



Estatísticas de armas nucleares que utilizem monóides, grupos e módulos em Haskell – Parte 01
Vamos ver que a distribuição categórica e as estimativas de densidade de kernel têm grupo, monóide, e módulo de estruturas algébricas. Vamos explicar o que esta linguagem louca significa. Em seguida, vamos aproveitar essas estruturas para responder de forma eficiente questões estatísticas do mundo real sobre a guerra nuclear.

O Boletim de Cientistas Atômicos acompanha as capacidades nucleares de cada país. Nós vamos usar seus dados para demonstrar a biblioteca Haskell HLearn e a utilidade da álgebra abstrata para a estatística. Para ser mais específico, vamos ver que a distribuição categórica e as estimativas de densidade de kernel têm grupo, monóide, e módulo de estruturas algébricas. Vamos explicar o que esta linguagem louca significa. Em seguida, vamos aproveitar essas estruturas para responder de forma eficiente questões estatísticas do mundo real sobre a guerra nuclear.
Antes de entrar na matemática, precisamos rever os fundamentos da política nuclear.
O Tratado de Não-Proliferação Nuclear (TNP) é o principal tratado que rege as armas nucleares. Basicamente, ele diz que existe cinco países que têm “permissão” para ter armas nucleares: EUA, Reino Unido, França, Rússia e China. “Permissão” está entre aspas porque o tratado prevê que esses países devem, eventualmente, se livrar de suas armas nucleares em algum momento em um o futuro não especificado. Quando outro país, por exemplo, o Irã, assina o TNP, está concordando em não desenvolver armas nucleares. O que recebe em troca é a ajuda dos cinco estados com armas nucleares no desenvolvimento de seus próprios programas nucleares civis (o Irã tem a queixa legítima de que os países ocidentais estão ativamente tentando parar seu programa nuclear civil quando deveriam estar ajudando.)
O Nuclear Notebook acompanha as capacidades nucleares de todos esses países. As estimativas mais atuais são a partir de meados de 2012. Aqui está um resumo:
| Country | Delivery Method | Warhead | Yield (kt) | # Deployed |
| USA | ICBM | W78 | 335 | 250 |
| USA | ICBM | W87 | 300 | 250 |
| USA | SLBM | W76 | 100 | 468 |
| USA | SLBM | W76-1 | 100 | 300 |
| USA | SLBM | W88 | 455 | 384 |
| USA | Bomber | W80 | 150 | 200 |
| USA | Bomber | B61 | 340 | 50 |
| USA | Bomber | B83 | 1200 | 50 |
| UK | SLBM | W76 | 100 | 225 |
| France | SLBM | TN75 | 100 | 150 |
| France | Bomber | TN81 | 300 | 150 |
| Russia | ICBM | RS-20V | 800 | 500 |
| Russia | ICBM | RS-18 | 400 | 288 |
| Russia | ICBM | RS-12M | 800 | 135 |
| Russia | ICBM | RS-12M2 | 800 | 56 |
| Russia | ICBM | RS-12M1 | 800 | 18 |
| Russia | ICBM | RS-24 | 100 | 90 |
| Russia | SLBM | RSM-50 | 50 | 144 |
| Russia | SLBM | RSM-54 | 100 | 384 |
| Russia | Bomber | AS-15 | 200 | 820 |
| China | ICBM | DF-3A | 3300 | 16 |
| China | ICBM | DF-4 | 3300 | 12 |
| China | ICBM | DF-5A | 5000 | 20 |
| China | ICBM | DF-21 | 300 | 60 |
| China | ICBM | DF-31 | 300 | 20 |
| China | ICBM | DF-31A | 300 | 20 |
| China | Bomber | H-6 | 3100 | 20 |
Eu já consolidei todos os dados no arquivo de nukes-list.csv, que iremos analisar neste artigo. Se você quiser experimentar este código para você mesmo (ou a pergunta do dever de casa no final), é preciso fazer o download. Cada linha do arquivo corresponde a uma única ogiva nuclear, não ao método de entrega. Ogivas são as peças que fazem o boom! Bombers, ICBMs, e SSBN / SLBMs são o método de entrega.

Existem três coisas a serem observadas sobre esses dados. Primeiro, são só estimativas baseadas em fontes públicas. Em especial, eles provavelmente superestimam as forças russas nucleares. Outras estimativas são consideravelmente inferiores. Em segundo lugar, eles só serão implantados considerando as ogivas estratégicas. Basicamente, isso significa que as armas nucleares “grandes estão destinadas a outro país”. Existem muito mais ogivas táticas e ogivas em estoque esperando para serem desmontadas. Para simplificar e por essas armas nucleares não afetarem significativamente o planejamento estratégico, não vamos levar em consideração aqui. Finalmente, existem quatro países que não são membros do TNP, mas possuem armas nucleares: Israel, Paquistão, Índia e Coréia do Norte.
