHC aplicam essas otimizações de forma diferente. E o pior de tudo, depurar problemas relacionados ao otimizador do GHC é difícil.
Descobri isso há alguns meses, quando o GHC 7.10 foi liberado. Eu decidi atualizar a base de código do HLearn para tirar proveito dos recursos do novo compilador. Essa atualização causou uma série de regressões de desempenho que levaram cerca de uma semana para corrigir. O exemplo mais degenerativo aconteceu na função findNeighbor localizada no módulo HLearn.Data.SpaceTree.Algorithms. O circuito interno dessa função se parece com:
go (Labeled' t dist) (Neighbor n distn) = if dist*ε > maxdist
then Neighbor n distn
else inline foldr' go leafres
$ sortBy (\(Labeled' _ d1) (Labeled' _ d2) -> compare d2 d1)
$ map (\t' -> Labeled' t' (distanceUB q (stNode t') (distnleaf+stMaxDescendentDistance t)))
$ toList
$ stChildren t
where
leafres@(Neighbor _ distnleaf) = inline foldr'
(\dp n@(Neighbor _ distn') -> cata dp (distanceUB q dp distn') n)
(cata (stNode t) dist (Neighbor n distn))
(stLeaves t)
maxdist = distn+stMaxDescendentDistance t
Para os nossos propósitos atuais, o mais importante a se notar é que go contém duas chamadas para foldr’: uma dobra sobre childC do CoverTree_, e uma sobre o leafC. No GHC 7.8, isso não foi um problema. O compilador ajustou corretamente ambas as funções com o tipo de container certo, resultando em um código rápido.
Mas, por alguma razão, o GHC 7.10 não queria se ajustar a essas funções. Ele decidiu passar por dicionários de classe enormes para cada chamada de função, que é uma causa conhecida para código Haskell lento. No meu caso, isso resultou em queda de mais de 20 vezes no desempenho! Encontrar a causa dessa degeneração foi um exercício doloroso de leitura do core intermediário da linguagem GHC. Os tutoriais típicos sobre core de depuração usam exemplos triviais, de apenas uma dúzia de linhas de código do core. Mas, no meu caso, o core do programa hlearn-allknn tinha várias centenas de milhares de linhas. Decifrar esse core para encontrar a causa da degradação foi uma das minhas experiências mais dolorosas com Haskell. Uma ferramenta que analisasse o core para encontrar chamadas de função que contêm chamadas excessivas para dicionário facilitaria muito a escrita de código de alta performance em Haskell.
Uma vez encontrada a causa da degradação, o ajuste foi trivial. Tudo que eu tinha a fazer era chamar a função inline em ambas as chamadas para foldr. Na minha experiência, esse é um tema recorrente em escrever código de alto desempenho no Haskell: encontrar a causa dos problemas é difícil, mas corrigi-los é fácil.
Lição 3: Imutabilidade e lentidão podem fazer o código numérico ser mais rápido.
O conselho padrão para escrever código numérico em Haskell é evitar a lentidão. Isso geralmente é verdade, mas eu quero dar um exemplo contraditório bem interessante.
Esta lição é relacionada com a mesma função go acima, e mais diretamente a com chamada para sortBy. sortBy é uma função padrão do Haskell que usa um lazy merge sort. Lazy merge sort é um algoritmo lento, tipicamente 10 vezes mais lento do que o quicksort local. A análise do hlearn-allknn mostra que a parte mais cara da busca do vizinho mais próximo está no calculo de distâncias (consumindo cerca de 80% do tempo de execução), e a segunda parte mais cara é a chamada para sortBy (consumindo cerca de 10% do tempo de execução). Mas eu, no entanto, afirmo que esse lazy merge sort está fazendo consultas a vizinhos mais próximos da HLearn muito mais rápido devido à sua imutabilidade e sua lentidão.
Vamos começar com a imutabilidade, uma vez que é bastante direta. Imutabilidade faz paralelismo com facilidade e rapidez, porque não há necessidade de threads separadas para colocar bloqueios em qualquer um dos containers.
A lentidão é um pouco mais complicada. Se a explicação abaixo não fizer sentido, a leitura da seção 2 do documento onde eu discuto como funciona uma árvore de cobertura pode ajudar. Vamos dizer que nós estamos tentando encontrar o vizinho mais próximo de um ponto de dados que nós chamaremos de q. Podemos primeiro classificar children de acordo com sua distância do q e, em seguida, olhar para os vizinhos mais próximos nas children classificadas. A chave para o desempenho da árvore de cobertura é que não temos que olhar em todas as sub-árvores. Se pudermos provar que uma sub-árvore nunca vai conter um ponto mais perto do que um ponto q já encontrado, então nós podemos “podar” essa sub-árvore. Por causa da poda, geralmente não iremos descer em cada child. Assim, a triagem de todo o container de children é um desperdício de tempo, só devemos classificar as que realmente visitarmos. A lazy sort nos dá essa propriedade de graça! E é por isso que o lazy merge sort é mais rápido do que uma classificação quick sort local para essa aplicação.