Vamos ignorá-los aqui porque seus inventários são relativamente pequenos e a maioria de suas armas não seria considerada estratégica.
Prévias da programação
Agora estamos prontos para iniciar a programação. Primeiro, vamos importar nossas bibliotecas:
>import Control.Lens >import Data.Csv >import qualified Data.Vector as V >import qualified Data.ByteString.Lazy.Char8 as BS > >import HLearn.Algebra >import HLearn.Models.Distributions >import HLearn.Gnuplot.Distributions
Em seguida, nós carregamos os dados usando o pacote Cassava – você não precisa entender como isso funciona.
>main = do > Right rawdata :: IO (Either String [(String, String, String, Int)])
E nós vamos usar o pacote Lens para analisar o arquivo CSV em uma série de variáveis, contendo apenas os valores que queremos – você também não precisa entender isso.
> let list_usa = fmap (\row -> row^._4) $ filter (\row -> (row^._1)=="USA" ) rawdata > let list_uk = fmap (\row -> row^._4) $ filter (\row -> (row^._1)=="UK" ) rawdata > let list_france = fmap (\row -> row^._4) $ filter (\row -> (row^._1)=="France") rawdata > let list_russia = fmap (\row -> row^._4) $ filter (\row -> (row^._1)=="Russia") rawdata > let list_china = fmap (\row -> row^._4) $ filter (\row -> (row^._1)=="China" ) rawdata
NOTA: Tudo que você precisa entender sobre o código acima é o que essas variáveis list_country se parecem. Então, vamos imprimir um:
> putStrLn $ "List of American nuclear weapon sizes = " ++ show list_usa
O que nos dá a saída:
List of American nuclear weapon sizes = fromList [335,335,335,335,335,335,335,335,335,335 ... 1200,1200,1200,1200,1200]
Se quisermos saber quantas armas estão no arsenal americano, podemos pegar o comprimento da lista:
> putStrLn $ "Number of American weapons = " ++ show (length list_usa)
Obtemos que existem 1.951 armas nucleares estratégicas americanas em condições de serem empregadas . Para sabermos o total do poder de fogo nós pegamos a soma da lista:
> putStrLn $ "Explosive power of American weapons = " ++ show (sum list_usa)
Obtemos que os EUA têm 516 megatons de armas nucleares estratégicas em condições de serem empregadas. Isso é o equivalente a 1.033.870.000.000 quilos de TNT.
Para obtermos o número total de armas no mundo, nós concatenamos a lista de armas de cada país e achamos o comprimento.
> let list_all = list_usa ++ list_uk ++ list_france ++ list_russia ++ list_china > putStrLn $ "Number of nukes in the whole world = " ++ show (length list_all)
Ao fazer isso para todos os países, temos a tabela:
| Country | Warheads | Total explosive power (kt) |
| USA | 1,951 | 516,935 |
| UK | 225 | 22,500 |
| France | 300 | 60,000 |
| Russia | 2,435 | 901,000 |
| China | 168 | 284,400 |
| Total | 5,079 | 1,784,835 |
Façamos agora um pouco de álgebra!
Monóides e grupos
Em um artigo anterior, vimos que a distribuição de Gauss forma um grupo. Isto significa que tem todas as propriedades de um elemento monóide vazio (mempty), que representa a distribuição de dados não treinados e uma operação de binário (mappend), que mescla duas distribuições em conjunto – mais um inverso. Este inverso nos permite “subtrair” duas Gaussianas uma da outra.
Acontece que muitas outras distribuições também têm essa propriedade do grupo, por exemplo, a distribuição categórica. Esta distribuição é utilizada para a medição de dados discretos. Basicamente, ele atribui uma probabilidade a cada “rótulo”. No nosso caso, os rótulos são o tamanho da arma nuclear e a probabilidade é a chance de que uma bomba nuclear escolhida aleatoriamente será exatamente tão destrutiva. Treinamos nossa distribuição categórica usando a função train:
> let cat_usa = train list_usa :: Categorical Int Double
Se marcamos essa distribuição, vamos obter um gráfico semelhante a:
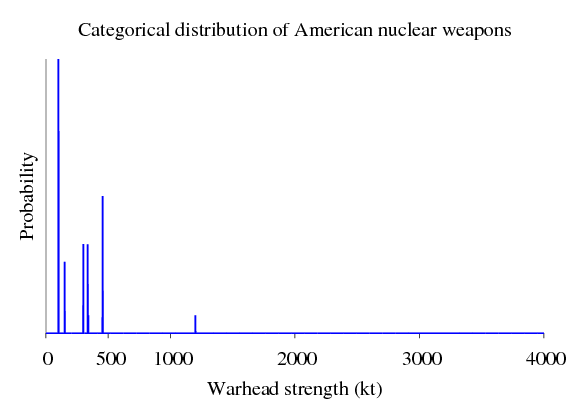
Uma distribuição como esta é útil para os planejadores de guerra de outros países. Ela pode ajudá-los estatisticamente a determinar a quantidade de vítimas.
Agora, vamos treinar distribuições equivalentes para os nossos outros países.
> let cat_uk = train list_uk :: Categorical Int Double > let cat_france = train list_france :: Categorical Int Double > let cat_russia = train list_russia :: Categorical Int Double > let cat_china = train list_china :: Categorical Int Double
Porque treinar a distribuição categórica é um grupo de homomorfismo. Nós podemos treinar uma distribuição sobre todas as armas nucleares por uma formação diretamente nos dados:
> let cat_allA = train list_all :: Categorical Int Double
ou podemos mesclar as distribuições categóricas já geradas:
> let cat_allB = cat_usa <> cat_uk <> cat_france <> cat_russia <> cat_china
Por causa da propriedade do homomorfismo, vamos obter o mesmo resultado em ambos os sentidos. Uma vez que já fizemos os cálculos para cada um dos países, o método B será mais eficiente, pois não terá que repetir o trabalho que já fizemos. Se marcamos uma destas distribuições categóricas, temos:
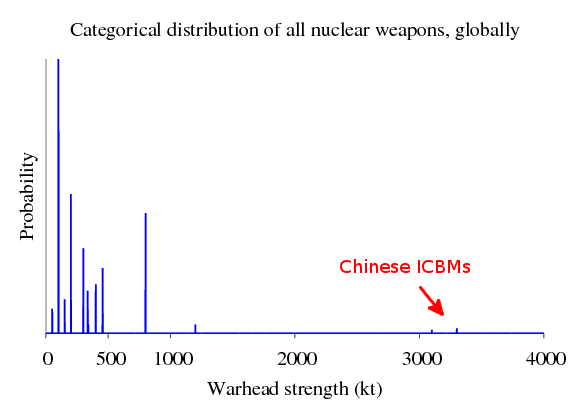
A única coisa para se observar no gráfico é que a maioria dos países tem um arsenal nuclear, que é distribuído igualmente para os Estados Unidos, com exceção da China. Estes mísseis balísticos intercontinentais chineses se tornarão muito mais importante quando nós discutirmos a estratégia nuclear.
Mas os planejadores de guerra nuclear particularmente não se preocupam com esta lista completa das armas nucleares. O que interessa para eles é a capacidade de sobrevivência das armas nucleares, ou seja, armas que não serão destruídas por um ataque nuclear surpresa. Nossas distribuições acima contêm armas nucleares que caiu em bombardeios, mas estes não são de sobrevivência. São fáceis de destruir. Para nossos propósitos, vamos chamar qualquer coisa que não é um bombardeio de uma arma de sobrevivência.

Vamos usar a propriedade do grupo de distribuição categórica para calcular as armas de sobrevivência. Primeiro, criamos uma distribuição de apenas os bombardeios sem possibilidade de sobrevivência:
> let list_bomber = fmap (\row -> row^._4) $ filter (\row -> (row^._2)=="Bomber") rawdata > let cat_bomber = train list_bomber :: Categorical Int Double
Então, usamos o nosso grupo inverso para subtrair essas armas que não sobrevivem:
> let list_bomber = fmap (\row -> row^._4) $ filter (\row -> (row^._2)=="Bomber") rawdata > let cat_bomber = train list_bomber :: Categorical Int Double
Repare que calculamos essa distribuição indireta – não tinha maneira possível de combinar nossas variáveis acima para gerar este valor sem usar o inverso! Este é o poder dos grupos nas estatísticas.
Na próxima semana vou publicar a segunda parte do artigo. Não percam!
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em: http://izbicki.me/blog/nuclear-weapon-statistics-using-monoids-groups-and-modules-in-haskell
É estudante de PHD e professor no departamento de CS na UC Riverside e sua área é fundação algébrica de aprendizado de máquina. Ele foca nos aspectos teóricos do aprendizado e em como aplicar o aprendizado a problemas que reduzem sofrimento e guerra.