Lição 4: Bibliotecas padrão do Haskell não foram projetadas para computação numérica rápida.
Ao desenvolver essa implementação de cobertura de árvore, eu encontrei muitas limitações nas bibliotecas padrão do Haskell. Para contornar essas limitações, eu criei uma biblioteca alternativa chamada SubHask. Eu tenho muito a dizer sobre essas limitações, mas aqui eu vou me restringir ao ponto mais importante para consultas a vizinhos mais próximos: SubHask permite criar com segurança arrays desempacotados de vetores desempacotados, mas a biblioteca padrão, não. (Containers desempacotados, como o UNPACK pragma mencionado acima, nos permite evitar a sobrecarga de indireções causadas pelo tempo de execução do Haskell. O wiki do Haskell tem uma boa explicação a respeito.) Em minhas experiências, essa otimização simples, permite reduzir erros de cache em cerca de 30%, fazendo com que o programa seja executado duas vezes mais rápido!
A distinção entre um array e um vetor é importante no SubHask – arrays são containers genéricos, e vetores são elementos de um espaço vetorial. Essa distinção é o que permite SubHask desempacotar com segurança os vetores. Deixa eu explicar:
No SubHask, arrays desempacotados são representados usando o tipo UArray :: * -> * no SubHask.Algebra.Array. Por exemplo, UArray Int é do tipo array de inteiros descompactado. Arrays podem ter comprimento arbitrário, e isso torna impossível empacotar um array desempacotado. Vetores, por outro lado, têm obrigatoriamente uma dimensão fixa. Vetores desempacotados com o SubHask são representados usando o tipo UVector :: k -> * -> * no SubHask.Algebra.Vector. O primeiro tipo de parâmetro k é um tipo fantasma que especifica a dimensão do vetor. Assim, um vetor de floats com 20 dimensões pode ser representado usando o tipo UVector 20 Float. Mas muitas vezes o tamanho de um vetor não é conhecido em tempo de compilação. Nesse caso, o SubHask permite que você use uma string para identificar a dimensão do vetor. Em hlearn-allknn, os data points são representados usando o tipo Vector “dyn” Float. O compilador, então, estaticamente garante que cada variável do tipo UVector “dyn” Float tenha a mesma dimensão. Esse truque é o que nos permite criar o tipo UArray (Vector “dyn” Float).
O programa hlearn-allknn explora esse desempacotamento, definindo o parâmetro leafC do CoverTree_ para UArray. Em seguida, chamamos a função packCT que reorganiza os nós em leafC para usar o layout de árvore cache oblivios van Embde Boas. Desempacotamento por si só dá um modesto 5% de ganho de desempenho no sistema de tempo de execução em Haskell; mas desempacotar combinando com esse reajuste de dados reduz o tempo de execução pela metade!
Infelizmente, devido a algumas limitações atuais do GHC, eu ainda estou deixando algum desempenho para trás. O parâmetro childC do CoverTree_ não pode ser UArray porque CoverTree_ pode ter um tamanho variável, dependendo do número de children. Portanto, childC é normalmente definido para o tipo de array BArray empacotado. A limitação do GHC é que o sistema de tempo de execução não nos dá nenhum modo de controlar onde os elementos de um BArray estarão na memória. Portanto, nós não conseguimos usar os benefícios do prefetcher da CPU. Eu já propus uma solução que envolve a adição de novos primops ao compilador GHC (veja o pedido de feature #10652). Uma vez que normalmente existem mais elementos dentro do childC do que no leafC sobre qualquer cobertura de árvore, eu estimo que a performance com uma melhor utilização de cache de BArrays seria ainda maior do que o aumento de velocidade relatado acima.
Conclusão
Minha experiência é que Haskell pode ser incrivelmente rápido, mas é preciso muito trabalho para obter essa velocidade. Eu acho que demorou cerca de 10 vezes mais para criar minha cobertura de árvore baseada em Haskell do que teria tomado para criar uma implementação baseada em C. (Eu sou mais ou menos proficiente em cada linguagem.) Além disso, por causa das limitações atuais no GHC que eu indiquei acima, a versão em C seria um pouco mais rápida.
Então, por que eu uso Haskell? Para fazer com que as coberturas de árvores sejam 10 vezes mais fáceis para os programadores usarem.
Cobertura de árvores podem fazer com que quase todos os algoritmos de machine learning fiquem mais rápidos. Por exemplo, eles aceleraram SVMs, clustering, dimensionality reduction e reinforcement learning. Mas a maioria das bibliotecas não aproveita essa otimização, porque é relativamente demorado para um programador fazer à mão. Felizmente, as técnicas fundamentais são fáceis o suficiente para que possam ser implementadas como um passo de otimização do compilador, e o Haskell tem um ótimo suporte para as bibliotecas que implementam suas próprias otimizações. Muito em breve, espero mostrar como cobertura de árvores pode acelerar a sua machine learning baseada em Haskell, sem nenhuma programação envolvida.
***
faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://izbicki.me/blog/fast-nearest-neighbor-queries-in-haskell.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?